 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplit&Splat: Zero-Shot Panoptic Segmentation via Explicit Instance Modeling and 3D Gaussian Splatting
Feb 01, 20263D Gaussian Splatting (GS) enables fast and high-quality scene reconstruction, but it lacks an object-consistent and semantically aware structure. We propose Split&Splat, a framework for panoptic scene reconstruction using 3DGS. Our approach explicitly models object instances. It first propagates instance masks across views using depth, thus producing view-consistent 2D masks. Each object is then reconstructed independently and merged back into the scene while refining its boundaries. Finally, instance-level semantic descriptors are embedded in the reconstructed objects, supporting various applications, including panoptic segmentation, object retrieval, and 3D editing. Unlike existing methods, Split&Splat tackles the problem by first segmenting the scene and then reconstructing each object individually. This design naturally supports downstream tasks and allows Split&Splat to achieve state-of-the-art performance on the ScanNetv2 segmentation benchmark.
MOCHA: Multi-modal Objects-aware Cross-arcHitecture Alignment
Sep 17, 2025We introduce MOCHA (Multi-modal Objects-aware Cross-arcHitecture Alignment), a knowledge distillation approach that transfers region-level multimodal semantics from a large vision-language teacher (e.g., LLaVa) into a lightweight vision-only object detector student (e.g., YOLO). A translation module maps student features into a joint space, where the training of the student and translator is guided by a dual-objective loss that enforces both local alignment and global relational consistency. Unlike prior approaches focused on dense or global alignment, MOCHA operates at the object level, enabling efficient transfer of semantics without modifying the teacher or requiring textual input at inference. We validate our method across four personalized detection benchmarks under few-shot regimes. Results show consistent gains over baselines, with a +10.1 average score improvement. Despite its compact architecture, MOCHA reaches performance on par with larger multimodal models, proving its suitability for real-world deployment.
Claycode: Stylable and Deformable 2D Scannable Codes
May 13, 2025



This paper introduces Claycode, a novel 2D scannable code designed for extensive stylization and deformation. Unlike traditional matrix-based codes (e.g., QR codes), Claycodes encode their message in a tree structure. During the encoding process, bits are mapped into a topology tree, which is then depicted as a nesting of color regions drawn within the boundaries of a target polygon shape. When decoding, Claycodes are extracted and interpreted in real-time from a camera stream. We detail the end-to-end pipeline and show that Claycodes allow for extensive stylization without compromising their functionality. We then empirically demonstrate Claycode's high tolerance to heavy deformations, outperforming traditional 2D scannable codes in scenarios where they typically fail.
SAGE: Semantic-Driven Adaptive Gaussian Splatting in Extended Reality
Mar 20, 2025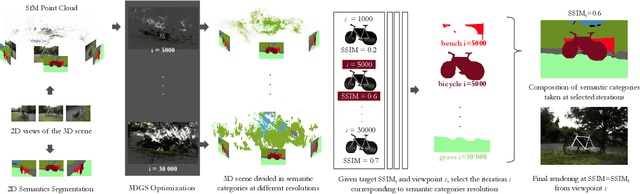
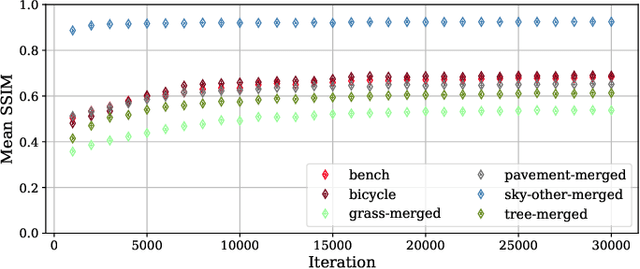
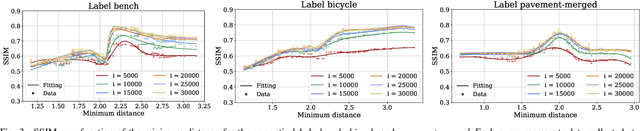

3D Gaussian Splatting (3DGS) has significantly improved the efficiency and realism of three-dimensional scene visualization in several applications, ranging from robotics to eXtended Reality (XR). This work presents SAGE (Semantic-Driven Adaptive Gaussian Splatting in Extended Reality), a novel framework designed to enhance the user experience by dynamically adapting the Level of Detail (LOD) of different 3DGS objects identified via a semantic segmentation. Experimental results demonstrate how SAGE effectively reduces memory and computational overhead while keeping a desired target visual quality, thus providing a powerful optimization for interactive XR applications.
Enhanced Model Robustness to Input Corruptions by Per-corruption Adaptation of Normalization Statistics
Jul 08, 2024Developing a reliable vision system is a fundamental challenge for robotic technologies (e.g., indoor service robots and outdoor autonomous robots) which can ensure reliable navigation even in challenging environments such as adverse weather conditions (e.g., fog, rain), poor lighting conditions (e.g., over/under exposure), or sensor degradation (e.g., blurring, noise), and can guarantee high performance in safety-critical functions. Current solutions proposed to improve model robustness usually rely on generic data augmentation techniques or employ costly test-time adaptation methods. In addition, most approaches focus on addressing a single vision task (typically, image recognition) utilising synthetic data. In this paper, we introduce Per-corruption Adaptation of Normalization statistics (PAN) to enhance the model robustness of vision systems. Our approach entails three key components: (i) a corruption type identification module, (ii) dynamic adjustment of normalization layer statistics based on identified corruption type, and (iii) real-time update of these statistics according to input data. PAN can integrate seamlessly with any convolutional model for enhanced accuracy in several robot vision tasks. In our experiments, PAN obtains robust performance improvement on challenging real-world corrupted image datasets (e.g., OpenLoris, ExDark, ACDC), where most of the current solutions tend to fail. Moreover, PAN outperforms the baseline models by 20-30% on synthetic benchmarks in object recognition tasks.
FFT-based Selection and Optimization of Statistics for Robust Recognition of Severely Corrupted Images
Mar 21, 2024Improving model robustness in case of corrupted images is among the key challenges to enable robust vision systems on smart devices, such as robotic agents. Particularly, robust test-time performance is imperative for most of the applications. This paper presents a novel approach to improve robustness of any classification model, especially on severely corrupted images. Our method (FROST) employs high-frequency features to detect input image corruption type, and select layer-wise feature normalization statistics. FROST provides the state-of-the-art results for different models and datasets, outperforming competitors on ImageNet-C by up to 37.1% relative gain, improving baseline of 40.9% mCE on severe corruptions.
Continual Road-Scene Semantic Segmentation via Feature-Aligned Symmetric Multi-Modal Network
Aug 09, 2023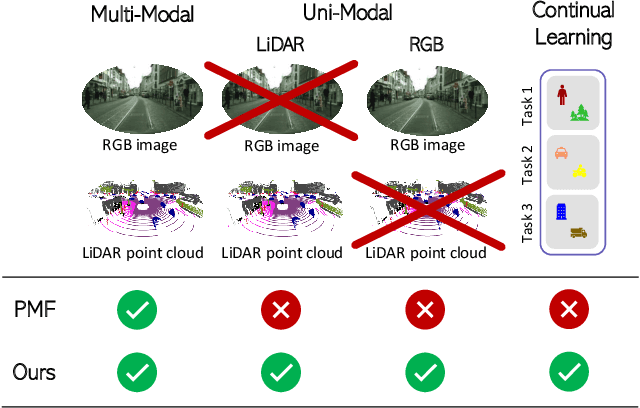

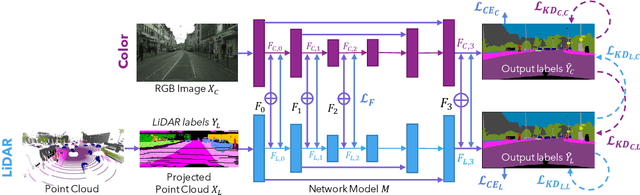

State-of-the-art multimodal semantic segmentation approaches combining LiDAR and color data are usually designed on top of asymmetric information-sharing schemes and assume that both modalities are always available. Regrettably, this strong assumption may not hold in real-world scenarios, where sensors are prone to failure or can face adverse conditions (night-time, rain, fog, etc.) that make the acquired information unreliable. Moreover, these architectures tend to fail in continual learning scenarios. In this work, we re-frame the task of multimodal semantic segmentation by enforcing a tightly-coupled feature representation and a symmetric information-sharing scheme, which allows our approach to work even when one of the input modalities is missing. This makes our model reliable even in safety-critical settings, as is the case of autonomous driving. We evaluate our approach on the SemanticKITTI dataset, comparing it with our closest competitor. We also introduce an ad-hoc continual learning scheme and show results in a class-incremental continual learning scenario that prove the effectiveness of the approach also in this setting.
Continual Learning for LiDAR Semantic Segmentation: Class-Incremental and Coarse-to-Fine strategies on Sparse Data
Apr 08, 2023



During the last few years, continual learning (CL) strategies for image classification and segmentation have been widely investigated designing innovative solutions to tackle catastrophic forgetting, like knowledge distillation and self-inpainting. However, the application of continual learning paradigms to point clouds is still unexplored and investigation is required, especially using architectures that capture the sparsity and uneven distribution of LiDAR data. The current paper analyzes the problem of class incremental learning applied to point cloud semantic segmentation, comparing approaches and state-of-the-art architectures. To the best of our knowledge, this is the first example of class-incremental continual learning for LiDAR point cloud semantic segmentation. Different CL strategies were adapted to LiDAR point clouds and tested, tackling both classic fine-tuning scenarios and the Coarse-to-Fine learning paradigm. The framework has been evaluated through two different architectures on SemanticKITTI, obtaining results in line with state-of-the-art CL strategies and standard offline learning.
Learning from Mistakes: Self-Regularizing Hierarchical Semantic Representations in Point Cloud Segmentation
Jan 26, 2023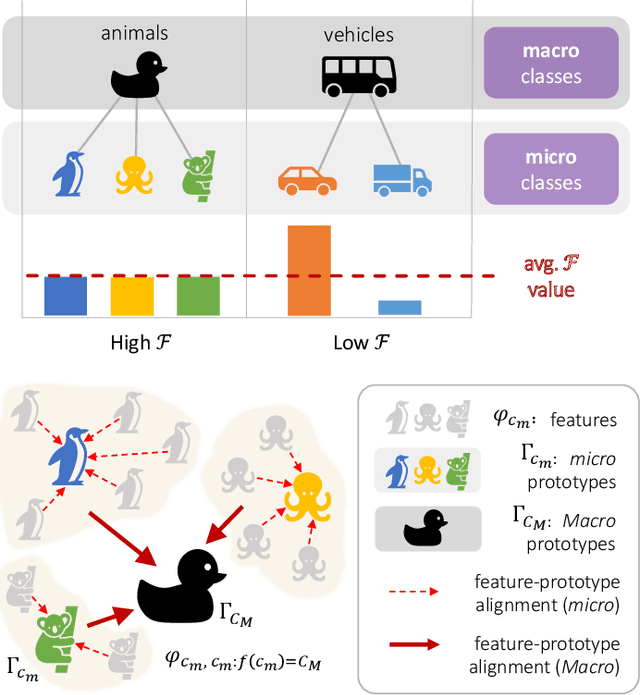
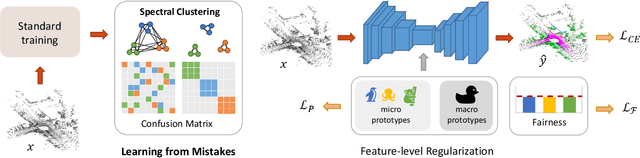
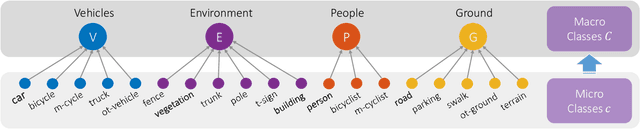
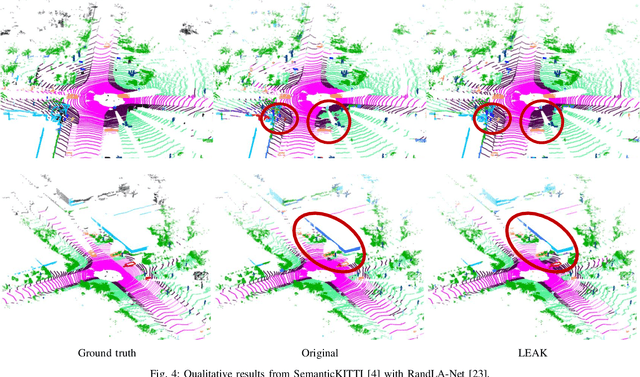
Recent advances in autonomous robotic technologies have highlighted the growing need for precise environmental analysis. LiDAR semantic segmentation has gained attention to accomplish fine-grained scene understanding by acting directly on raw content provided by sensors. Recent solutions showed how different learning techniques can be used to improve the performance of the model, without any architectural or dataset change. Following this trend, we present a coarse-to-fine setup that LEArns from classification mistaKes (LEAK) derived from a standard model. First, classes are clustered into macro groups according to mutual prediction errors; then, the learning process is regularized by: (1) aligning class-conditional prototypical feature representation for both fine and coarse classes, (2) weighting instances with a per-class fairness index. Our LEAK approach is very general and can be seamlessly applied on top of any segmentation architecture; indeed, experimental results showed that it enables state-of-the-art performances on different architectures, datasets and tasks, while ensuring more balanced class-wise results and faster convergence.