 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoad Obstacle Video Segmentation
Sep 16, 2025With the growing deployment of autonomous driving agents, the detection and segmentation of road obstacles have become critical to ensure safe autonomous navigation. However, existing road-obstacle segmentation methods are applied on individual frames, overlooking the temporal nature of the problem, leading to inconsistent prediction maps between consecutive frames. In this work, we demonstrate that the road-obstacle segmentation task is inherently temporal, since the segmentation maps for consecutive frames are strongly correlated. To address this, we curate and adapt four evaluation benchmarks for road-obstacle video segmentation and evaluate 11 state-of-the-art image- and video-based segmentation methods on these benchmarks. Moreover, we introduce two strong baseline methods based on vision foundation models. Our approach establishes a new state-of-the-art in road-obstacle video segmentation for long-range video sequences, providing valuable insights and direction for future research.
SANSA: Unleashing the Hidden Semantics in SAM2 for Few-Shot Segmentation
May 27, 2025Few-shot segmentation aims to segment unseen object categories from just a handful of annotated examples. This requires mechanisms that can both identify semantically related objects across images and accurately produce segmentation masks. We note that Segment Anything 2 (SAM2), with its prompt-and-propagate mechanism, offers both strong segmentation capabilities and a built-in feature matching process. However, we show that its representations are entangled with task-specific cues optimized for object tracking, which impairs its use for tasks requiring higher level semantic understanding. Our key insight is that, despite its class-agnostic pretraining, SAM2 already encodes rich semantic structure in its features. We propose SANSA (Semantically AligNed Segment Anything 2), a framework that makes this latent structure explicit, and repurposes SAM2 for few-shot segmentation through minimal task-specific modifications. SANSA achieves state-of-the-art performance on few-shot segmentation benchmarks specifically designed to assess generalization, outperforms generalist methods in the popular in-context setting, supports various prompts flexible interaction via points, boxes, or scribbles, and remains significantly faster and more compact than prior approaches. Code is available at https://github.com/ClaudiaCuttano/SANSA.
To Match or Not to Match: Revisiting Image Matching for Reliable Visual Place Recognition
Apr 08, 2025



Visual Place Recognition (VPR) is a critical task in computer vision, traditionally enhanced by re-ranking retrieval results with image matching. However, recent advancements in VPR methods have significantly improved performance, challenging the necessity of re-ranking. In this work, we show that modern retrieval systems often reach a point where re-ranking can degrade results, as current VPR datasets are largely saturated. We propose using image matching as a verification step to assess retrieval confidence, demonstrating that inlier counts can reliably predict when re-ranking is beneficial. Our findings shift the paradigm of retrieval pipelines, offering insights for more robust and adaptive VPR systems.
All You Need to Know About Training Image Retrieval Models
Mar 17, 2025



Image retrieval is the task of finding images in a database that are most similar to a given query image. The performance of an image retrieval pipeline depends on many training-time factors, including the embedding model architecture, loss function, data sampler, mining function, learning rate(s), and batch size. In this work, we run tens of thousands of training runs to understand the effect each of these factors has on retrieval accuracy. We also discover best practices that hold across multiple datasets. The code is available at https://github.com/gmberton/image-retrieval
MegaLoc: One Retrieval to Place Them All
Feb 25, 2025



Retrieving images from the same location as a given query is an important component of multiple computer vision tasks, like Visual Place Recognition, Landmark Retrieval, Visual Localization, 3D reconstruction, and SLAM. However, existing solutions are built to specifically work for one of these tasks, and are known to fail when the requirements slightly change or when they meet out-of-distribution data. In this paper we combine a variety of existing methods, training techniques, and datasets to train a retrieval model, called MegaLoc, that is performant on multiple tasks. We find that MegaLoc (1) achieves state of the art on a large number of Visual Place Recognition datasets, (2) impressive results on common Landmark Retrieval datasets, and (3) sets a new state of the art for Visual Localization on the LaMAR datasets, where we only changed the retrieval method to the existing localization pipeline. The code for MegaLoc is available at https://github.com/gmberton/MegaLoc
AstroLoc: Robust Space to Ground Image Localizer
Feb 10, 2025

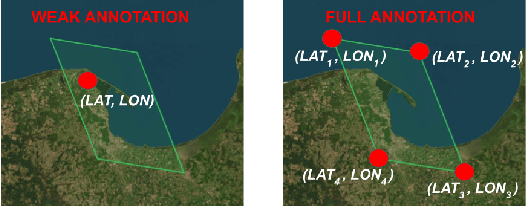

Astronauts take thousands of photos of Earth per day from the International Space Station, which, once localized on Earth's surface, are used for a multitude of tasks, ranging from climate change research to disaster management. The localization process, which has been performed manually for decades, has recently been approached through image retrieval solutions: given an astronaut photo, find its most similar match among a large database of geo-tagged satellite images, in a task called Astronaut Photography Localization (APL). Yet, existing APL approaches are trained only using satellite images, without taking advantage of the millions open-source astronaut photos. In this work we present the first APL pipeline capable of leveraging astronaut photos for training. We first produce full localization information for 300,000 manually weakly labeled astronaut photos through an automated pipeline, and then use these images to train a model, called AstroLoc. AstroLoc learns a robust representation of Earth's surface features through two losses: astronaut photos paired with their matching satellite counterparts in a pairwise loss, and a second loss on clusters of satellite imagery weighted by their relevance to astronaut photography via unsupervised mining. We find that AstroLoc achieves a staggering 35% average improvement in recall@1 over previous SOTA, pushing the limits of existing datasets with a recall@100 consistently over 99%. Finally, we note that AstroLoc, without any fine-tuning, provides excellent results for related tasks like the lost-in-space satellite problem and historical space imagery localization.
SAMWISE: Infusing wisdom in SAM2 for Text-Driven Video Segmentation
Nov 26, 2024



Referring Video Object Segmentation (RVOS) relies on natural language expressions to segment an object in a video clip. Existing methods restrict reasoning either to independent short clips, losing global context, or process the entire video offline, impairing their application in a streaming fashion. In this work, we aim to surpass these limitations and design an RVOS method capable of effectively operating in streaming-like scenarios while retaining contextual information from past frames. We build upon the Segment-Anything 2 (SAM2) model, that provides robust segmentation and tracking capabilities and is naturally suited for streaming processing. We make SAM2 wiser, by empowering it with natural language understanding and explicit temporal modeling at the feature extraction stage, without fine-tuning its weights, and without outsourcing modality interaction to external models. To this end, we introduce a novel adapter module that injects temporal information and multi-modal cues in the feature extraction process. We further reveal the phenomenon of tracking bias in SAM2 and propose a learnable module to adjust its tracking focus when the current frame features suggest a new object more aligned with the caption. Our proposed method, SAMWISE, achieves state-of-the-art across various benchmarks, by adding a negligible overhead of just 4.2 M parameters. The code is available at https://github.com/ClaudiaCuttano/SAMWISE
MeshVPR: Citywide Visual Place Recognition Using 3D Meshes
Jun 04, 2024



Mesh-based scene representation offers a promising direction for simplifying large-scale hierarchical visual localization pipelines, combining a visual place recognition step based on global features (retrieval) and a visual localization step based on local features. While existing work demonstrates the viability of meshes for visual localization, the impact of using synthetic databases rendered from them in visual place recognition remains largely unexplored. In this work we investigate using dense 3D textured meshes for large-scale Visual Place Recognition (VPR) and identify a significant performance drop when using synthetic mesh-based databases compared to real-world images for retrieval. To address this, we propose MeshVPR, a novel VPR pipeline that utilizes a lightweight features alignment framework to bridge the gap between real-world and synthetic domains. MeshVPR leverages pre-trained VPR models and it is efficient and scalable for city-wide deployments. We introduce novel datasets with freely available 3D meshes and manually collected queries from Berlin, Paris, and Melbourne. Extensive evaluations demonstrate that MeshVPR achieves competitive performance with standard VPR pipelines, paving the way for mesh-based localization systems. Our contributions include the new task of citywide mesh-based VPR, the new benchmark datasets, MeshVPR, and a thorough analysis of open challenges. Data, code, and interactive visualizations are available at https://mesh-vpr.github.io
Scale-Free Image Keypoints Using Differentiable Persistent Homology
Jun 03, 2024



In computer vision, keypoint detection is a fundamental task, with applications spanning from robotics to image retrieval; however, existing learning-based methods suffer from scale dependency and lack flexibility. This paper introduces a novel approach that leverages Morse theory and persistent homology, powerful tools rooted in algebraic topology. We propose a novel loss function based on the recent introduction of a notion of subgradient in persistent homology, paving the way toward topological learning. Our detector, MorseDet, is the first topology-based learning model for feature detection, which achieves competitive performance in keypoint repeatability and introduces a principled and theoretically robust approach to the problem.
EarthMatch: Iterative Coregistration for Fine-grained Localization of Astronaut Photography
May 08, 2024Precise, pixel-wise geolocalization of astronaut photography is critical to unlocking the potential of this unique type of remotely sensed Earth data, particularly for its use in disaster management and climate change research. Recent works have established the Astronaut Photography Localization task, but have either proved too costly for mass deployment or generated too coarse a localization. Thus, we present EarthMatch, an iterative homography estimation method that produces fine-grained localization of astronaut photographs while maintaining an emphasis on speed. We refocus the astronaut photography benchmark, AIMS, on the geolocalization task itself, and prove our method's efficacy on this dataset. In addition, we offer a new, fair method for image matcher comparison, and an extensive evaluation of different matching models within our localization pipeline. Our method will enable fast and accurate localization of the 4.5 million and growing collection of astronaut photography of Earth. Webpage with code and data at https://earthloc-and-earthmatch.github.io