 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Pretrained Image Matchers Good Enough for SAR-Optical Satellite Registration?
Apr 14, 2026Cross-modal optical-SAR (Synthetic Aperture Radar) registration is a bottleneck for disaster-response via remote sensing, yet modern image matchers are developed and benchmarked almost exclusively on natural-image domains. We evaluate twenty-four pretrained matcher families--in a zero-shot setting with no fine-tuning or domain adaptation on satellite or SAR data--on SpaceNet9 and two additional cross-modal benchmarks under a deterministic protocol with tiled large-image inference, robust geometric filtering, and tie-point-grounded metrics. Our results reveal asymmetric transfer--matchers with explicit cross-modal training do not uniformly outperform those without it. While XoFTR (trained for visible-thermal matching) and RoMa achieve the lowest reported mean error at $3.0$ px on the labeled SpaceNet9 training scenes, RoMa achieves this without any cross-modal training, and MatchAnything-ELoFTR ($3.4$ px)--trained on synthetic cross-modal pairs--matches closely, suggesting (as a working hypothesis) that foundation-model features (DINOv2) may contribute to modality invariance that partially substitutes for explicit cross-modal supervision. 3D-reconstruction matchers (MASt3R, DUSt3R), which are not designed for traditional 2D image matching, are highly protocol-sensitive and remain fragile under default settings. Deployment protocol choices (geometry model, tile size, inlier gating) shift accuracy by up to $33\times$ for a single matcher, sometimes exceeding the effect of swapping matchers entirely within the evaluated sweep--affine geometry alone reduces mean error from $12.34$ to $9.74$ px. These findings inform both practical deployment of existing matchers and future matcher design for cross-modal satellite registration.
AsymLoc: Towards Asymmetric Feature Matching for Efficient Visual Localization
Apr 10, 2026Precise and real-time visual localization is critical for applications like AR/VR and robotics, especially on resource-constrained edge devices such as smart glasses, where battery life and heat dissipation can be a primary concerns. While many efficient models exist, further reducing compute without sacrificing accuracy is essential for practical deployment. To address this, we propose asymmetric visual localization: a large Teacher model processes pre-mapped database images offline, while a lightweight Student model processes the query image online. This creates a challenge in matching features from two different models without resorting to heavy, learned matchers. We introduce AsymLoc, a novel distillation framework that aligns a Student to its Teacher through a combination of a geometry-driven matching objective and a joint detector-descriptor distillation objective, enabling fast, parameter-less nearest-neighbor matching. Extensive experiments on HPatches, ScanNet, IMC2022, and Aachen show that AsymLoc achieves up to 95% of the teacher's localization accuracy using an order of magnitude smaller models, significantly outperforming existing baselines and establishing a new state-of-the-art efficiency-accuracy trade-off.
A Frame is Worth One Token: Efficient Generative World Modeling with Delta Tokens
Apr 06, 2026Anticipating diverse future states is a central challenge in video world modeling. Discriminative world models produce a deterministic prediction that implicitly averages over possible futures, while existing generative world models remain computationally expensive. Recent work demonstrates that predicting the future in the feature space of a vision foundation model (VFM), rather than a latent space optimized for pixel reconstruction, requires significantly fewer world model parameters. However, most such approaches remain discriminative. In this work, we introduce DeltaTok, a tokenizer that encodes the VFM feature difference between consecutive frames into a single continuous "delta" token, and DeltaWorld, a generative world model operating on these tokens to efficiently generate diverse plausible futures. Delta tokens reduce video from a three-dimensional spatio-temporal representation to a one-dimensional temporal sequence, for example yielding a 1,024x token reduction with 512x512 frames. This compact representation enables tractable multi-hypothesis training, where many futures are generated in parallel and only the best is supervised. At inference, this leads to diverse predictions in a single forward pass. Experiments on dense forecasting tasks demonstrate that DeltaWorld forecasts futures that more closely align with real-world outcomes, while having over 35x fewer parameters and using 2,000x fewer FLOPs than existing generative world models. Code and weights: https://deltatok.github.io.
To Match or Not to Match: Revisiting Image Matching for Reliable Visual Place Recognition
Apr 08, 2025



Visual Place Recognition (VPR) is a critical task in computer vision, traditionally enhanced by re-ranking retrieval results with image matching. However, recent advancements in VPR methods have significantly improved performance, challenging the necessity of re-ranking. In this work, we show that modern retrieval systems often reach a point where re-ranking can degrade results, as current VPR datasets are largely saturated. We propose using image matching as a verification step to assess retrieval confidence, demonstrating that inlier counts can reliably predict when re-ranking is beneficial. Our findings shift the paradigm of retrieval pipelines, offering insights for more robust and adaptive VPR systems.
All You Need to Know About Training Image Retrieval Models
Mar 17, 2025



Image retrieval is the task of finding images in a database that are most similar to a given query image. The performance of an image retrieval pipeline depends on many training-time factors, including the embedding model architecture, loss function, data sampler, mining function, learning rate(s), and batch size. In this work, we run tens of thousands of training runs to understand the effect each of these factors has on retrieval accuracy. We also discover best practices that hold across multiple datasets. The code is available at https://github.com/gmberton/image-retrieval
MegaLoc: One Retrieval to Place Them All
Feb 25, 2025



Retrieving images from the same location as a given query is an important component of multiple computer vision tasks, like Visual Place Recognition, Landmark Retrieval, Visual Localization, 3D reconstruction, and SLAM. However, existing solutions are built to specifically work for one of these tasks, and are known to fail when the requirements slightly change or when they meet out-of-distribution data. In this paper we combine a variety of existing methods, training techniques, and datasets to train a retrieval model, called MegaLoc, that is performant on multiple tasks. We find that MegaLoc (1) achieves state of the art on a large number of Visual Place Recognition datasets, (2) impressive results on common Landmark Retrieval datasets, and (3) sets a new state of the art for Visual Localization on the LaMAR datasets, where we only changed the retrieval method to the existing localization pipeline. The code for MegaLoc is available at https://github.com/gmberton/MegaLoc
AstroLoc: Robust Space to Ground Image Localizer
Feb 10, 2025

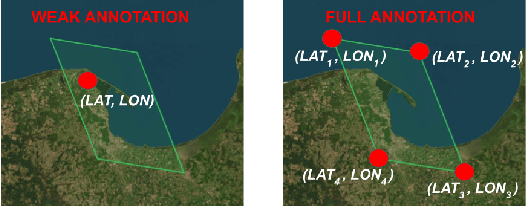

Astronauts take thousands of photos of Earth per day from the International Space Station, which, once localized on Earth's surface, are used for a multitude of tasks, ranging from climate change research to disaster management. The localization process, which has been performed manually for decades, has recently been approached through image retrieval solutions: given an astronaut photo, find its most similar match among a large database of geo-tagged satellite images, in a task called Astronaut Photography Localization (APL). Yet, existing APL approaches are trained only using satellite images, without taking advantage of the millions open-source astronaut photos. In this work we present the first APL pipeline capable of leveraging astronaut photos for training. We first produce full localization information for 300,000 manually weakly labeled astronaut photos through an automated pipeline, and then use these images to train a model, called AstroLoc. AstroLoc learns a robust representation of Earth's surface features through two losses: astronaut photos paired with their matching satellite counterparts in a pairwise loss, and a second loss on clusters of satellite imagery weighted by their relevance to astronaut photography via unsupervised mining. We find that AstroLoc achieves a staggering 35% average improvement in recall@1 over previous SOTA, pushing the limits of existing datasets with a recall@100 consistently over 99%. Finally, we note that AstroLoc, without any fine-tuning, provides excellent results for related tasks like the lost-in-space satellite problem and historical space imagery localization.
MeshVPR: Citywide Visual Place Recognition Using 3D Meshes
Jun 04, 2024



Mesh-based scene representation offers a promising direction for simplifying large-scale hierarchical visual localization pipelines, combining a visual place recognition step based on global features (retrieval) and a visual localization step based on local features. While existing work demonstrates the viability of meshes for visual localization, the impact of using synthetic databases rendered from them in visual place recognition remains largely unexplored. In this work we investigate using dense 3D textured meshes for large-scale Visual Place Recognition (VPR) and identify a significant performance drop when using synthetic mesh-based databases compared to real-world images for retrieval. To address this, we propose MeshVPR, a novel VPR pipeline that utilizes a lightweight features alignment framework to bridge the gap between real-world and synthetic domains. MeshVPR leverages pre-trained VPR models and it is efficient and scalable for city-wide deployments. We introduce novel datasets with freely available 3D meshes and manually collected queries from Berlin, Paris, and Melbourne. Extensive evaluations demonstrate that MeshVPR achieves competitive performance with standard VPR pipelines, paving the way for mesh-based localization systems. Our contributions include the new task of citywide mesh-based VPR, the new benchmark datasets, MeshVPR, and a thorough analysis of open challenges. Data, code, and interactive visualizations are available at https://mesh-vpr.github.io
Scale-Free Image Keypoints Using Differentiable Persistent Homology
Jun 03, 2024



In computer vision, keypoint detection is a fundamental task, with applications spanning from robotics to image retrieval; however, existing learning-based methods suffer from scale dependency and lack flexibility. This paper introduces a novel approach that leverages Morse theory and persistent homology, powerful tools rooted in algebraic topology. We propose a novel loss function based on the recent introduction of a notion of subgradient in persistent homology, paving the way toward topological learning. Our detector, MorseDet, is the first topology-based learning model for feature detection, which achieves competitive performance in keypoint repeatability and introduces a principled and theoretically robust approach to the problem.
EarthMatch: Iterative Coregistration for Fine-grained Localization of Astronaut Photography
May 08, 2024Precise, pixel-wise geolocalization of astronaut photography is critical to unlocking the potential of this unique type of remotely sensed Earth data, particularly for its use in disaster management and climate change research. Recent works have established the Astronaut Photography Localization task, but have either proved too costly for mass deployment or generated too coarse a localization. Thus, we present EarthMatch, an iterative homography estimation method that produces fine-grained localization of astronaut photographs while maintaining an emphasis on speed. We refocus the astronaut photography benchmark, AIMS, on the geolocalization task itself, and prove our method's efficacy on this dataset. In addition, we offer a new, fair method for image matcher comparison, and an extensive evaluation of different matching models within our localization pipeline. Our method will enable fast and accurate localization of the 4.5 million and growing collection of astronaut photography of Earth. Webpage with code and data at https://earthloc-and-earthmatch.github.io