 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding A Voice: Evaluating African American Dialect Generation for Chatbot Technology
Jan 07, 2025As chatbots become increasingly integrated into everyday tasks, designing systems that accommodate diverse user populations is crucial for fostering trust, engagement, and inclusivity. This study investigates the ability of contemporary Large Language Models (LLMs) to generate African American Vernacular English (AAVE) and evaluates the impact of AAVE usage on user experiences in chatbot applications. We analyze the performance of three LLM families (Llama, GPT, and Claude) in producing AAVE-like utterances at varying dialect intensities and assess user preferences across multiple domains, including healthcare and education. Despite LLMs' proficiency in generating AAVE-like language, findings indicate that AAVE-speaking users prefer Standard American English (SAE) chatbots, with higher levels of AAVE correlating with lower ratings for a variety of characteristics, including chatbot trustworthiness and role appropriateness. These results highlight the complexities of creating inclusive AI systems and underscore the need for further exploration of diversity to enhance human-computer interactions.
DropBP: Accelerating Fine-Tuning of Large Language Models by Dropping Backward Propagation
Feb 27, 2024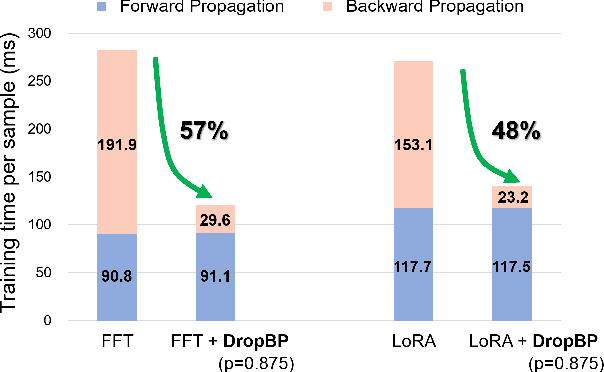

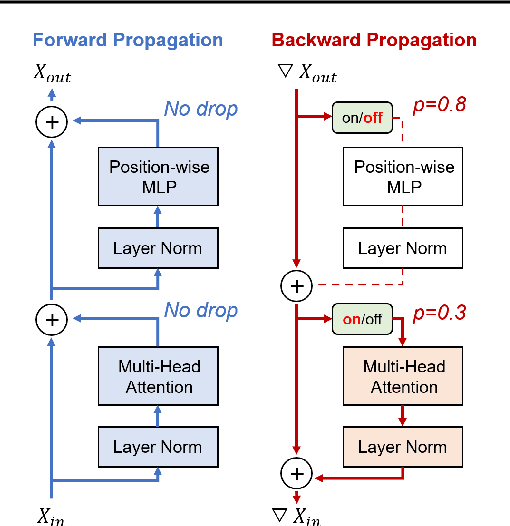

Training deep neural networks typically involves substantial computational costs during both forward and backward propagation. The conventional layer dropping techniques drop certain layers during training for reducing the computations burden. However, dropping layers during forward propagation adversely affects the training process by degrading accuracy. In this paper, we propose Dropping Backward Propagation (DropBP), a novel approach designed to reduce computational costs while maintaining accuracy. DropBP randomly drops layers during the backward propagation, which does not deviate forward propagation. Moreover, DropBP calculates the sensitivity of each layer to assign appropriate drop rate, thereby stabilizing the training process. DropBP is designed to enhance the efficiency of the training process with backpropagation, thereby enabling the acceleration of both full fine-tuning and parameter-efficient fine-tuning using backpropagation. Specifically, utilizing DropBP in QLoRA reduces training time by 44%, increases the convergence speed to the identical loss level by 1.5$\times$, and enables training with a 6.2$\times$ larger sequence length on a single NVIDIA-A100 80GiB GPU in LLaMA2-70B. The code is available at https://github.com/WooSunghyeon/dropbp.