 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrefillShare: A Shared Prefill Module for KV Reuse in Multi-LLM Disaggregated Serving
Feb 12, 2026Multi-agent systems increasingly orchestrate multiple specialized language models to solve complex real-world problems, often invoking them over a shared context. This execution pattern repeatedly processes the same prompt prefix across models. Consequently, each model redundantly executes the prefill stage and maintains its own key-value (KV) cache, increasing aggregate prefill load and worsening tail latency by intensifying prefill-decode interference in existing LLM serving stacks. Disaggregated serving reduces such interference by placing prefill and decode on separate GPUs, but disaggregation does not fundamentally eliminate inter-model redundancy in computation and KV storage for the same prompt. To address this issue, we propose PrefillShare, a novel algorithm that enables sharing the prefill stage across multiple models in a disaggregated setting. PrefillShare factorizes the model into prefill and decode modules, freezes the prefill module, and fine-tunes only the decode module. This design allows multiple task-specific models to share a prefill module and the KV cache generated for the same prompt. We further introduce a routing mechanism that enables effective prefill sharing across heterogeneous models in a vLLM-based disaggregated system. PrefillShare not only matches full fine-tuning accuracy on a broad range of tasks and models, but also delivers 4.5x lower p95 latency and 3.9x higher throughput in multi-model agent workloads.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
DropBP: Accelerating Fine-Tuning of Large Language Models by Dropping Backward Propagation
Feb 27, 2024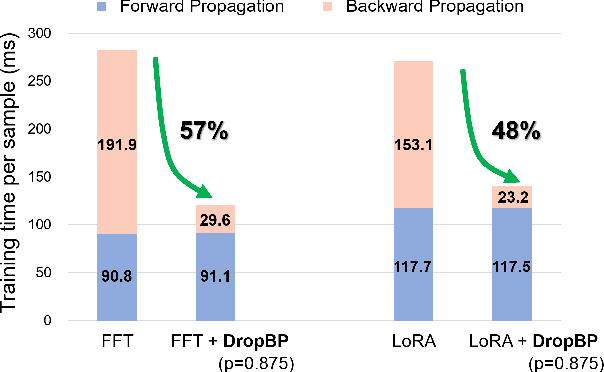

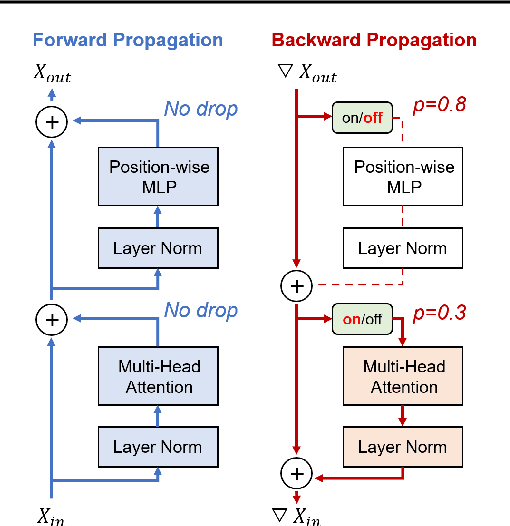

Training deep neural networks typically involves substantial computational costs during both forward and backward propagation. The conventional layer dropping techniques drop certain layers during training for reducing the computations burden. However, dropping layers during forward propagation adversely affects the training process by degrading accuracy. In this paper, we propose Dropping Backward Propagation (DropBP), a novel approach designed to reduce computational costs while maintaining accuracy. DropBP randomly drops layers during the backward propagation, which does not deviate forward propagation. Moreover, DropBP calculates the sensitivity of each layer to assign appropriate drop rate, thereby stabilizing the training process. DropBP is designed to enhance the efficiency of the training process with backpropagation, thereby enabling the acceleration of both full fine-tuning and parameter-efficient fine-tuning using backpropagation. Specifically, utilizing DropBP in QLoRA reduces training time by 44%, increases the convergence speed to the identical loss level by 1.5$\times$, and enables training with a 6.2$\times$ larger sequence length on a single NVIDIA-A100 80GiB GPU in LLaMA2-70B. The code is available at https://github.com/WooSunghyeon/dropbp.