 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Local Sharpness: Communication-Efficient Global Sharpness-aware Minimization for Federated Learning
Dec 04, 2024



Federated learning (FL) enables collaborative model training with privacy preservation. Data heterogeneity across edge devices (clients) can cause models to converge to sharp minima, negatively impacting generalization and robustness. Recent approaches use client-side sharpness-aware minimization (SAM) to encourage flatter minima, but the discrepancy between local and global loss landscapes often undermines their effectiveness, as optimizing for local sharpness does not ensure global flatness. This work introduces FedGloSS (Federated Global Server-side Sharpness), a novel FL approach that prioritizes the optimization of global sharpness on the server, using SAM. To reduce communication overhead, FedGloSS cleverly approximates sharpness using the previous global gradient, eliminating the need for additional client communication. Our extensive evaluations demonstrate that FedGloSS consistently reaches flatter minima and better performance compared to state-of-the-art FL methods across various federated vision benchmarks.
Window-based Model Averaging Improves Generalization in Heterogeneous Federated Learning
Oct 10, 2023Federated Learning (FL) aims to learn a global model from distributed users while protecting their privacy. However, when data are distributed heterogeneously the learning process becomes noisy, unstable, and biased towards the last seen clients' data, slowing down convergence. To address these issues and improve the robustness and generalization capabilities of the global model, we propose WIMA (Window-based Model Averaging). WIMA aggregates global models from different rounds using a window-based approach, effectively capturing knowledge from multiple users and reducing the bias from the last ones. By adopting a windowed view on the rounds, WIMA can be applied from the initial stages of training. Importantly, our method introduces no additional communication or client-side computation overhead. Our experiments demonstrate the robustness of WIMA against distribution shifts and bad client sampling, resulting in smoother and more stable learning trends. Additionally, WIMA can be easily integrated with state-of-the-art algorithms. We extensively evaluate our approach on standard FL benchmarks, demonstrating its effectiveness.
Learning Across Domains and Devices: Style-Driven Source-Free Domain Adaptation in Clustered Federated Learning
Oct 05, 2022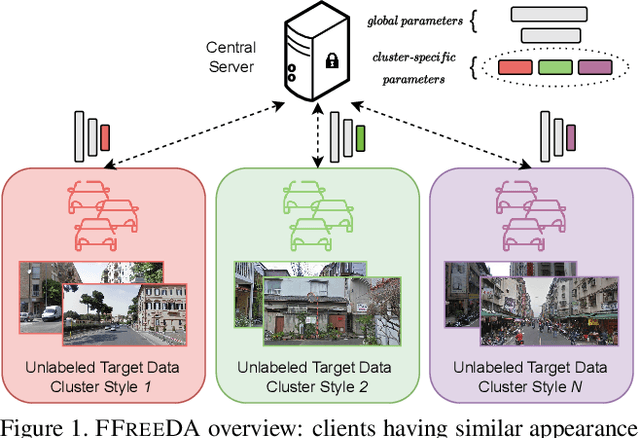
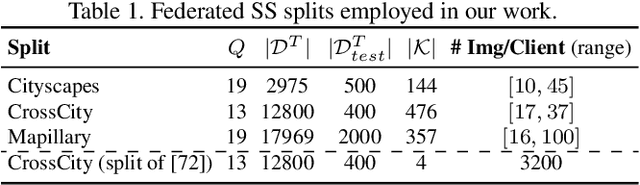
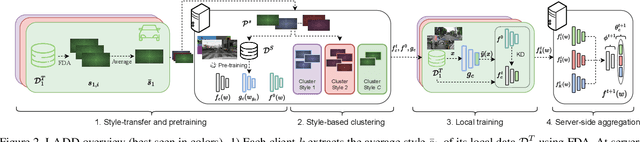
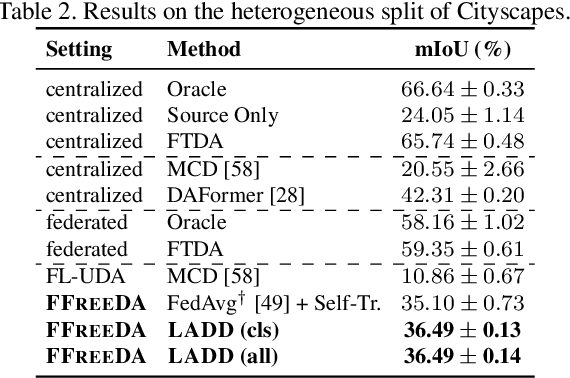
Federated Learning (FL) has recently emerged as a possible way to tackle the domain shift in real-world Semantic Segmentation (SS) without compromising the private nature of the collected data. However, most of the existing works on FL unrealistically assume labeled data in the remote clients. Here we propose a novel task (FFREEDA) in which the clients' data is unlabeled and the server accesses a source labeled dataset for pre-training only. To solve FFREEDA, we propose LADD, which leverages the knowledge of the pre-trained model by employing self-supervision with ad-hoc regularization techniques for local training and introducing a novel federated clustered aggregation scheme based on the clients' style. Our experiments show that our algorithm is able to efficiently tackle the new task outperforming existing approaches. The code is available at https://github.com/Erosinho13/LADD.
Improving Generalization in Federated Learning by Seeking Flat Minima
Mar 24, 2022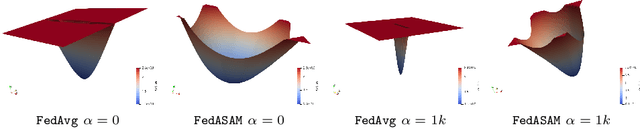
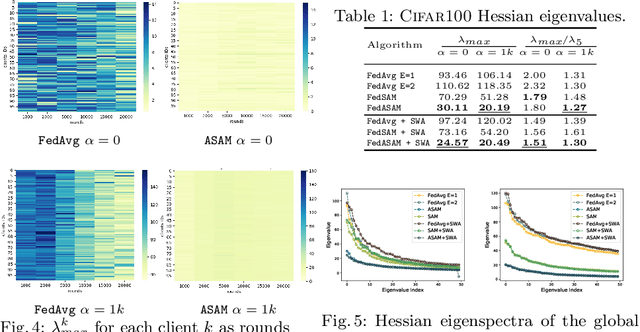

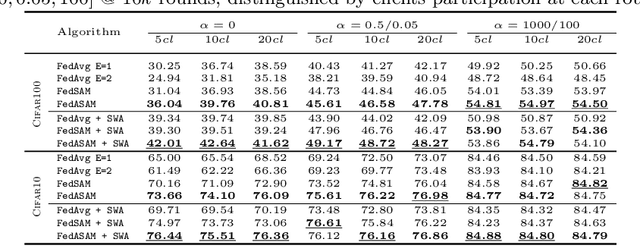
Models trained in federated settings often suffer from degraded performances and fail at generalizing, especially when facing heterogeneous scenarios. In this work, we investigate such behavior through the lens of geometry of the loss and Hessian eigenspectrum, linking the model's lack of generalization capacity to the sharpness of the solution. Motivated by prior studies connecting the sharpness of the loss surface and the generalization gap, we show that i) training clients locally with Sharpness-Aware Minimization (SAM) or its adaptive version (ASAM) and ii) averaging stochastic weights (SWA) on the server-side can substantially improve generalization in Federated Learning and help bridging the gap with centralized models. By seeking parameters in neighborhoods having uniform low loss, the model converges towards flatter minima and its generalization significantly improves in both homogeneous and heterogeneous scenarios. Empirical results demonstrate the effectiveness of those optimizers across a variety of benchmark vision datasets (e.g. CIFAR10/100, Landmarks-User-160k, IDDA) and tasks (large scale classification, semantic segmentation, domain generalization).
FedDrive: Generalizing Federated Learning to Semantic Segmentation in Autonomous Driving
Feb 28, 2022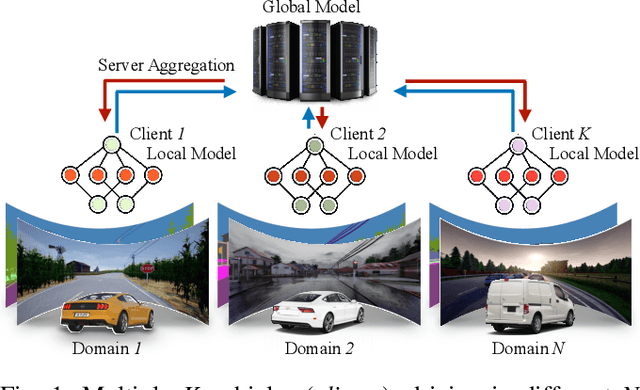


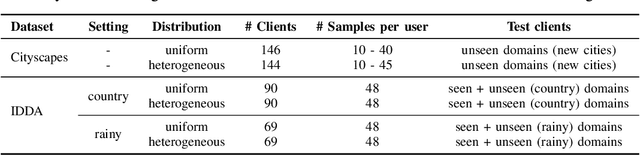
Semantic Segmentation is essential to make self-driving vehicles autonomous, enabling them to understand their surroundings by assigning individual pixels to known categories. However, it operates on sensible data collected from the users' cars; thus, protecting the clients' privacy becomes a primary concern. For similar reasons, Federated Learning has been recently introduced as a new machine learning paradigm aiming to learn a global model while preserving privacy and leveraging data on millions of remote devices. Despite several efforts on this topic, no work has explicitly addressed the challenges of federated learning in semantic segmentation for driving so far. To fill this gap, we propose FedDrive, a new benchmark consisting of three settings and two datasets, incorporating the real-world challenges of statistical heterogeneity and domain generalization. We benchmark state-of-the-art algorithms from the federated learning literature through an in-depth analysis, combining them with style transfer methods to improve their generalization ability. We demonstrate that correctly handling normalization statistics is crucial to deal with the aforementioned challenges. Furthermore, style transfer improves performance when dealing with significant appearance shifts. We plan to make both the code and the benchmark publicly available to the research community.
Speeding up Heterogeneous Federated Learning with Sequentially Trained Superclients
Jan 26, 2022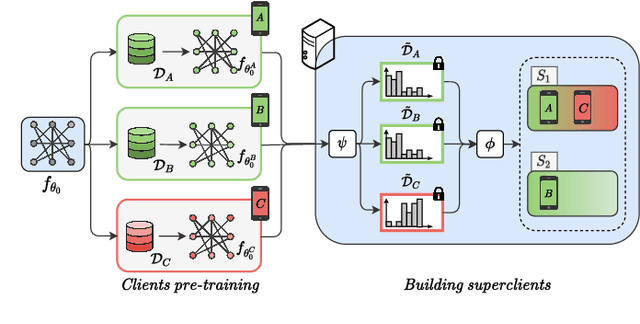
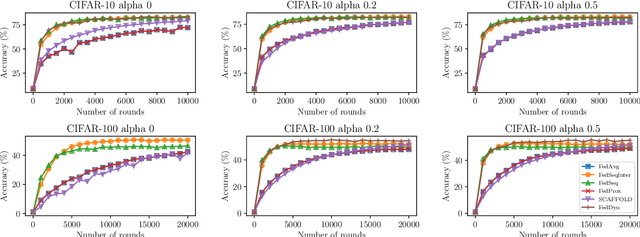
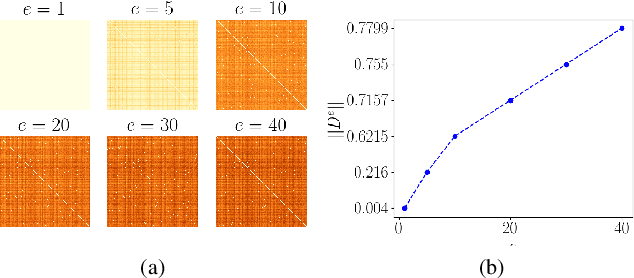

Federated Learning (FL) allows training machine learning models in privacy-constrained scenarios by enabling the cooperation of edge devices without requiring local data sharing. This approach raises several challenges due to the different statistical distribution of the local datasets and the clients' computational heterogeneity. In particular, the presence of highly non-i.i.d. data severely impairs both the performance of the trained neural network and its convergence rate, increasing the number of communication rounds requested to reach a performance comparable to that of the centralized scenario. As a solution, we propose FedSeq, a novel framework leveraging the sequential training of subgroups of heterogeneous clients, i.e. superclients, to emulate the centralized paradigm in a privacy-compliant way. Given a fixed budget of communication rounds, we show that FedSeq outperforms or match several state-of-the-art federated algorithms in terms of final performance and speed of convergence. Finally, our method can be easily integrated with other approaches available in the literature. Empirical results show that combining existing algorithms with FedSeq further improves its final performance and convergence speed. We test our method on CIFAR-10 and CIFAR-100 and prove its effectiveness in both i.i.d. and non-i.i.d. scenarios.
Cluster-driven Graph Federated Learning over Multiple Domains
Apr 29, 2021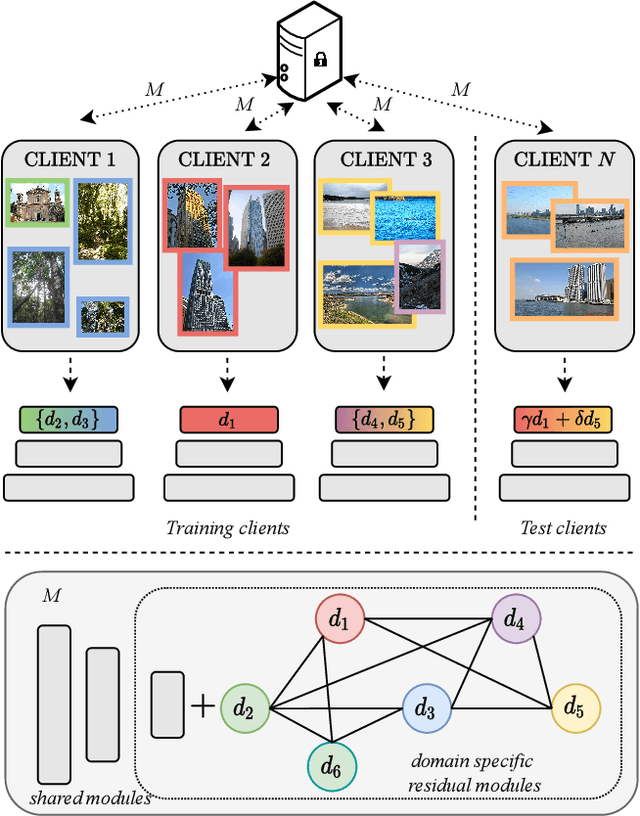
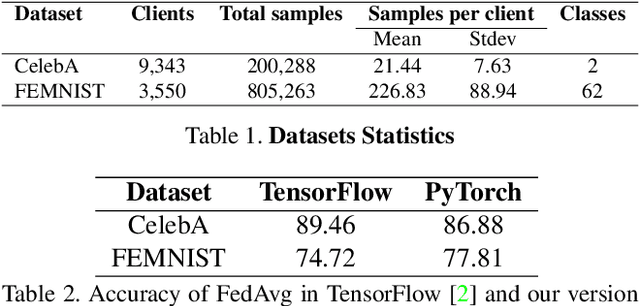
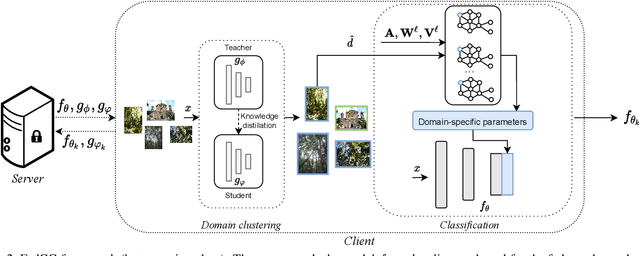
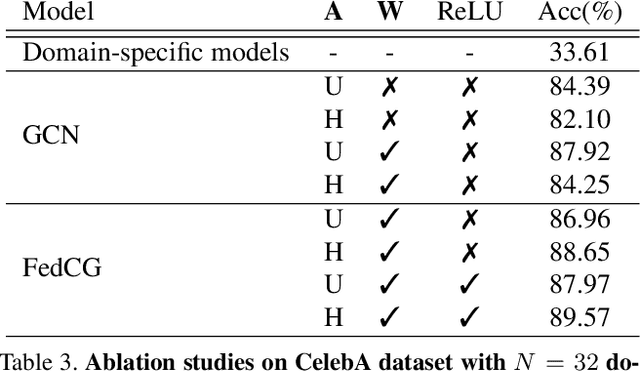
Federated Learning (FL) deals with learning a central model (i.e. the server) in privacy-constrained scenarios, where data are stored on multiple devices (i.e. the clients). The central model has no direct access to the data, but only to the updates of the parameters computed locally by each client. This raises a problem, known as statistical heterogeneity, because the clients may have different data distributions (i.e. domains). This is only partly alleviated by clustering the clients. Clustering may reduce heterogeneity by identifying the domains, but it deprives each cluster model of the data and supervision of others. Here we propose a novel Cluster-driven Graph Federated Learning (FedCG). In FedCG, clustering serves to address statistical heterogeneity, while Graph Convolutional Networks (GCNs) enable sharing knowledge across them. FedCG: i) identifies the domains via an FL-compliant clustering and instantiates domain-specific modules (residual branches) for each domain; ii) connects the domain-specific modules through a GCN at training to learn the interactions among domains and share knowledge; and iii) learns to cluster unsupervised via teacher-student classifier-training iterations and to address novel unseen test domains via their domain soft-assignment scores. Thanks to the unique interplay of GCN over clusters, FedCG achieves the state-of-the-art on multiple FL benchmarks.