 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeformable Graph Transformer
Jun 29, 2022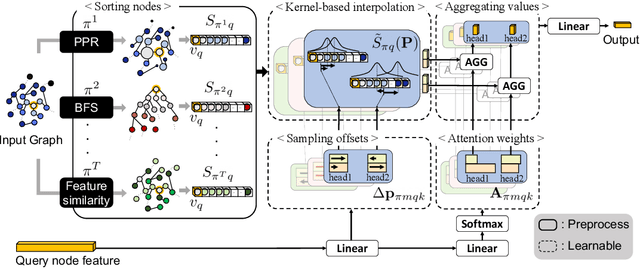
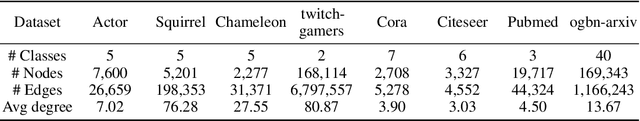
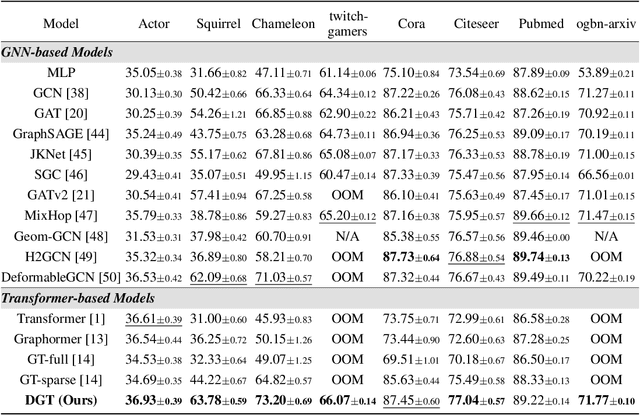
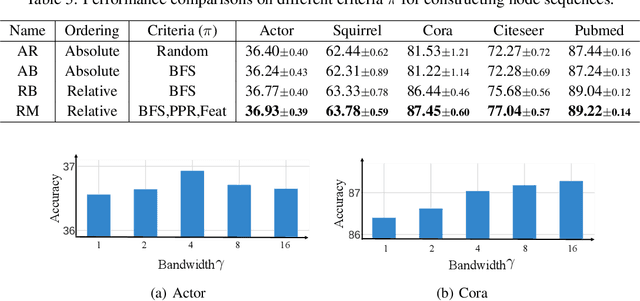
Transformer-based models have been widely used and achieved state-of-the-art performance in various domains such as natural language processing and computer vision. Recent works show that Transformers can also be generalized to graph-structured data. However, the success is limited to small-scale graphs due to technical challenges such as the quadratic complexity in regards to the number of nodes and non-local aggregation that often leads to inferior generalization performance to conventional graph neural networks. In this paper, to address these issues, we propose Deformable Graph Transformer (DGT) that performs sparse attention with dynamically sampled key and value pairs. Specifically, our framework first constructs multiple node sequences with various criteria to consider both structural and semantic proximity. Then, the sparse attention is applied to the node sequences for learning node representations with a reduced computational cost. We also design simple and effective positional encodings to capture structural similarity and distance between nodes. Experiments demonstrate that our novel graph Transformer consistently outperforms existing Transformer-based models and shows competitive performance compared to state-of-the-art models on 8 graph benchmark datasets including large-scale graphs.