 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUN: Shared Use of Next-token Prediction for Efficient Multi-LLM Disaggregated Serving
Mar 03, 2026In multi-model LLM serving, decode execution remains inefficient due to model-specific resource partitioning: since cross-model batching is not possible, memory-bound decoding often suffers from severe GPU underutilization, especially under skewed workloads. We propose Shared Use of Next-token Prediction (SUN), the first approach that enables cross-model sharing of decode execution in disaggregated multi-LLM serving. SUN decomposes a decoder-only Transformer into a prefill module and a decode module, and fine-tunes only the task-specific prefill module, enabling a frozen decode module to be shared across models. This design enables a model-agnostic decode routing policy that balances decode requests across shared workers to maximize utilization. Across diverse tasks and model families, SUN achieves accuracy comparable to full fine-tuning while maintaining system throughput with fewer decode workers. In particular, SUN improves throughput per GPU by up to 2.0x over conventional disaggregation while keeping time-per-output-token (TPOT) within 5%. SUN inherently enables and facilitates low-bit decoding; with Quantized SUN (QSUN), it achieves a 45% speedup with comparable accuracy to SUN while preserving the benefits of shared decoding.
Affine-Scaled Attention: Towards Flexible and Stable Transformer Attention
Feb 26, 2026Transformer attention is typically implemented using softmax normalization, which enforces attention weights with unit sum normalization. While effective in many settings, this constraint can limit flexibility in controlling attention magnitudes and may contribute to overly concentrated or unstable attention patterns during training. Prior work has explored modifications such as attention sinks or gating mechanisms, but these approaches provide only limited or indirect control over attention reweighting. We propose Affine-Scaled Attention, a simple extension to standard attention that introduces input-dependent scaling and a corresponding bias term applied to softmax-normalized attention weights. This design relaxes the strict normalization constraint while maintaining aggregation of value representations, allowing the model to adjust both the relative distribution and the scale of attention in a controlled manner. We empirically evaluate Affine-Scaled Attention in large-scale language model pretraining across multiple model sizes. Experimental results show consistent improvements in training stability, optimization behavior, and downstream task performance compared to standard softmax attention and attention sink baselines. These findings suggest that modest reweighting of attention outputs provides a practical and effective way to improve attention behavior in Transformer models.
PrefillShare: A Shared Prefill Module for KV Reuse in Multi-LLM Disaggregated Serving
Feb 12, 2026Multi-agent systems increasingly orchestrate multiple specialized language models to solve complex real-world problems, often invoking them over a shared context. This execution pattern repeatedly processes the same prompt prefix across models. Consequently, each model redundantly executes the prefill stage and maintains its own key-value (KV) cache, increasing aggregate prefill load and worsening tail latency by intensifying prefill-decode interference in existing LLM serving stacks. Disaggregated serving reduces such interference by placing prefill and decode on separate GPUs, but disaggregation does not fundamentally eliminate inter-model redundancy in computation and KV storage for the same prompt. To address this issue, we propose PrefillShare, a novel algorithm that enables sharing the prefill stage across multiple models in a disaggregated setting. PrefillShare factorizes the model into prefill and decode modules, freezes the prefill module, and fine-tunes only the decode module. This design allows multiple task-specific models to share a prefill module and the KV cache generated for the same prompt. We further introduce a routing mechanism that enables effective prefill sharing across heterogeneous models in a vLLM-based disaggregated system. PrefillShare not only matches full fine-tuning accuracy on a broad range of tasks and models, but also delivers 4.5x lower p95 latency and 3.9x higher throughput in multi-model agent workloads.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
DropBP: Accelerating Fine-Tuning of Large Language Models by Dropping Backward Propagation
Feb 27, 2024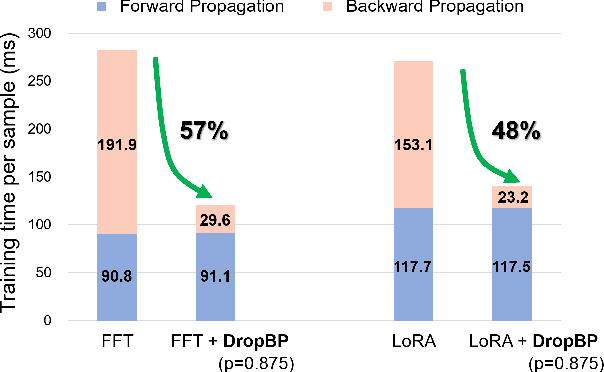

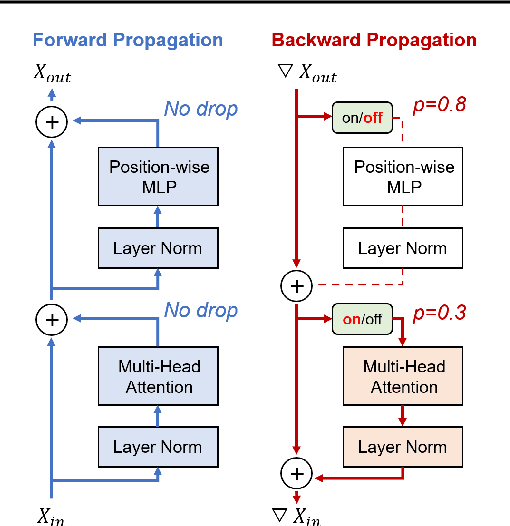

Training deep neural networks typically involves substantial computational costs during both forward and backward propagation. The conventional layer dropping techniques drop certain layers during training for reducing the computations burden. However, dropping layers during forward propagation adversely affects the training process by degrading accuracy. In this paper, we propose Dropping Backward Propagation (DropBP), a novel approach designed to reduce computational costs while maintaining accuracy. DropBP randomly drops layers during the backward propagation, which does not deviate forward propagation. Moreover, DropBP calculates the sensitivity of each layer to assign appropriate drop rate, thereby stabilizing the training process. DropBP is designed to enhance the efficiency of the training process with backpropagation, thereby enabling the acceleration of both full fine-tuning and parameter-efficient fine-tuning using backpropagation. Specifically, utilizing DropBP in QLoRA reduces training time by 44%, increases the convergence speed to the identical loss level by 1.5$\times$, and enables training with a 6.2$\times$ larger sequence length on a single NVIDIA-A100 80GiB GPU in LLaMA2-70B. The code is available at https://github.com/WooSunghyeon/dropbp.
AlphaTuning: Quantization-Aware Parameter-Efficient Adaptation of Large-Scale Pre-Trained Language Models
Oct 08, 2022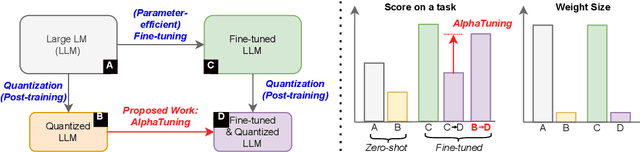

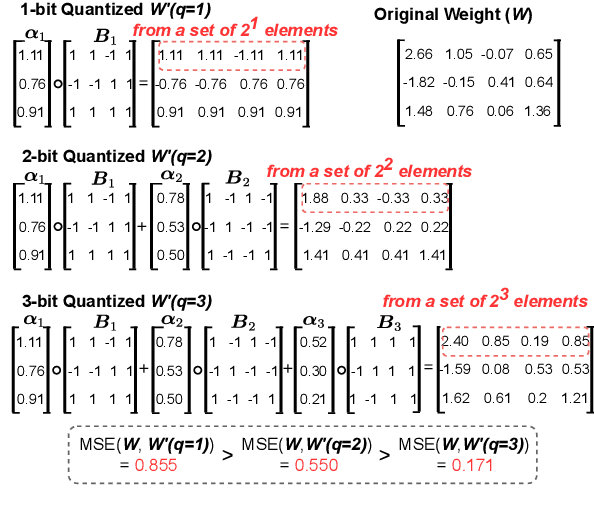
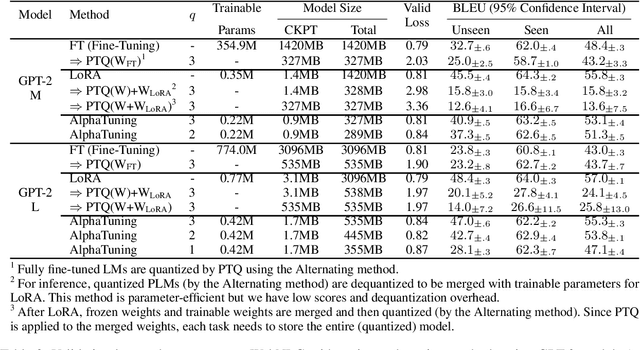
There are growing interests in adapting large-scale language models using parameter-efficient fine-tuning methods. However, accelerating the model itself and achieving better inference efficiency through model compression has not been thoroughly explored yet. Model compression could provide the benefits of reducing memory footprints, enabling low-precision computations, and ultimately achieving cost-effective inference. To combine parameter-efficient adaptation and model compression, we propose AlphaTuning consisting of post-training quantization of the pre-trained language model and fine-tuning only some parts of quantized parameters for a target task. Specifically, AlphaTuning works by employing binary-coding quantization, which factorizes the full-precision parameters into binary parameters and a separate set of scaling factors. During the adaptation phase, the binary values are frozen for all tasks, while the scaling factors are fine-tuned for the downstream task. We demonstrate that AlphaTuning, when applied to GPT-2 and OPT, performs competitively with full fine-tuning on a variety of downstream tasks while achieving >10x compression ratio under 4-bit quantization and >1,000x reduction in the number of trainable parameters.
nuQmm: Quantized MatMul for Efficient Inference of Large-Scale Generative Language Models
Jun 20, 2022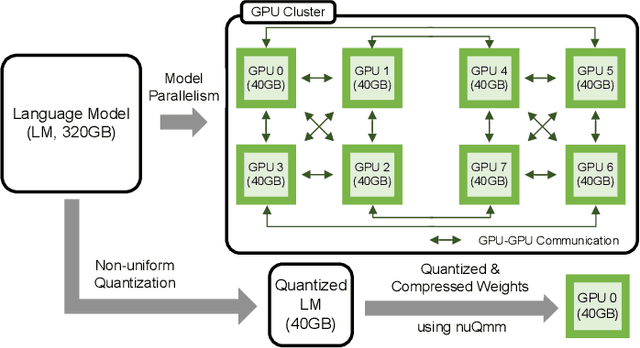
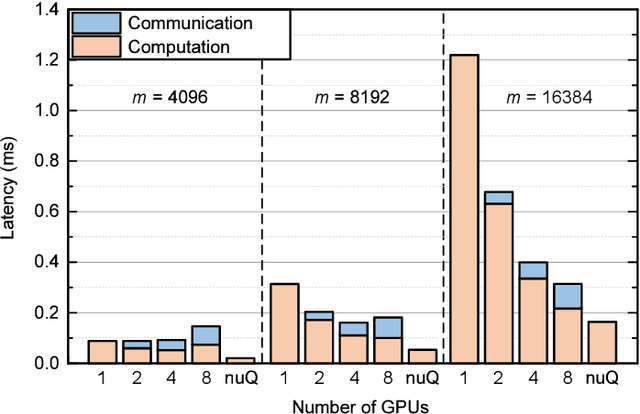
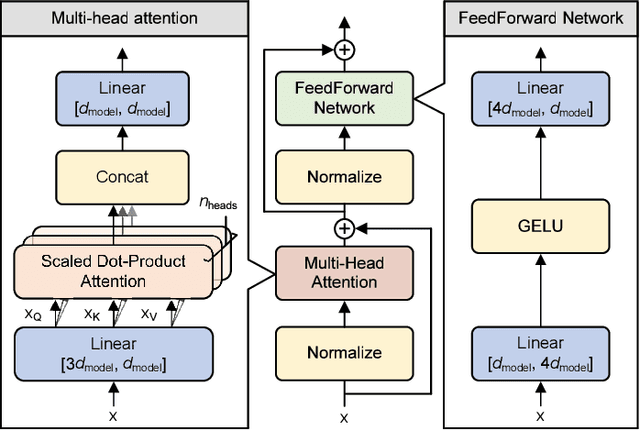
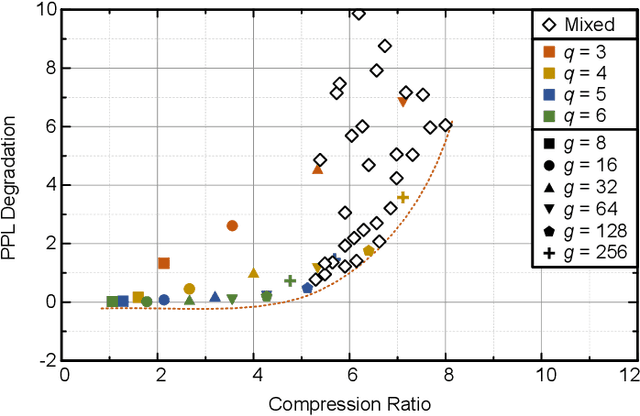
The recent advance of self-supervised learning associated with the Transformer architecture enables natural language processing (NLP) to exhibit extremely low perplexity. Such powerful models demand ever-increasing model size, and thus, large amounts of computations and memory footprints. In this paper, we propose an efficient inference framework for large-scale generative language models. As the key to reducing model size, we quantize weights by a non-uniform quantization method. Then, quantized matrix multiplications are accelerated by our proposed kernel, called nuQmm, which allows a wide trade-off between compression ratio and accuracy. Our proposed nuQmm reduces the latency of not only each GPU but also the entire inference of large LMs because a high compression ratio (by low-bit quantization) mitigates the minimum required number of GPUs. We demonstrate that nuQmm can accelerate the inference speed of the GPT-3 (175B) model by about 14.4 times and save energy consumption by 93%.
Modulating Regularization Frequency for Efficient Compression-Aware Model Training
May 05, 2021
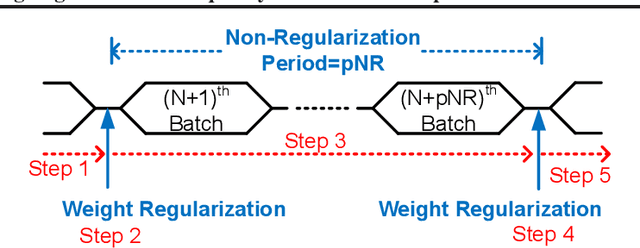

While model compression is increasingly important because of large neural network size, compression-aware training is challenging as it needs sophisticated model modifications and longer training time.In this paper, we introduce regularization frequency (i.e., how often compression is performed during training) as a new regularization technique for a practical and efficient compression-aware training method. For various regularization techniques, such as weight decay and dropout, optimizing the regularization strength is crucial to improve generalization in Deep Neural Networks (DNNs). While model compression also demands the right amount of regularization, the regularization strength incurred by model compression has been controlled only by compression ratio. Throughout various experiments, we show that regularization frequency critically affects the regularization strength of model compression. Combining regularization frequency and compression ratio, the amount of weight updates by model compression per mini-batch can be optimized to achieve the best model accuracy. Modulating regularization frequency is implemented by occasional model compression while conventional compression-aware training is usually performed for every mini-batch.
Sequential Encryption of Sparse Neural Networks Toward Optimum Representation of Irregular Sparsity
May 05, 2021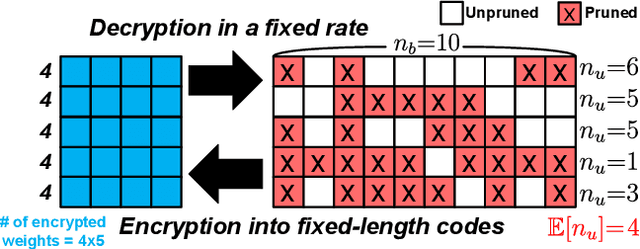
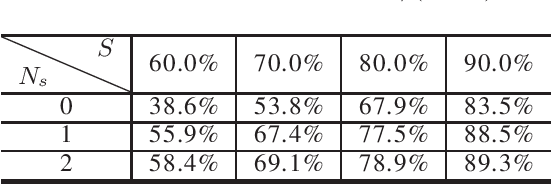
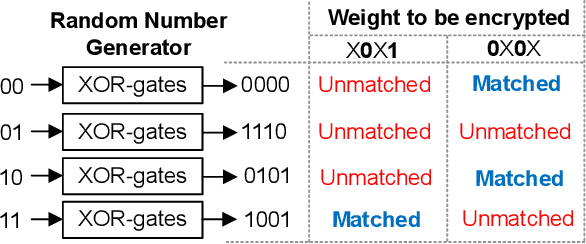
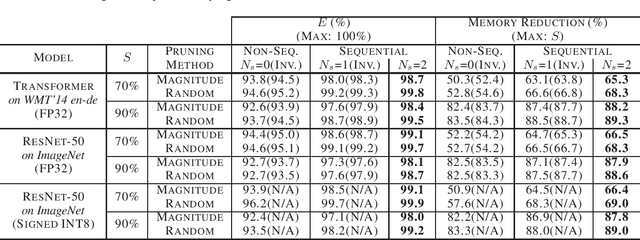
Even though fine-grained pruning techniques achieve a high compression ratio, conventional sparsity representations (such as CSR) associated with irregular sparsity degrade parallelism significantly. Practical pruning methods, thus, usually lower pruning rates (by structured pruning) to improve parallelism. In this paper, we study fixed-to-fixed (lossless) encryption architecture/algorithm to support fine-grained pruning methods such that sparse neural networks can be stored in a highly regular structure. We first estimate the maximum compression ratio of encryption-based compression using entropy. Then, as an effort to push the compression ratio to the theoretical maximum (by entropy), we propose a sequential fixed-to-fixed encryption scheme. We demonstrate that our proposed compression scheme achieves almost the maximum compression ratio for the Transformer and ResNet-50 pruned by various fine-grained pruning methods.
Q-Rater: Non-Convex Optimization for Post-Training Uniform Quantization
May 05, 2021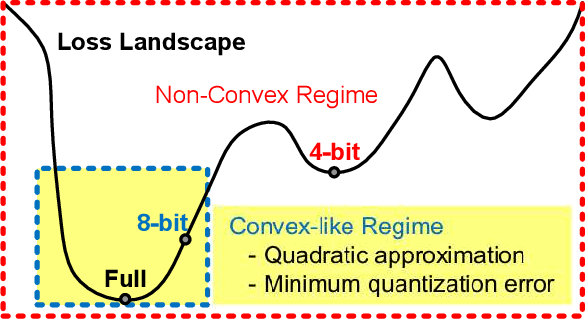
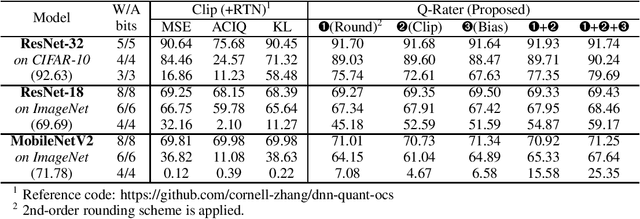
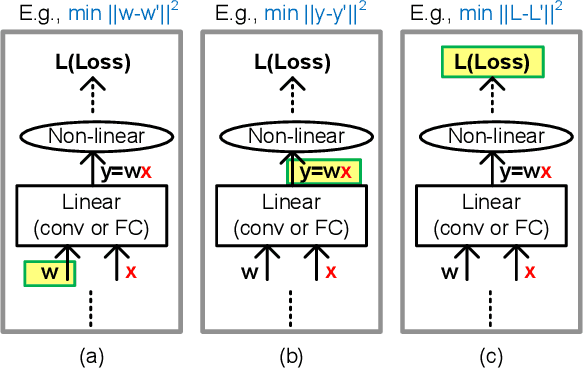
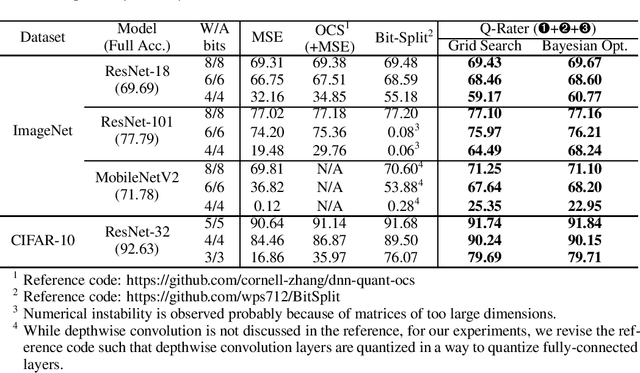
Various post-training uniform quantization methods have usually been studied based on convex optimization. As a result, most previous ones rely on the quantization error minimization and/or quadratic approximations. Such approaches are computationally efficient and reasonable when a large number of quantization bits are employed. When the number of quantization bits is relatively low, however, non-convex optimization is unavoidable to improve model accuracy. In this paper, we propose a new post-training uniform quantization technique considering non-convexity. We empirically show that hyper-parameters for clipping and rounding of weights and activations can be explored by monitoring task loss. Then, an optimally searched set of hyper-parameters is frozen to proceed to the next layer such that an incremental non-convex optimization is enabled for post-training quantization. Throughout extensive experimental results using various models, our proposed technique presents higher model accuracy, especially for a low-bit quantization.