 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepTwist: Learning Model Compression via Occasional Weight Distortion
Paper and Code
Oct 30, 2018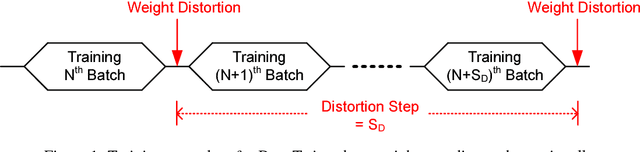
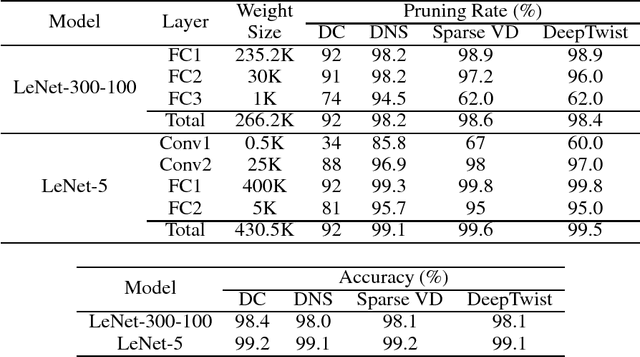

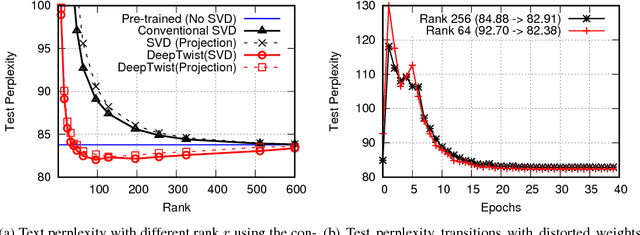
Model compression has been introduced to reduce the required hardware resources while maintaining the model accuracy. Lots of techniques for model compression, such as pruning, quantization, and low-rank approximation, have been suggested along with different inference implementation characteristics. Adopting model compression is, however, still challenging because the design complexity of model compression is rapidly increasing due to additional hyper-parameters and computation overhead in order to achieve a high compression ratio. In this paper, we propose a simple and efficient model compression framework called DeepTwist which distorts weights in an occasional manner without modifying the underlying training algorithms. The ideas of designing weight distortion functions are intuitive and straightforward given formats of compressed weights. We show that our proposed framework improves compression rate significantly for pruning, quantization, and low-rank approximation techniques while the efforts of additional retraining and/or hyper-parameter search are highly reduced. Regularization effects of DeepTwist are also reported.