 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven Clustering and Merging of Adapters for On-device Large Language Models
Jan 24, 2026On-device large language models commonly employ task-specific adapters (e.g., LoRAs) to deliver strong performance on downstream tasks. While storing all available adapters is impractical due to memory constraints, mobile devices typically have sufficient capacity to store a limited number of these parameters. This raises a critical challenge: how to select representative adapters that generalize well across multiple tasks - a problem that remains unexplored in existing literature. We propose a novel method D2C for adapter clustering that leverages minimal task-specific examples (e.g., 10 per task) and employs an iterative optimization process to refine cluster assignments. The adapters within each cluster are merged, creating multi-task adapters deployable on resource-constrained devices. Experimental results demonstrate that our method effectively boosts performance for considered storage budgets.
HydraOpt: Navigating the Efficiency-Performance Trade-off of Adapter Merging
Jul 23, 2025Large language models (LLMs) often leverage adapters, such as low-rank-based adapters, to achieve strong performance on downstream tasks. However, storing a separate adapter for each task significantly increases memory requirements, posing a challenge for resource-constrained environments such as mobile devices. Although model merging techniques can reduce storage costs, they typically result in substantial performance degradation. In this work, we introduce HydraOpt, a new model merging technique that capitalizes on the inherent similarities between the matrices of low-rank adapters. Unlike existing methods that produce a fixed trade-off between storage size and performance, HydraOpt allows us to navigate this spectrum of efficiency and performance. Our experiments show that HydraOpt significantly reduces storage size (48% reduction) compared to storing all adapters, while achieving competitive performance (0.2-1.8% drop). Furthermore, it outperforms existing merging techniques in terms of performance at the same or slightly worse storage efficiency.
Controllable Forgetting Mechanism for Few-Shot Class-Incremental Learning
Jan 27, 2025Class-incremental learning in the context of limited personal labeled samples (few-shot) is critical for numerous real-world applications, such as smart home devices. A key challenge in these scenarios is balancing the trade-off between adapting to new, personalized classes and maintaining the performance of the model on the original, base classes. Fine-tuning the model on novel classes often leads to the phenomenon of catastrophic forgetting, where the accuracy of base classes declines unpredictably and significantly. In this paper, we propose a simple yet effective mechanism to address this challenge by controlling the trade-off between novel and base class accuracy. We specifically target the ultra-low-shot scenario, where only a single example is available per novel class. Our approach introduces a Novel Class Detection (NCD) rule, which adjusts the degree of forgetting a priori while simultaneously enhancing performance on novel classes. We demonstrate the versatility of our solution by applying it to state-of-the-art Few-Shot Class-Incremental Learning (FSCIL) methods, showing consistent improvements across different settings. To better quantify the trade-off between novel and base class performance, we introduce new metrics: NCR@2FOR and NCR@5FOR. Our approach achieves up to a 30% improvement in novel class accuracy on the CIFAR100 dataset (1-shot, 1 novel class) while maintaining a controlled base class forgetting rate of 2%.
Swiss DINO: Efficient and Versatile Vision Framework for On-device Personal Object Search
Jul 10, 2024
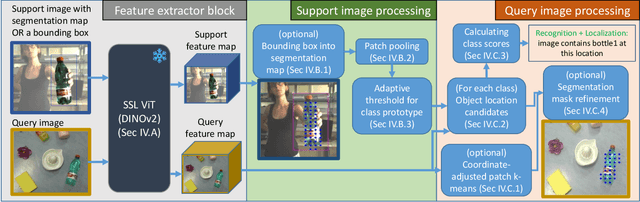


In this paper, we address a recent trend in robotic home appliances to include vision systems on personal devices, capable of personalizing the appliances on the fly. In particular, we formulate and address an important technical task of personal object search, which involves localization and identification of personal items of interest on images captured by robotic appliances, with each item referenced only by a few annotated images. The task is crucial for robotic home appliances and mobile systems, which need to process personal visual scenes or to operate with particular personal objects (e.g., for grasping or navigation). In practice, personal object search presents two main technical challenges. First, a robot vision system needs to be able to distinguish between many fine-grained classes, in the presence of occlusions and clutter. Second, the strict resource requirements for the on-device system restrict the usage of most state-of-the-art methods for few-shot learning and often prevent on-device adaptation. In this work, we propose Swiss DINO: a simple yet effective framework for one-shot personal object search based on the recent DINOv2 transformer model, which was shown to have strong zero-shot generalization properties. Swiss DINO handles challenging on-device personalized scene understanding requirements and does not require any adaptation training. We show significant improvement (up to 55%) in segmentation and recognition accuracy compared to the common lightweight solutions, and significant footprint reduction of backbone inference time (up to 100x) and GPU consumption (up to 10x) compared to the heavy transformer-based solutions.
Enhanced Model Robustness to Input Corruptions by Per-corruption Adaptation of Normalization Statistics
Jul 08, 2024Developing a reliable vision system is a fundamental challenge for robotic technologies (e.g., indoor service robots and outdoor autonomous robots) which can ensure reliable navigation even in challenging environments such as adverse weather conditions (e.g., fog, rain), poor lighting conditions (e.g., over/under exposure), or sensor degradation (e.g., blurring, noise), and can guarantee high performance in safety-critical functions. Current solutions proposed to improve model robustness usually rely on generic data augmentation techniques or employ costly test-time adaptation methods. In addition, most approaches focus on addressing a single vision task (typically, image recognition) utilising synthetic data. In this paper, we introduce Per-corruption Adaptation of Normalization statistics (PAN) to enhance the model robustness of vision systems. Our approach entails three key components: (i) a corruption type identification module, (ii) dynamic adjustment of normalization layer statistics based on identified corruption type, and (iii) real-time update of these statistics according to input data. PAN can integrate seamlessly with any convolutional model for enhanced accuracy in several robot vision tasks. In our experiments, PAN obtains robust performance improvement on challenging real-world corrupted image datasets (e.g., OpenLoris, ExDark, ACDC), where most of the current solutions tend to fail. Moreover, PAN outperforms the baseline models by 20-30% on synthetic benchmarks in object recognition tasks.
Cross-Architecture Auxiliary Feature Space Translation for Efficient Few-Shot Personalized Object Detection
Jul 01, 2024Recent years have seen object detection robotic systems deployed in several personal devices (e.g., home robots and appliances). This has highlighted a challenge in their design, i.e., they cannot efficiently update their knowledge to distinguish between general classes and user-specific instances (e.g., a dog vs. user's dog). We refer to this challenging task as Instance-level Personalized Object Detection (IPOD). The personalization task requires many samples for model tuning and optimization in a centralized server, raising privacy concerns. An alternative is provided by approaches based on recent large-scale Foundation Models, but their compute costs preclude on-device applications. In our work we tackle both problems at the same time, designing a Few-Shot IPOD strategy called AuXFT. We introduce a conditional coarse-to-fine few-shot learner to refine the coarse predictions made by an efficient object detector, showing that using an off-the-shelf model leads to poor personalization due to neural collapse. Therefore, we introduce a Translator block that generates an auxiliary feature space where features generated by a self-supervised model (e.g., DINOv2) are distilled without impacting the performance of the detector. We validate AuXFT on three publicly available datasets and one in-house benchmark designed for the IPOD task, achieving remarkable gains in all considered scenarios with excellent time-complexity trade-off: AuXFT reaches a performance of 80% its upper bound at just 32% of the inference time, 13% of VRAM and 19% of the model size.
Object-conditioned Bag of Instances for Few-Shot Personalized Instance Recognition
Apr 01, 2024Nowadays, users demand for increased personalization of vision systems to localize and identify personal instances of objects (e.g., my dog rather than dog) from a few-shot dataset only. Despite outstanding results of deep networks on classical label-abundant benchmarks (e.g., those of the latest YOLOv8 model for standard object detection), they struggle to maintain within-class variability to represent different instances rather than object categories only. We construct an Object-conditioned Bag of Instances (OBoI) based on multi-order statistics of extracted features, where generic object detection models are extended to search and identify personal instances from the OBoI's metric space, without need for backpropagation. By relying on multi-order statistics, OBoI achieves consistent superior accuracy in distinguishing different instances. In the results, we achieve 77.1% personal object recognition accuracy in case of 18 personal instances, showing about 12% relative gain over the state of the art.
FFT-based Selection and Optimization of Statistics for Robust Recognition of Severely Corrupted Images
Mar 21, 2024Improving model robustness in case of corrupted images is among the key challenges to enable robust vision systems on smart devices, such as robotic agents. Particularly, robust test-time performance is imperative for most of the applications. This paper presents a novel approach to improve robustness of any classification model, especially on severely corrupted images. Our method (FROST) employs high-frequency features to detect input image corruption type, and select layer-wise feature normalization statistics. FROST provides the state-of-the-art results for different models and datasets, outperforming competitors on ImageNet-C by up to 37.1% relative gain, improving baseline of 40.9% mCE on severe corruptions.
NNStreamer: Efficient and Agile Development of On-Device AI Systems
Jan 16, 2021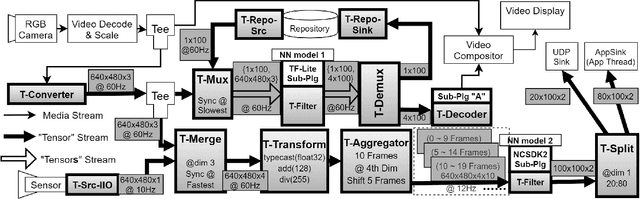

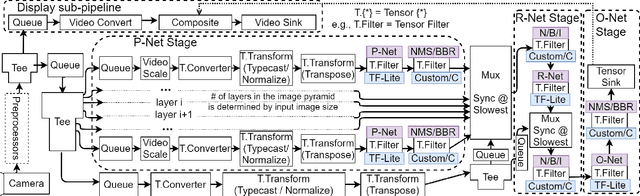
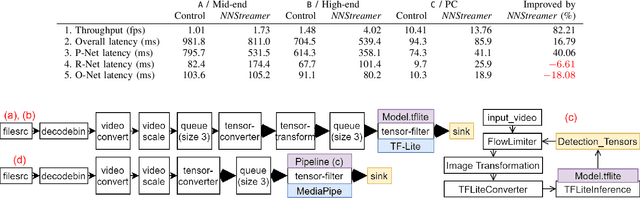
We propose NNStreamer, a software system that handles neural networks as filters of stream pipelines, applying the stream processing paradigm to deep neural network applications. A new trend with the wide-spread of deep neural network applications is on-device AI. It is to process neural networks on mobile devices or edge/IoT devices instead of cloud servers. Emerging privacy issues, data transmission costs, and operational costs signify the need for on-device AI, especially if we deploy a massive number of devices. NNStreamer efficiently handles neural networks with complex data stream pipelines on devices, significantly improving the overall performance with minimal efforts. Besides, NNStreamer simplifies implementations and allows reusing off-the-shelf media filters directly, which reduces developmental costs significantly. We are already deploying NNStreamer for a wide range of products and platforms, including the Galaxy series and various consumer electronic devices. The experimental results suggest a reduction in developmental costs and enhanced performance of pipeline architectures and NNStreamer. It is an open-source project incubated by Linux Foundation AI, available to the public and applicable to various hardware and software platforms.