 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Suboptimality of Deterministic Policy Gradients in Complex Q-functions
Oct 15, 2024



In reinforcement learning, off-policy actor-critic approaches like DDPG and TD3 are based on the deterministic policy gradient. Herein, the Q-function is trained from off-policy environment data and the actor (policy) is trained to maximize the Q-function via gradient ascent. We observe that in complex tasks like dexterous manipulation and restricted locomotion, the Q-value is a complex function of action, having several local optima or discontinuities. This poses a challenge for gradient ascent to traverse and makes the actor prone to get stuck at local optima. To address this, we introduce a new actor architecture that combines two simple insights: (i) use multiple actors and evaluate the Q-value maximizing action, and (ii) learn surrogates to the Q-function that are simpler to optimize with gradient-based methods. We evaluate tasks such as restricted locomotion, dexterous manipulation, and large discrete-action space recommender systems and show that our actor finds optimal actions more frequently and outperforms alternate actor architectures.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
A Scalable and Transferable Time Series Prediction Framework for Demand Forecasting
Feb 29, 2024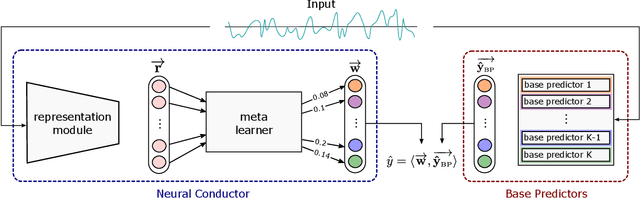



Time series forecasting is one of the most essential and ubiquitous tasks in many business problems, including demand forecasting and logistics optimization. Traditional time series forecasting methods, however, have resulted in small models with limited expressive power because they have difficulty in scaling their model size up while maintaining high accuracy. In this paper, we propose Forecasting orchestra (Forchestra), a simple but powerful framework capable of accurately predicting future demand for a diverse range of items. We empirically demonstrate that the model size is scalable to up to 0.8 billion parameters. The proposed method not only outperforms existing forecasting models with a significant margin, but it could generalize well to unseen data points when evaluated in a zero-shot fashion on downstream datasets. Last but not least, we present extensive qualitative and quantitative studies to analyze how the proposed model outperforms baseline models and differs from conventional approaches. The original paper was presented as a full paper at ICDM 2022 and is available at: https://ieeexplore.ieee.org/document/10027662.
Designing an offline reinforcement learning objective from scratch
Jan 30, 2023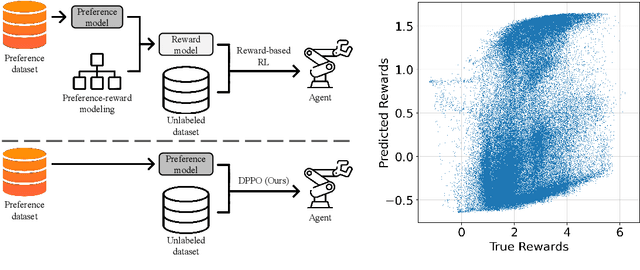
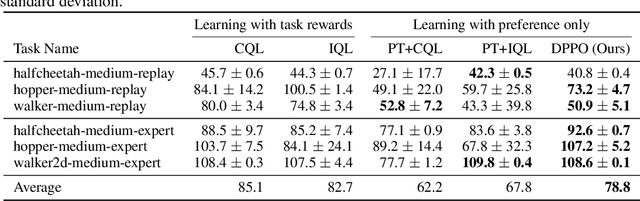
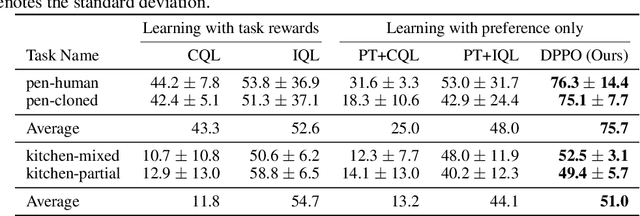
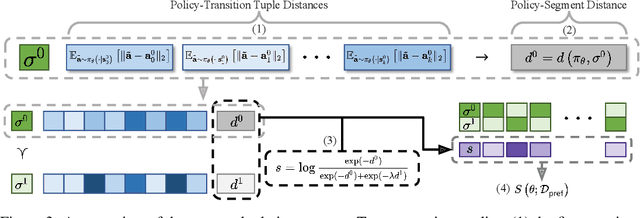
Offline reinforcement learning has developed rapidly over the recent years, but estimating the actual performance of offline policies still remains a challenge. We propose a scoring metric for offline policies that highly correlates with actual policy performance and can be directly used for offline policy optimization in a supervised manner. To achieve this, we leverage the contrastive learning framework to design a scoring metric that gives high scores to policies that imitate the actions yielding relatively high returns while avoiding those yielding relatively low returns. Our experiments show that 1) our scoring metric is able to more accurately rank offline policies and 2) the policies optimized using our metric show high performance on various offline reinforcement learning benchmarks. Notably, our algorithm has a much lower network capacity requirement for the policy network compared to other supervised learning-based methods and also does not need any additional networks such as a Q-network.
Pivotal Role of Language Modeling in Recommender Systems: Enriching Task-specific and Task-agnostic Representation Learning
Dec 13, 2022



Recent studies have proposed unified user modeling frameworks that leverage user behavior data from various applications. Many of them benefit from utilizing users' behavior sequences as plain texts, representing rich information in any domain or system without losing generality. Hence, a question arises: Can language modeling for user history corpus help improve recommender systems? While its versatile usability has been widely investigated in many domains, its applications to recommender systems still remain underexplored. We show that language modeling applied directly to task-specific user histories achieves excellent results on diverse recommendation tasks. Also, leveraging additional task-agnostic user histories delivers significant performance benefits. We further demonstrate that our approach can provide promising transfer learning capabilities for a broad spectrum of real-world recommender systems, even on unseen domains and services.
Ask Me What You Need: Product Retrieval using Knowledge from GPT-3
Jul 06, 2022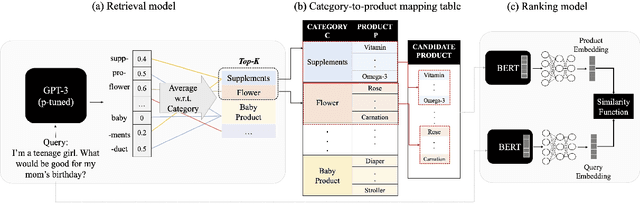
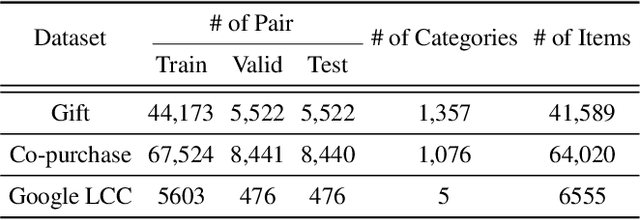
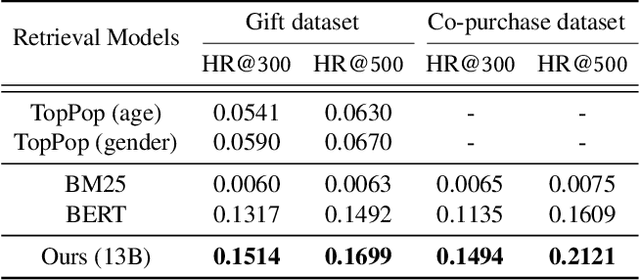
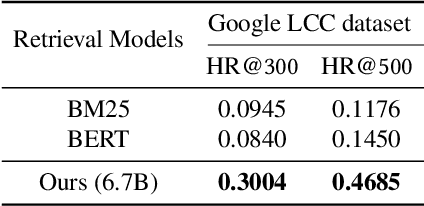
As online merchandise become more common, many studies focus on embedding-based methods where queries and products are represented in the semantic space. These methods alleviate the problem of vocab mismatch between the language of queries and products. However, past studies usually dealt with queries that precisely describe the product, and there still exists the need to answer imprecise queries that may require common sense knowledge, i.e., 'what should I get my mom for Mother's Day.' In this paper, we propose a GPT-3 based product retrieval system that leverages the knowledge-base (KB) of GPT-3 for question answering; users do not need to know the specific illustrative keywords for a product when querying. Our method tunes prompt tokens of GPT-3 to prompt knowledge and render answers that are mapped directly to products without further processing. Our method shows consistent performance improvement on two real-world and one public dataset, compared to the baseline methods. We provide an in-depth discussion on leveraging GPT-3 knowledge into a question answering based retrieval system.
Deformable Graph Transformer
Jun 29, 2022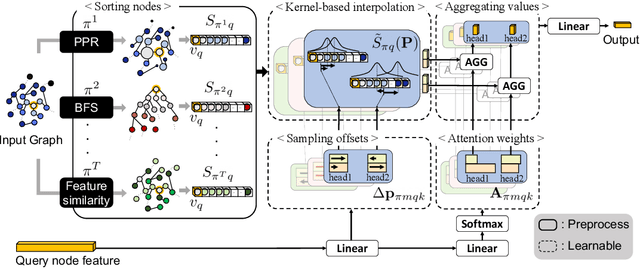
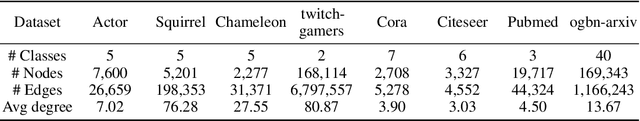
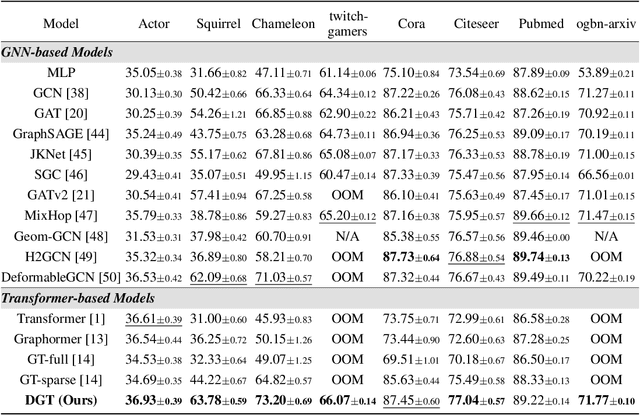
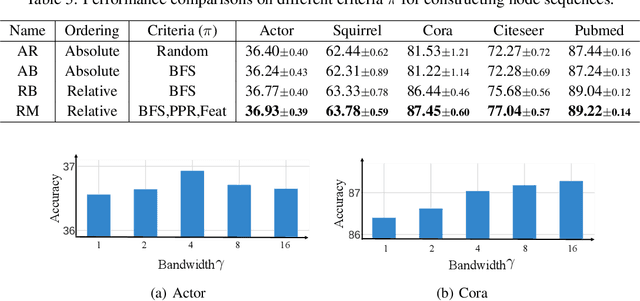
Transformer-based models have been widely used and achieved state-of-the-art performance in various domains such as natural language processing and computer vision. Recent works show that Transformers can also be generalized to graph-structured data. However, the success is limited to small-scale graphs due to technical challenges such as the quadratic complexity in regards to the number of nodes and non-local aggregation that often leads to inferior generalization performance to conventional graph neural networks. In this paper, to address these issues, we propose Deformable Graph Transformer (DGT) that performs sparse attention with dynamically sampled key and value pairs. Specifically, our framework first constructs multiple node sequences with various criteria to consider both structural and semantic proximity. Then, the sparse attention is applied to the node sequences for learning node representations with a reduced computational cost. We also design simple and effective positional encodings to capture structural similarity and distance between nodes. Experiments demonstrate that our novel graph Transformer consistently outperforms existing Transformer-based models and shows competitive performance compared to state-of-the-art models on 8 graph benchmark datasets including large-scale graphs.
VQ-AR: Vector Quantized Autoregressive Probabilistic Time Series Forecasting
May 31, 2022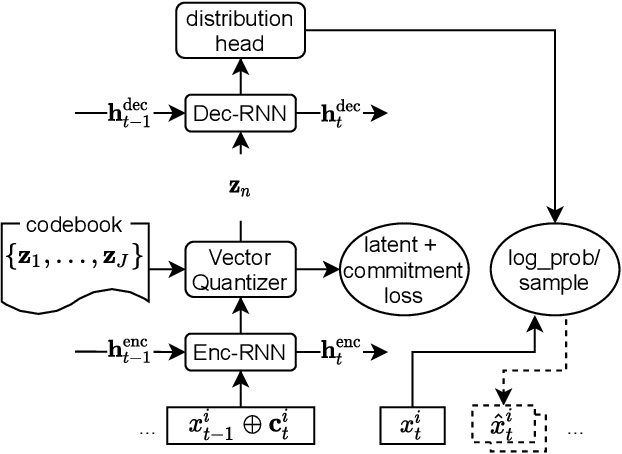
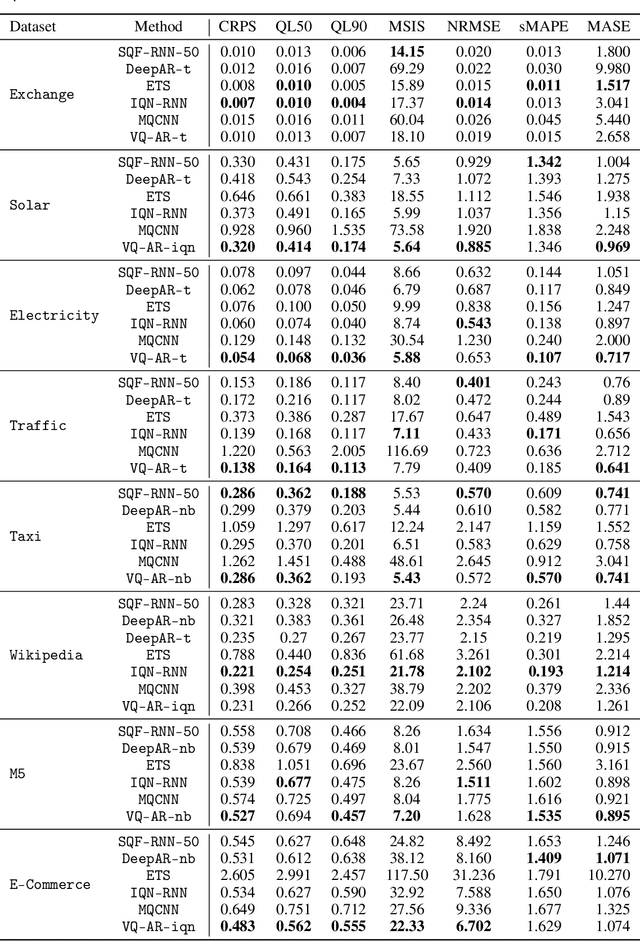
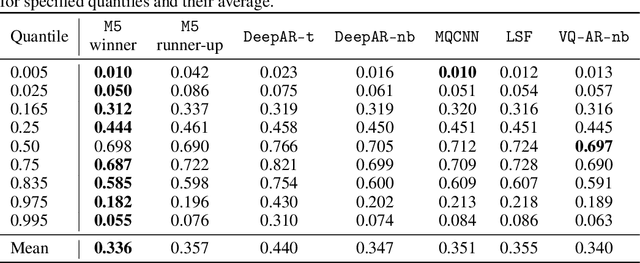
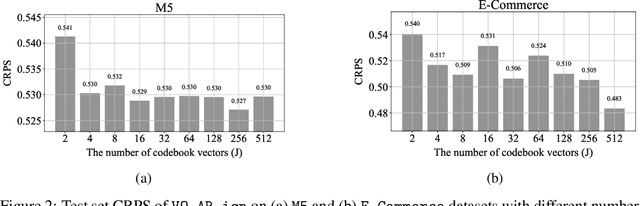
Time series models aim for accurate predictions of the future given the past, where the forecasts are used for important downstream tasks like business decision making. In practice, deep learning based time series models come in many forms, but at a high level learn some continuous representation of the past and use it to output point or probabilistic forecasts. In this paper, we introduce a novel autoregressive architecture, VQ-AR, which instead learns a \emph{discrete} set of representations that are used to predict the future. Extensive empirical comparison with other competitive deep learning models shows that surprisingly such a discrete set of representations gives state-of-the-art or equivalent results on a wide variety of time series datasets. We also highlight the shortcomings of this approach, explore its zero-shot generalization capabilities, and present an ablation study on the number of representations. The full source code of the method will be available at the time of publication with the hope that researchers can further investigate this important but overlooked inductive bias for the time series domain.
Hazard Gradient Penalty for Survival Analysis
May 27, 2022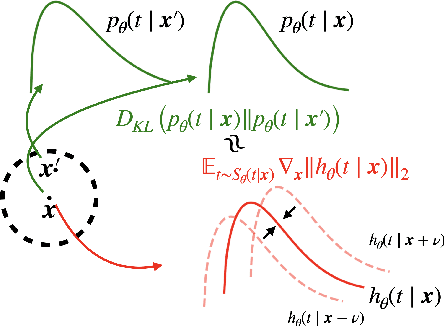

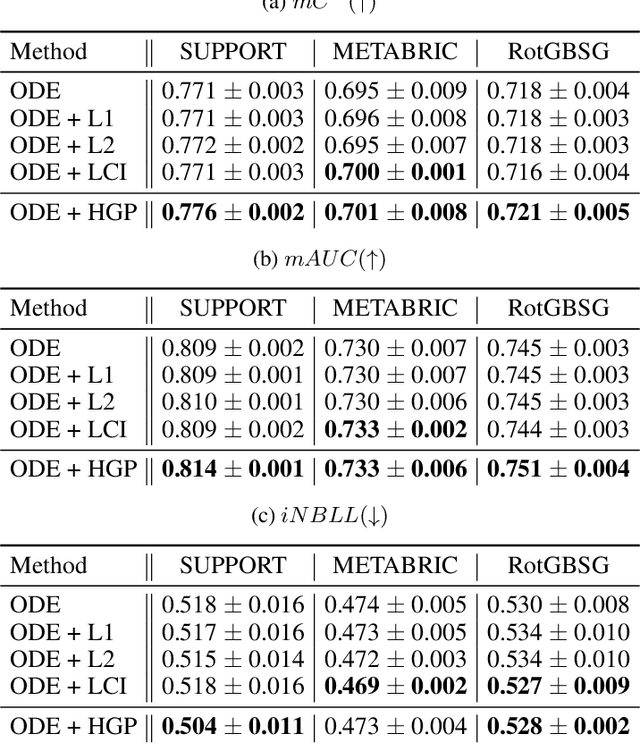
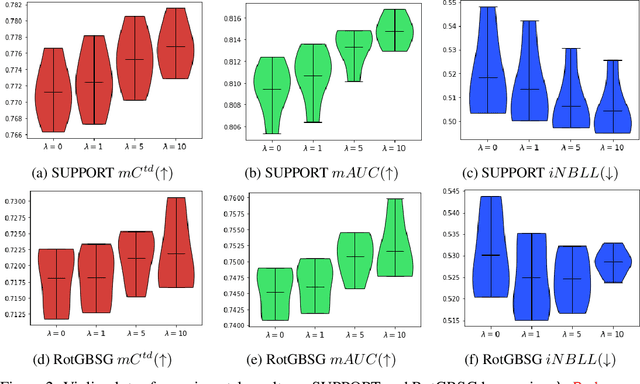
Survival analysis appears in various fields such as medicine, economics, engineering, and business. Recent studies showed that the Ordinary Differential Equation (ODE) modeling framework unifies many existing survival models while the framework is flexible and widely applicable. However, naively applying the ODE framework to survival analysis problems may model fiercely changing density function which may worsen the model's performance. Though we can apply L1 or L2 regularizers to the ODE model, their effect on the ODE modeling framework is barely known. In this paper, we propose hazard gradient penalty (HGP) to enhance the performance of a survival analysis model. Our method imposes constraints on local data points by regularizing the gradient of hazard function with respect to the data point. Our method applies to any survival analysis model including the ODE modeling framework and is easy to implement. We theoretically show that our method is related to minimizing the KL divergence between the density function at a data point and that of the neighborhood points. Experimental results on three public benchmarks show that our approach outperforms other regularization methods.
Metropolis-Hastings Data Augmentation for Graph Neural Networks
Mar 26, 2022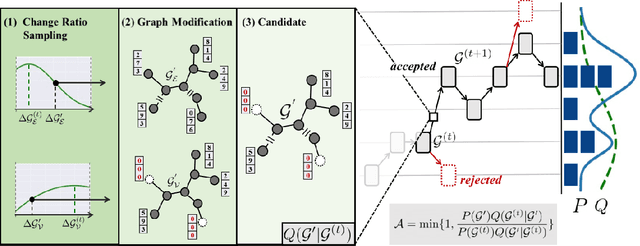
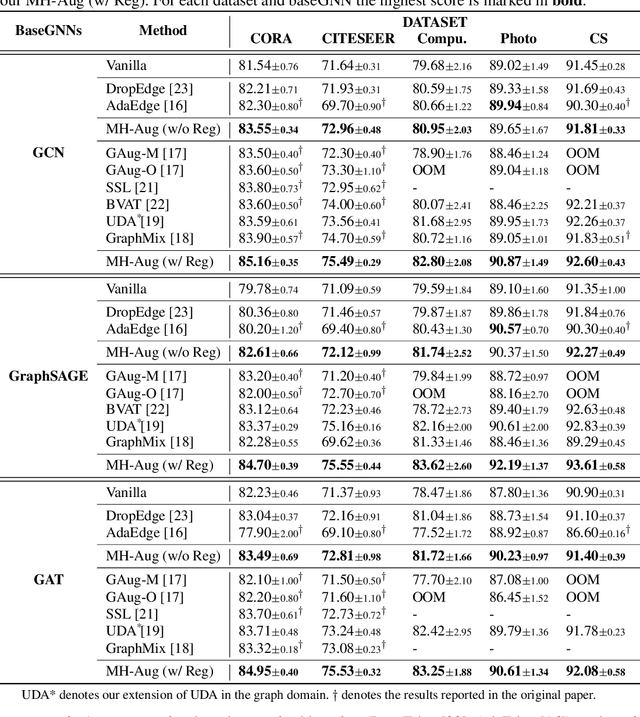
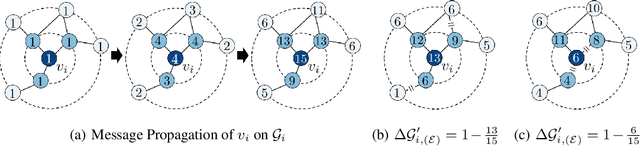
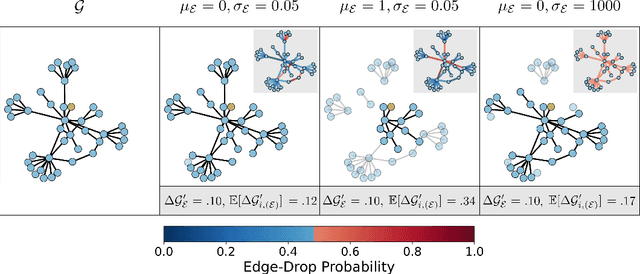
Graph Neural Networks (GNNs) often suffer from weak-generalization due to sparsely labeled data despite their promising results on various graph-based tasks. Data augmentation is a prevalent remedy to improve the generalization ability of models in many domains. However, due to the non-Euclidean nature of data space and the dependencies between samples, designing effective augmentation on graphs is challenging. In this paper, we propose a novel framework Metropolis-Hastings Data Augmentation (MH-Aug) that draws augmented graphs from an explicit target distribution for semi-supervised learning. MH-Aug produces a sequence of augmented graphs from the target distribution enables flexible control of the strength and diversity of augmentation. Since the direct sampling from the complex target distribution is challenging, we adopt the Metropolis-Hastings algorithm to obtain the augmented samples. We also propose a simple and effective semi-supervised learning strategy with generated samples from MH-Aug. Our extensive experiments demonstrate that MH-Aug can generate a sequence of samples according to the target distribution to significantly improve the performance of GNNs.