 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexRank: Nested Low-Rank Knowledge Decomposition for Adaptive Model Deployment
Feb 02, 2026The growing scale of deep neural networks, encompassing large language models (LLMs) and vision transformers (ViTs), has made training from scratch prohibitively expensive and deployment increasingly costly. These models are often used as computational monoliths with fixed cost, a rigidity that does not leverage overparametrized architectures and largely hinders adaptive deployment across different cost budgets. We argue that importance-ordered nested components can be extracted from pretrained models, and selectively activated on the available computational budget. To this end, our proposed FlexRank method leverages low-rank weight decomposition with nested, importance-based consolidation to extract submodels of increasing capabilities. Our approach enables a "train-once, deploy-everywhere" paradigm that offers a graceful trade-off between cost and performance without training from scratch for each budget - advancing practical deployment of large models.
MeshVPR: Citywide Visual Place Recognition Using 3D Meshes
Jun 04, 2024



Mesh-based scene representation offers a promising direction for simplifying large-scale hierarchical visual localization pipelines, combining a visual place recognition step based on global features (retrieval) and a visual localization step based on local features. While existing work demonstrates the viability of meshes for visual localization, the impact of using synthetic databases rendered from them in visual place recognition remains largely unexplored. In this work we investigate using dense 3D textured meshes for large-scale Visual Place Recognition (VPR) and identify a significant performance drop when using synthetic mesh-based databases compared to real-world images for retrieval. To address this, we propose MeshVPR, a novel VPR pipeline that utilizes a lightweight features alignment framework to bridge the gap between real-world and synthetic domains. MeshVPR leverages pre-trained VPR models and it is efficient and scalable for city-wide deployments. We introduce novel datasets with freely available 3D meshes and manually collected queries from Berlin, Paris, and Melbourne. Extensive evaluations demonstrate that MeshVPR achieves competitive performance with standard VPR pipelines, paving the way for mesh-based localization systems. Our contributions include the new task of citywide mesh-based VPR, the new benchmark datasets, MeshVPR, and a thorough analysis of open challenges. Data, code, and interactive visualizations are available at https://mesh-vpr.github.io
Communication-Efficient Heterogeneous Federated Learning with Generalized Heavy-Ball Momentum
Nov 30, 2023Federated Learning (FL) is the state-of-the-art approach for learning from decentralized data in privacy-constrained scenarios. As the current literature reports, the main problems associated with FL refer to system and statistical challenges: the former ones demand for efficient learning from edge devices, including lowering communication bandwidth and frequency, while the latter require algorithms robust to non-iidness. State-of-art approaches either guarantee convergence at increased communication cost or are not sufficiently robust to handle extreme heterogeneous local distributions. In this work we propose a novel generalization of the heavy-ball momentum, and present FedHBM to effectively address statistical heterogeneity in FL without introducing any communication overhead. We conduct extensive experimentation on common FL vision and NLP datasets, showing that our FedHBM algorithm empirically yields better model quality and higher convergence speed w.r.t. the state-of-art, especially in pathological non-iid scenarios. While being designed for cross-silo settings, we show how FedHBM is applicable in moderate-to-high cross-device scenarios, and how good model initializations (e.g. pre-training) can be exploited for prompt acceleration. Extended experimentation on large-scale real-world federated datasets further corroborates the effectiveness of our approach for real-world FL applications.
Speeding up Heterogeneous Federated Learning with Sequentially Trained Superclients
Jan 26, 2022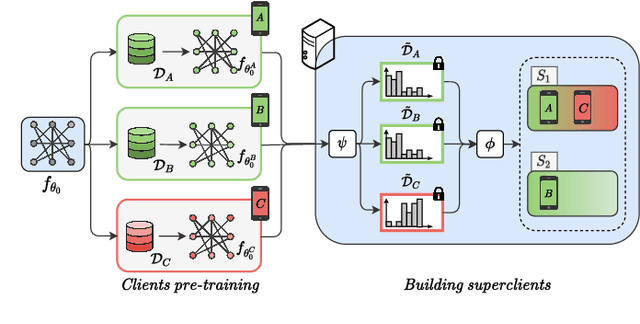
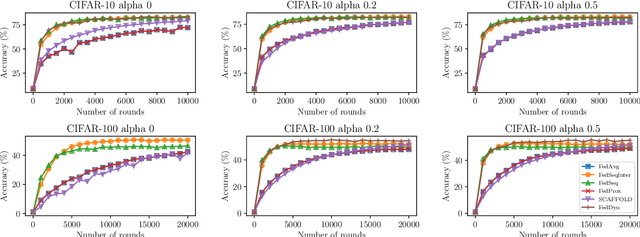
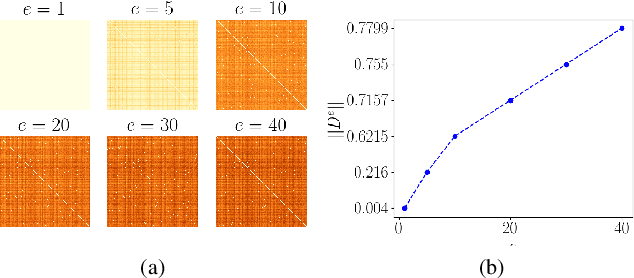

Federated Learning (FL) allows training machine learning models in privacy-constrained scenarios by enabling the cooperation of edge devices without requiring local data sharing. This approach raises several challenges due to the different statistical distribution of the local datasets and the clients' computational heterogeneity. In particular, the presence of highly non-i.i.d. data severely impairs both the performance of the trained neural network and its convergence rate, increasing the number of communication rounds requested to reach a performance comparable to that of the centralized scenario. As a solution, we propose FedSeq, a novel framework leveraging the sequential training of subgroups of heterogeneous clients, i.e. superclients, to emulate the centralized paradigm in a privacy-compliant way. Given a fixed budget of communication rounds, we show that FedSeq outperforms or match several state-of-the-art federated algorithms in terms of final performance and speed of convergence. Finally, our method can be easily integrated with other approaches available in the literature. Empirical results show that combining existing algorithms with FedSeq further improves its final performance and convergence speed. We test our method on CIFAR-10 and CIFAR-100 and prove its effectiveness in both i.i.d. and non-i.i.d. scenarios.