 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature-Space Generative Models for One-Shot Class-Incremental Learning
Jan 25, 2026Few-shot class-incremental learning (FSCIL) is a paradigm where a model, initially trained on a dataset of base classes, must adapt to an expanding problem space by recognizing novel classes with limited data. We focus on the challenging FSCIL setup where a model receives only a single sample (1-shot) for each novel class and no further training or model alterations are allowed after the base training phase. This makes generalization to novel classes particularly difficult. We propose a novel approach predicated on the hypothesis that base and novel class embeddings have structural similarity. We map the original embedding space into a residual space by subtracting the class prototype (i.e., the average class embedding) of input samples. Then, we leverage generative modeling with VAE or diffusion models to learn the multi-modal distribution of residuals over the base classes, and we use this as a valuable structural prior to improve recognition of novel classes. Our approach, Gen1S, consistently improves novel class recognition over the state of the art across multiple benchmarks and backbone architectures.
Clustering-driven Memory Compression for On-device Large Language Models
Jan 24, 2026Large language models (LLMs) often rely on user-specific memories distilled from past interactions to enable personalized generation. A common practice is to concatenate these memories with the input prompt, but this approach quickly exhausts the limited context available in on-device LLMs. Compressing memories by averaging can mitigate context growth, yet it frequently harms performance due to semantic conflicts across heterogeneous memories. In this work, we introduce a clustering-based memory compression strategy that balances context efficiency and personalization quality. Our method groups memories by similarity and merges them within clusters prior to concatenation, thereby preserving coherence while reducing redundancy. Experiments demonstrate that our approach substantially lowers the number of memory tokens while outperforming baseline strategies such as naive averaging or direct concatenation. Furthermore, for a fixed context budget, clustering-driven merging yields more compact memory representations and consistently enhances generation quality.
Data-driven Clustering and Merging of Adapters for On-device Large Language Models
Jan 24, 2026On-device large language models commonly employ task-specific adapters (e.g., LoRAs) to deliver strong performance on downstream tasks. While storing all available adapters is impractical due to memory constraints, mobile devices typically have sufficient capacity to store a limited number of these parameters. This raises a critical challenge: how to select representative adapters that generalize well across multiple tasks - a problem that remains unexplored in existing literature. We propose a novel method D2C for adapter clustering that leverages minimal task-specific examples (e.g., 10 per task) and employs an iterative optimization process to refine cluster assignments. The adapters within each cluster are merged, creating multi-task adapters deployable on resource-constrained devices. Experimental results demonstrate that our method effectively boosts performance for considered storage budgets.
CG-TTRL: Context-Guided Test-Time Reinforcement Learning for On-Device Large Language Models
Nov 09, 2025Test-time Reinforcement Learning (TTRL) has shown promise in adapting foundation models for complex tasks at test-time, resulting in large performance improvements. TTRL leverages an elegant two-phase sampling strategy: first, multi-sampling derives a pseudo-label via majority voting, while subsequent downsampling and reward-based fine-tuning encourages the model to explore and learn diverse valid solutions, with the pseudo-label modulating the reward signal. Meanwhile, in-context learning has been widely explored at inference time and demonstrated the ability to enhance model performance without weight updates. However, TTRL's two-phase sampling strategy under-utilizes contextual guidance, which can potentially improve pseudo-label accuracy in the initial exploitation phase while regulating exploration in the second. To address this, we propose context-guided TTRL (CG-TTRL), integrating context dynamically into both sampling phases and propose a method for efficient context selection for on-device applications. Our evaluations on mathematical and scientific QA benchmarks show CG-TTRL outperforms TTRL (e.g. additional 7% relative accuracy improvement over TTRL), while boosting efficiency by obtaining strong performance after only a few steps of test-time training (e.g. 8% relative improvement rather than 1% over TTRL after 3 steps).
MOCHA: Multi-modal Objects-aware Cross-arcHitecture Alignment
Sep 17, 2025We introduce MOCHA (Multi-modal Objects-aware Cross-arcHitecture Alignment), a knowledge distillation approach that transfers region-level multimodal semantics from a large vision-language teacher (e.g., LLaVa) into a lightweight vision-only object detector student (e.g., YOLO). A translation module maps student features into a joint space, where the training of the student and translator is guided by a dual-objective loss that enforces both local alignment and global relational consistency. Unlike prior approaches focused on dense or global alignment, MOCHA operates at the object level, enabling efficient transfer of semantics without modifying the teacher or requiring textual input at inference. We validate our method across four personalized detection benchmarks under few-shot regimes. Results show consistent gains over baselines, with a +10.1 average score improvement. Despite its compact architecture, MOCHA reaches performance on par with larger multimodal models, proving its suitability for real-world deployment.
HydraOpt: Navigating the Efficiency-Performance Trade-off of Adapter Merging
Jul 23, 2025Large language models (LLMs) often leverage adapters, such as low-rank-based adapters, to achieve strong performance on downstream tasks. However, storing a separate adapter for each task significantly increases memory requirements, posing a challenge for resource-constrained environments such as mobile devices. Although model merging techniques can reduce storage costs, they typically result in substantial performance degradation. In this work, we introduce HydraOpt, a new model merging technique that capitalizes on the inherent similarities between the matrices of low-rank adapters. Unlike existing methods that produce a fixed trade-off between storage size and performance, HydraOpt allows us to navigate this spectrum of efficiency and performance. Our experiments show that HydraOpt significantly reduces storage size (48% reduction) compared to storing all adapters, while achieving competitive performance (0.2-1.8% drop). Furthermore, it outperforms existing merging techniques in terms of performance at the same or slightly worse storage efficiency.
Brain-inspired sparse training enables Transformers and LLMs to perform as fully connected
Jan 31, 2025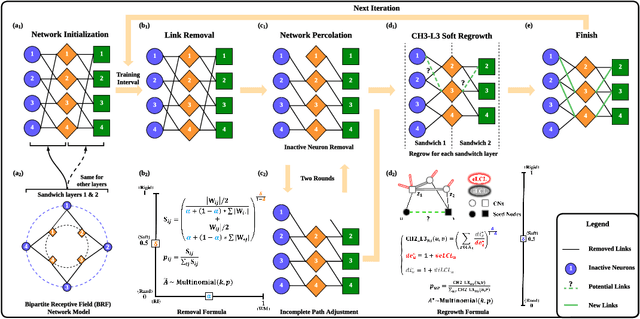
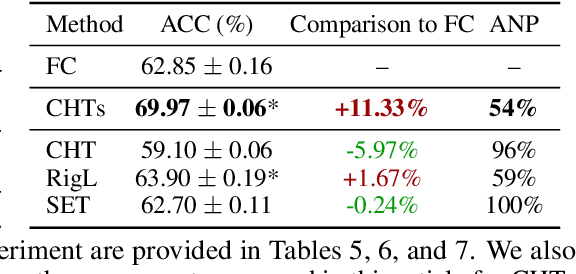
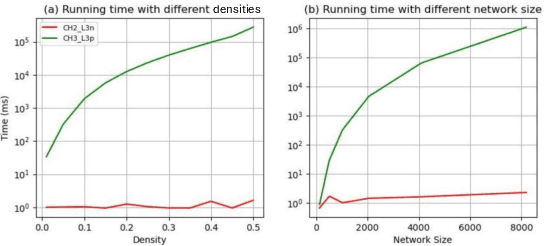
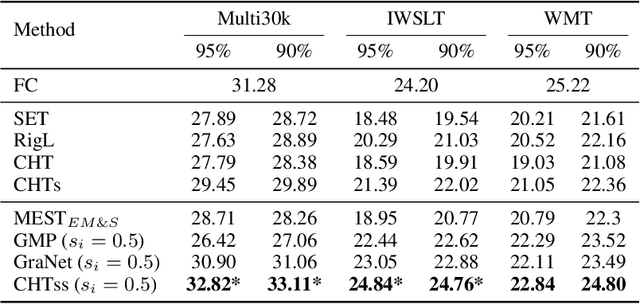
This study aims to enlarge our current knowledge on application of brain-inspired network science principles for training artificial neural networks (ANNs) with sparse connectivity. Dynamic sparse training (DST) can reduce the computational demands in ANNs, but faces difficulties to keep peak performance at high sparsity levels. The Cannistraci-Hebb training (CHT) is a brain-inspired method for growing connectivity in DST. CHT leverages a gradient-free, topology-driven link regrowth, which has shown ultra-sparse (1% connectivity or lower) advantage across various tasks compared to fully connected networks. Yet, CHT suffers two main drawbacks: (i) its time complexity is O(Nd^3) - N node network size, d node degree - hence it can apply only to ultra-sparse networks. (ii) it selects top link prediction scores, which is inappropriate for the early training epochs, when the network presents unreliable connections. We propose a GPU-friendly approximation of the CH link predictor, which reduces the computational complexity to O(N^3), enabling a fast implementation of CHT in large-scale models. We introduce the Cannistraci-Hebb training soft rule (CHTs), which adopts a strategy for sampling connections in both link removal and regrowth, balancing the exploration and exploitation of network topology. To improve performance, we integrate CHTs with a sigmoid gradual density decay (CHTss). Empirical results show that, using 1% of connections, CHTs outperforms fully connected networks in MLP on visual classification tasks, compressing some networks to < 30% nodes. Using 5% of the connections, CHTss outperforms fully connected networks in two Transformer-based machine translation tasks. Using 30% of the connections, CHTss achieves superior performance compared to other dynamic sparse training methods in language modeling, and it surpasses the fully connected counterpart in zero-shot evaluations.
Controllable Forgetting Mechanism for Few-Shot Class-Incremental Learning
Jan 27, 2025Class-incremental learning in the context of limited personal labeled samples (few-shot) is critical for numerous real-world applications, such as smart home devices. A key challenge in these scenarios is balancing the trade-off between adapting to new, personalized classes and maintaining the performance of the model on the original, base classes. Fine-tuning the model on novel classes often leads to the phenomenon of catastrophic forgetting, where the accuracy of base classes declines unpredictably and significantly. In this paper, we propose a simple yet effective mechanism to address this challenge by controlling the trade-off between novel and base class accuracy. We specifically target the ultra-low-shot scenario, where only a single example is available per novel class. Our approach introduces a Novel Class Detection (NCD) rule, which adjusts the degree of forgetting a priori while simultaneously enhancing performance on novel classes. We demonstrate the versatility of our solution by applying it to state-of-the-art Few-Shot Class-Incremental Learning (FSCIL) methods, showing consistent improvements across different settings. To better quantify the trade-off between novel and base class performance, we introduce new metrics: NCR@2FOR and NCR@5FOR. Our approach achieves up to a 30% improvement in novel class accuracy on the CIFAR100 dataset (1-shot, 1 novel class) while maintaining a controlled base class forgetting rate of 2%.
LoRA.rar: Learning to Merge LoRAs via Hypernetworks for Subject-Style Conditioned Image Generation
Dec 06, 2024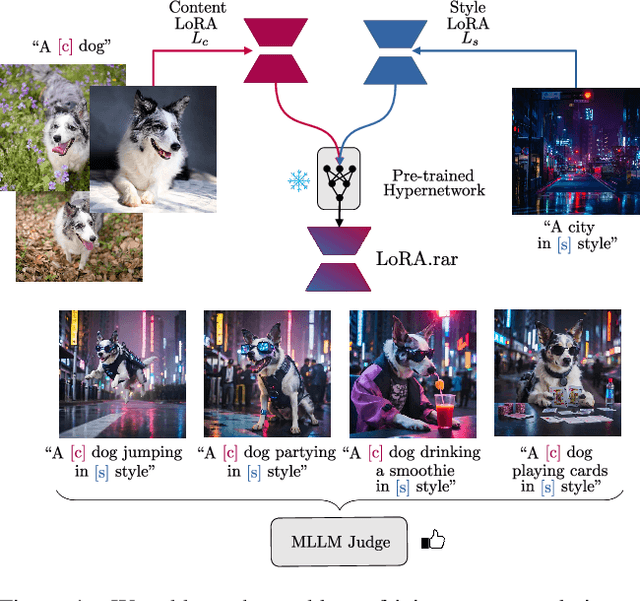
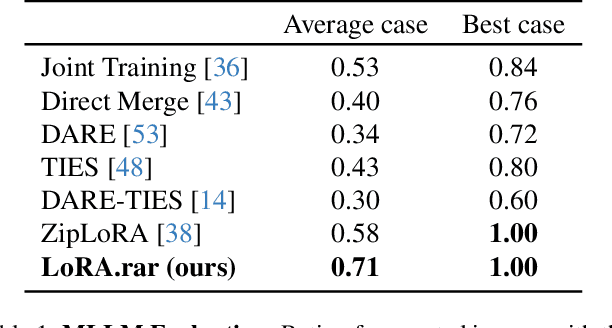
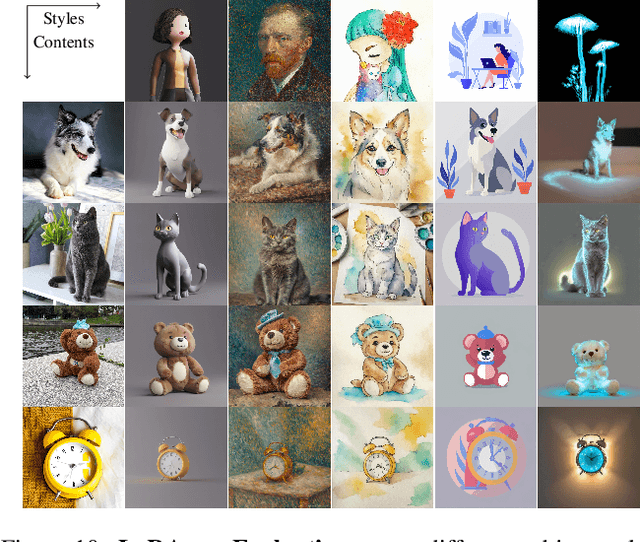
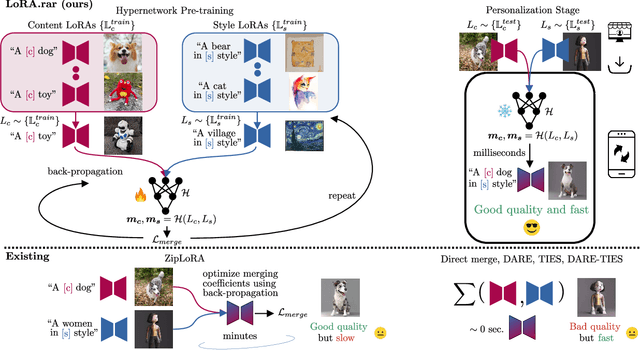
Recent advancements in image generation models have enabled personalized image creation with both user-defined subjects (content) and styles. Prior works achieved personalization by merging corresponding low-rank adaptation parameters (LoRAs) through optimization-based methods, which are computationally demanding and unsuitable for real-time use on resource-constrained devices like smartphones. To address this, we introduce LoRA$.$rar, a method that not only improves image quality but also achieves a remarkable speedup of over $4000\times$ in the merging process. LoRA$.$rar pre-trains a hypernetwork on a diverse set of content-style LoRA pairs, learning an efficient merging strategy that generalizes to new, unseen content-style pairs, enabling fast, high-quality personalization. Moreover, we identify limitations in existing evaluation metrics for content-style quality and propose a new protocol using multimodal large language models (MLLM) for more accurate assessment. Our method significantly outperforms the current state of the art in both content and style fidelity, as validated by MLLM assessments and human evaluations.
DreamCache: Finetuning-Free Lightweight Personalized Image Generation via Feature Caching
Nov 26, 2024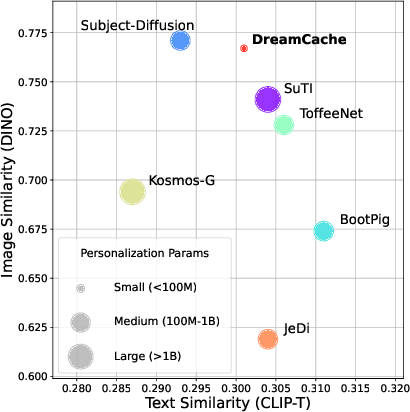
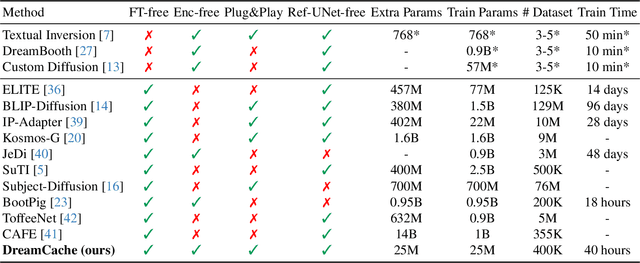

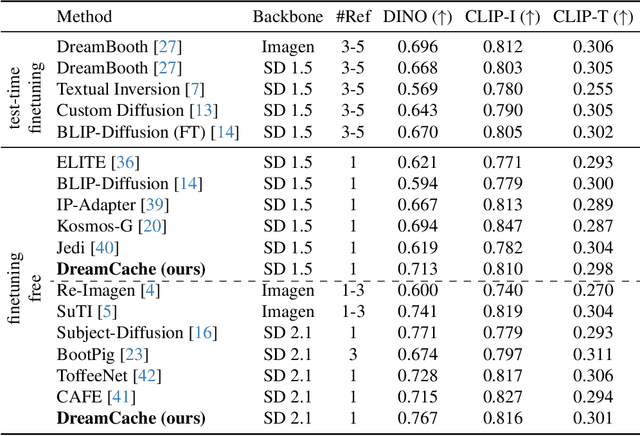
Personalized image generation requires text-to-image generative models that capture the core features of a reference subject to allow for controlled generation across different contexts. Existing methods face challenges due to complex training requirements, high inference costs, limited flexibility, or a combination of these issues. In this paper, we introduce DreamCache, a scalable approach for efficient and high-quality personalized image generation. By caching a small number of reference image features from a subset of layers and a single timestep of the pretrained diffusion denoiser, DreamCache enables dynamic modulation of the generated image features through lightweight, trained conditioning adapters. DreamCache achieves state-of-the-art image and text alignment, utilizing an order of magnitude fewer extra parameters, and is both more computationally effective and versatile than existing models.