 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNNTrainer: Light-Weight On-Device Training Framework
Jun 09, 2022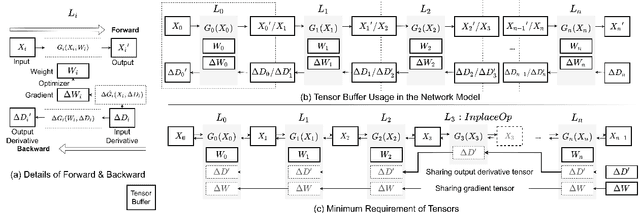


Modern consumer electronic devices have adopted deep learning-based intelligence services for their key features. Vendors have recently started to execute intelligence services on devices to preserve personal data in devices, reduce network and cloud costs. We find such a trend as the opportunity to personalize intelligence services by updating neural networks with user data without exposing the data out of devices: on-device training. For example, we may add a new class, my dog, Alpha, for robotic vacuums, adapt speech recognition for the users accent, let text-to-speech speak as if the user speaks. However, the resource limitations of target devices incur significant difficulties. We propose NNTrainer, a light-weight on-device training framework. We describe optimization techniques for neural networks implemented by NNTrainer, which are evaluated along with the conventional. The evaluations show that NNTrainer can reduce memory consumption down to 1/28 without deteriorating accuracy or training time and effectively personalizes applications on devices. NNTrainer is cross-platform and practical open source software, which is being deployed to millions of devices in the authors affiliation.
NNStreamer: Efficient and Agile Development of On-Device AI Systems
Jan 16, 2021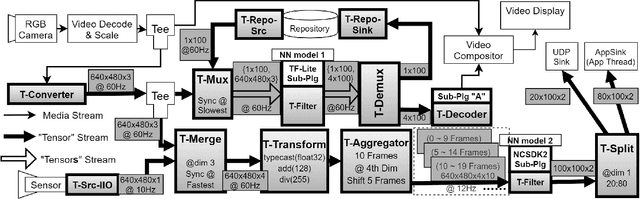

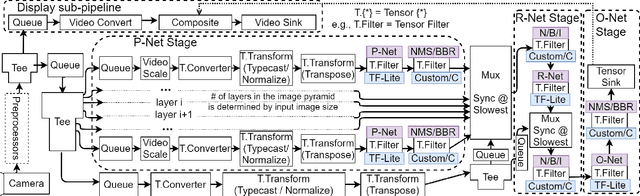
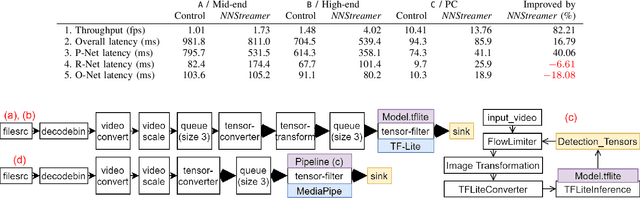
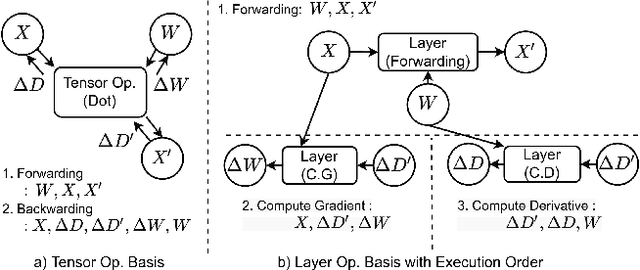
We propose NNStreamer, a software system that handles neural networks as filters of stream pipelines, applying the stream processing paradigm to deep neural network applications. A new trend with the wide-spread of deep neural network applications is on-device AI. It is to process neural networks on mobile devices or edge/IoT devices instead of cloud servers. Emerging privacy issues, data transmission costs, and operational costs signify the need for on-device AI, especially if we deploy a massive number of devices. NNStreamer efficiently handles neural networks with complex data stream pipelines on devices, significantly improving the overall performance with minimal efforts. Besides, NNStreamer simplifies implementations and allows reusing off-the-shelf media filters directly, which reduces developmental costs significantly. We are already deploying NNStreamer for a wide range of products and platforms, including the Galaxy series and various consumer electronic devices. The experimental results suggest a reduction in developmental costs and enhanced performance of pipeline architectures and NNStreamer. It is an open-source project incubated by Linux Foundation AI, available to the public and applicable to various hardware and software platforms.
Structured Compression by Unstructured Pruning for Sparse Quantized Neural Networks
May 24, 2019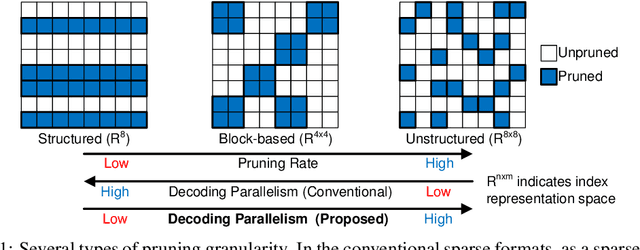
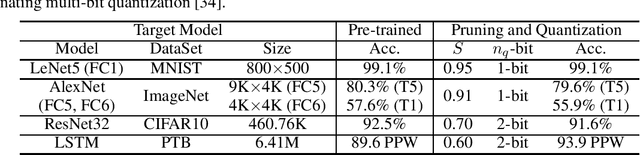
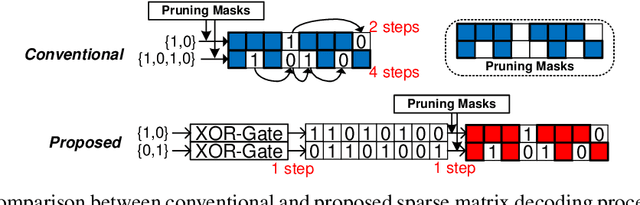
Model compression techniques, such as pruning and quantization, are becoming increasingly important to reduce the memory footprints and the amount of computations. Despite model size reduction, achieving performance enhancement on devices is, however, still challenging mainly due to the irregular representations of sparse matrix formats. This paper proposes a new representation to encode the weights of Sparse Quantized Neural Networks, specifically reduced by find-grained and unstructured pruning method. The representation is encoded in a structured regular format, which can be efficiently decoded through XOR gates during inference in a parallel manner. We demonstrate various deep learning models that can be compressed and represented by our proposed format with fixed and high compression ratio. For example, for fully-connected layers of AlexNet on ImageNet dataset, we can represent the sparse weights by only 0.09 bits/weight for 1-bit quantization and 91\% pruning rate with a fixed decoding rate and full memory bandwidth usage.
Network Pruning for Low-Rank Binary Indexing
May 14, 2019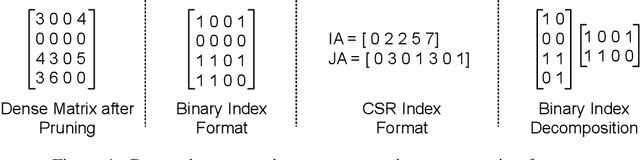
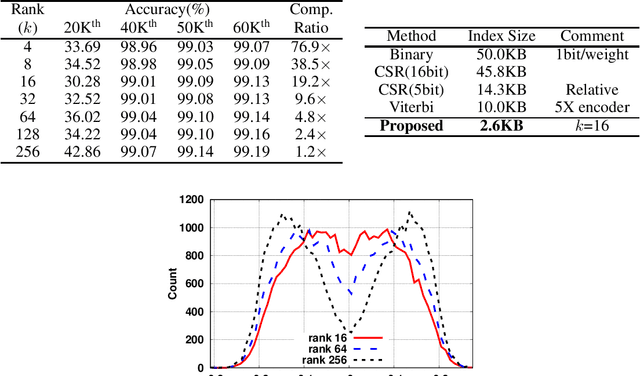
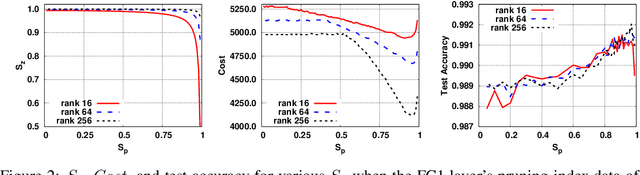
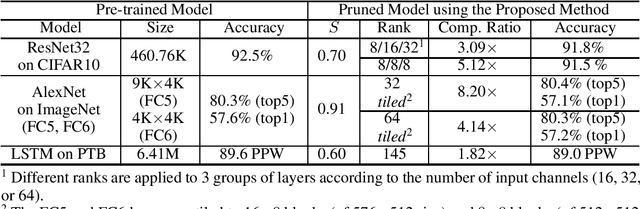
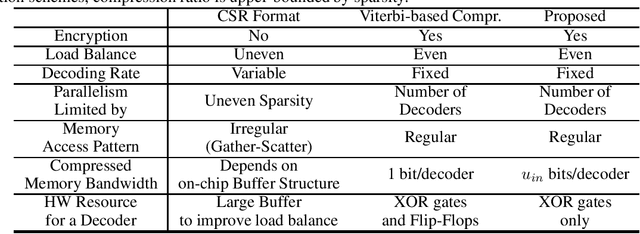
Pruning is an efficient model compression technique to remove redundancy in the connectivity of deep neural networks (DNNs). Computations using sparse matrices obtained by pruning parameters, however, exhibit vastly different parallelism depending on the index representation scheme. As a result, fine-grained pruning has not gained much attention due to its irregular index form leading to large memory footprint and low parallelism for convolutions and matrix multiplications. In this paper, we propose a new network pruning technique that generates a low-rank binary index matrix to compress index data while decompressing index data is performed by simple binary matrix multiplication. This proposed compression method finds a particular fine-grained pruning mask that can be decomposed into two binary matrices. We also propose a tile-based factorization technique that not only lowers memory requirements but also enhances compression ratio. Various DNN models can be pruned with much fewer indexes compared to previous sparse matrix formats while maintaining the same pruning rate.
DeepTwist: Learning Model Compression via Occasional Weight Distortion
Oct 30, 2018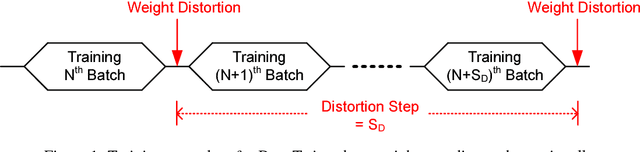
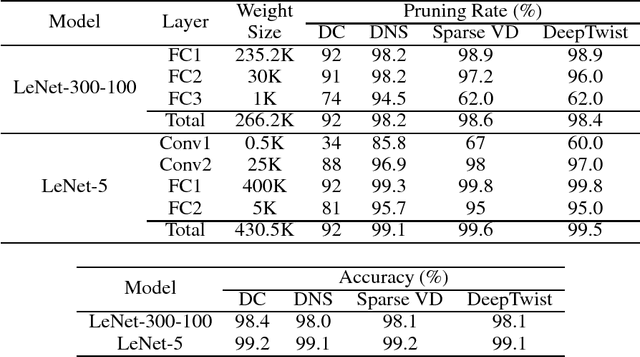

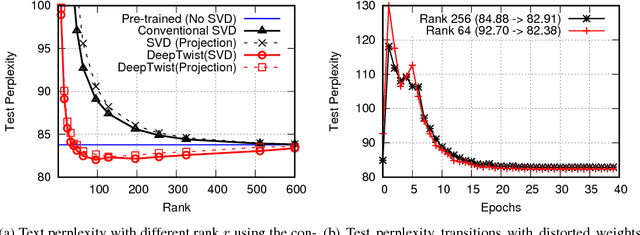
Model compression has been introduced to reduce the required hardware resources while maintaining the model accuracy. Lots of techniques for model compression, such as pruning, quantization, and low-rank approximation, have been suggested along with different inference implementation characteristics. Adopting model compression is, however, still challenging because the design complexity of model compression is rapidly increasing due to additional hyper-parameters and computation overhead in order to achieve a high compression ratio. In this paper, we propose a simple and efficient model compression framework called DeepTwist which distorts weights in an occasional manner without modifying the underlying training algorithms. The ideas of designing weight distortion functions are intuitive and straightforward given formats of compressed weights. We show that our proposed framework improves compression rate significantly for pruning, quantization, and low-rank approximation techniques while the efforts of additional retraining and/or hyper-parameter search are highly reduced. Regularization effects of DeepTwist are also reported.
A method of limiting performance loss of CNNs in noisy environments
Feb 03, 2017


Convolutional Neural Network (CNN) recognition rates drop in the presence of noise. We demonstrate a novel method of counteracting this drop in recognition rate by adjusting the biases of the neurons in the convolutional layers according to the noise conditions encountered at runtime. We compare our technique to training one network for all possible noise levels, dehazing via preprocessing a signal with a denoising autoencoder, and training a network specifically for each noise level. Our system compares favorably in terms of robustness, computational complexity and recognition rate.