 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrAda: Few-Shot Visual Adaptation for Text-Prompted Segmentation
May 19, 2026Segmenting images is critical for visual understanding but demands extensive pixel-level annotations. Foundational models have enabled new paradigms for predicting new classes guided by textual prompts, without annotations from the target domain. Yet, on specialized target domains, far from the original pre-training, their performance degrades. We study the errors of existing methods under such domain-shift, finding that misclassification rather than mask generation is the main culprit. To address this, we introduce the novel problem of Few-Shot Visual Adaptation for text-prompted Segmentation. This kind of adaptation has been largely studied for image classification, but it remains unexplored for segmentation. We tackle this task with Prototype Adaptation (PrAda), a novel, parameter-efficient method that adapts a frozen text-prompted segmentation model. Our approach learns class-specific prototypes by combining fine-grained pixel features and high-level transformer representations, which are then fused with the original text-based predictions through a learned importance factor. This preserves the model's zero-shot potential while enabling strong adaptation to new domains. Experiments across semantic, instance, and panoptic segmentation on five benchmarks demonstrate that PrAda yields significant improvements over state-of-the-art and proposed baselines.
Road Obstacle Video Segmentation
Sep 16, 2025With the growing deployment of autonomous driving agents, the detection and segmentation of road obstacles have become critical to ensure safe autonomous navigation. However, existing road-obstacle segmentation methods are applied on individual frames, overlooking the temporal nature of the problem, leading to inconsistent prediction maps between consecutive frames. In this work, we demonstrate that the road-obstacle segmentation task is inherently temporal, since the segmentation maps for consecutive frames are strongly correlated. To address this, we curate and adapt four evaluation benchmarks for road-obstacle video segmentation and evaluate 11 state-of-the-art image- and video-based segmentation methods on these benchmarks. Moreover, we introduce two strong baseline methods based on vision foundation models. Our approach establishes a new state-of-the-art in road-obstacle video segmentation for long-range video sequences, providing valuable insights and direction for future research.
Diversity-Driven Learning: Tackling Spurious Correlations and Data Heterogeneity in Federated Models
Apr 15, 2025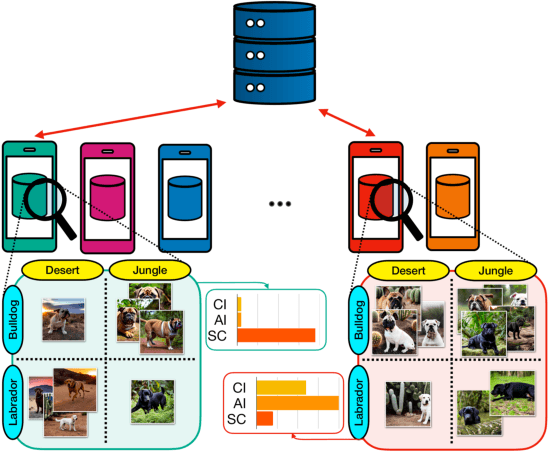

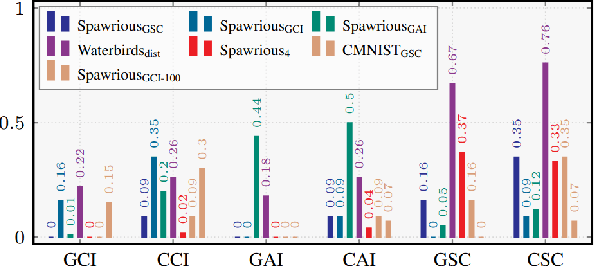
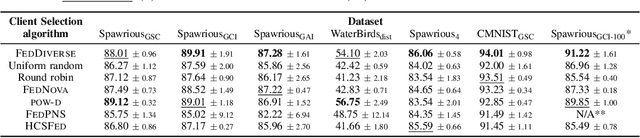
Federated Learning (FL) enables decentralized training of machine learning models on distributed data while preserving privacy. However, in real-world FL settings, client data is often non-identically distributed and imbalanced, resulting in statistical data heterogeneity which impacts the generalization capabilities of the server's model across clients, slows convergence and reduces performance. In this paper, we address this challenge by first proposing a characterization of statistical data heterogeneity by means of 6 metrics of global and client attribute imbalance, class imbalance, and spurious correlations. Next, we create and share 7 computer vision datasets for binary and multiclass image classification tasks in Federated Learning that cover a broad range of statistical data heterogeneity and hence simulate real-world situations. Finally, we propose FedDiverse, a novel client selection algorithm in FL which is designed to manage and leverage data heterogeneity across clients by promoting collaboration between clients with complementary data distributions. Experiments on the seven proposed FL datasets demonstrate FedDiverse's effectiveness in enhancing the performance and robustness of a variety of FL methods while having low communication and computational overhead.
Interaction-Aware Gaussian Weighting for Clustered Federated Learning
Feb 05, 2025



Federated Learning (FL) emerged as a decentralized paradigm to train models while preserving privacy. However, conventional FL struggles with data heterogeneity and class imbalance, which degrade model performance. Clustered FL balances personalization and decentralized training by grouping clients with analogous data distributions, enabling improved accuracy while adhering to privacy constraints. This approach effectively mitigates the adverse impact of heterogeneity in FL. In this work, we propose a novel clustered FL method, FedGWC (Federated Gaussian Weighting Clustering), which groups clients based on their data distribution, allowing training of a more robust and personalized model on the identified clusters. FedGWC identifies homogeneous clusters by transforming individual empirical losses to model client interactions with a Gaussian reward mechanism. Additionally, we introduce the Wasserstein Adjusted Score, a new clustering metric for FL to evaluate cluster cohesion with respect to the individual class distribution. Our experiments on benchmark datasets show that FedGWC outperforms existing FL algorithms in cluster quality and classification accuracy, validating the efficacy of our approach.
Beyond Local Sharpness: Communication-Efficient Global Sharpness-aware Minimization for Federated Learning
Dec 04, 2024



Federated learning (FL) enables collaborative model training with privacy preservation. Data heterogeneity across edge devices (clients) can cause models to converge to sharp minima, negatively impacting generalization and robustness. Recent approaches use client-side sharpness-aware minimization (SAM) to encourage flatter minima, but the discrepancy between local and global loss landscapes often undermines their effectiveness, as optimizing for local sharpness does not ensure global flatness. This work introduces FedGloSS (Federated Global Server-side Sharpness), a novel FL approach that prioritizes the optimization of global sharpness on the server, using SAM. To reduce communication overhead, FedGloSS cleverly approximates sharpness using the previous global gradient, eliminating the need for additional client communication. Our extensive evaluations demonstrate that FedGloSS consistently reaches flatter minima and better performance compared to state-of-the-art FL methods across various federated vision benchmarks.
Egocentric zone-aware action recognition across environments
Sep 21, 2024



Human activities exhibit a strong correlation between actions and the places where these are performed, such as washing something at a sink. More specifically, in daily living environments we may identify particular locations, hereinafter named activity-centric zones, which may afford a set of homogeneous actions. Their knowledge can serve as a prior to favor vision models to recognize human activities. However, the appearance of these zones is scene-specific, limiting the transferability of this prior information to unfamiliar areas and domains. This problem is particularly relevant in egocentric vision, where the environment takes up most of the image, making it even more difficult to separate the action from the context. In this paper, we discuss the importance of decoupling the domain-specific appearance of activity-centric zones from their universal, domain-agnostic representations, and show how the latter can improve the cross-domain transferability of Egocentric Action Recognition (EAR) models. We validate our solution on the EPIC-Kitchens-100 and Argo1M datasets
MeshVPR: Citywide Visual Place Recognition Using 3D Meshes
Jun 04, 2024



Mesh-based scene representation offers a promising direction for simplifying large-scale hierarchical visual localization pipelines, combining a visual place recognition step based on global features (retrieval) and a visual localization step based on local features. While existing work demonstrates the viability of meshes for visual localization, the impact of using synthetic databases rendered from them in visual place recognition remains largely unexplored. In this work we investigate using dense 3D textured meshes for large-scale Visual Place Recognition (VPR) and identify a significant performance drop when using synthetic mesh-based databases compared to real-world images for retrieval. To address this, we propose MeshVPR, a novel VPR pipeline that utilizes a lightweight features alignment framework to bridge the gap between real-world and synthetic domains. MeshVPR leverages pre-trained VPR models and it is efficient and scalable for city-wide deployments. We introduce novel datasets with freely available 3D meshes and manually collected queries from Berlin, Paris, and Melbourne. Extensive evaluations demonstrate that MeshVPR achieves competitive performance with standard VPR pipelines, paving the way for mesh-based localization systems. Our contributions include the new task of citywide mesh-based VPR, the new benchmark datasets, MeshVPR, and a thorough analysis of open challenges. Data, code, and interactive visualizations are available at https://mesh-vpr.github.io
Accelerating Heterogeneous Federated Learning with Closed-form Classifiers
Jun 03, 2024Federated Learning (FL) methods often struggle in highly statistically heterogeneous settings. Indeed, non-IID data distributions cause client drift and biased local solutions, particularly pronounced in the final classification layer, negatively impacting convergence speed and accuracy. To address this issue, we introduce Federated Recursive Ridge Regression (Fed3R). Our method fits a Ridge Regression classifier computed in closed form leveraging pre-trained features. Fed3R is immune to statistical heterogeneity and is invariant to the sampling order of the clients. Therefore, it proves particularly effective in cross-device scenarios. Furthermore, it is fast and efficient in terms of communication and computation costs, requiring up to two orders of magnitude fewer resources than the competitors. Finally, we propose to leverage the Fed3R parameters as an initialization for a softmax classifier and subsequently fine-tune the model using any FL algorithm (Fed3R with Fine-Tuning, Fed3R+FT). Our findings also indicate that maintaining a fixed classifier aids in stabilizing the training and learning more discriminative features in cross-device settings. Official website: https://fed-3r.github.io/.
EarthMatch: Iterative Coregistration for Fine-grained Localization of Astronaut Photography
May 08, 2024Precise, pixel-wise geolocalization of astronaut photography is critical to unlocking the potential of this unique type of remotely sensed Earth data, particularly for its use in disaster management and climate change research. Recent works have established the Astronaut Photography Localization task, but have either proved too costly for mass deployment or generated too coarse a localization. Thus, we present EarthMatch, an iterative homography estimation method that produces fine-grained localization of astronaut photographs while maintaining an emphasis on speed. We refocus the astronaut photography benchmark, AIMS, on the geolocalization task itself, and prove our method's efficacy on this dataset. In addition, we offer a new, fair method for image matcher comparison, and an extensive evaluation of different matching models within our localization pipeline. Our method will enable fast and accurate localization of the 4.5 million and growing collection of astronaut photography of Earth. Webpage with code and data at https://earthloc-and-earthmatch.github.io
The Unreasonable Effectiveness of Pre-Trained Features for Camera Pose Refinement
Apr 16, 2024Pose refinement is an interesting and practically relevant research direction. Pose refinement can be used to (1) obtain a more accurate pose estimate from an initial prior (e.g., from retrieval), (2) as pre-processing, i.e., to provide a better starting point to a more expensive pose estimator, (3) as post-processing of a more accurate localizer. Existing approaches focus on learning features / scene representations for the pose refinement task. This involves training an implicit scene representation or learning features while optimizing a camera pose-based loss. A natural question is whether training specific features / representations is truly necessary or whether similar results can be already achieved with more generic features. In this work, we present a simple approach that combines pre-trained features with a particle filter and a renderable representation of the scene. Despite its simplicity, it achieves state-of-the-art results, demonstrating that one can easily build a pose refiner without the need for specific training. The code is at https://github.com/ga1i13o/mcloc_poseref