 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch Transformer: Look for Attention in Batch
Jul 05, 2024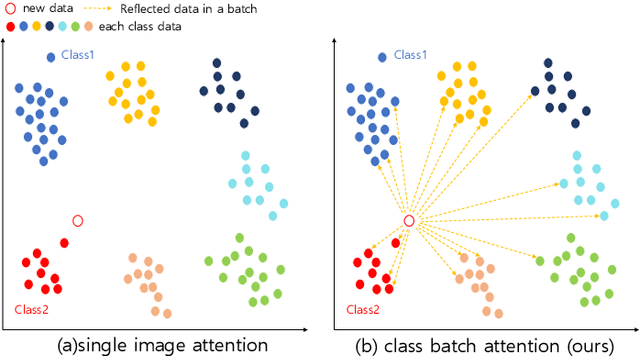
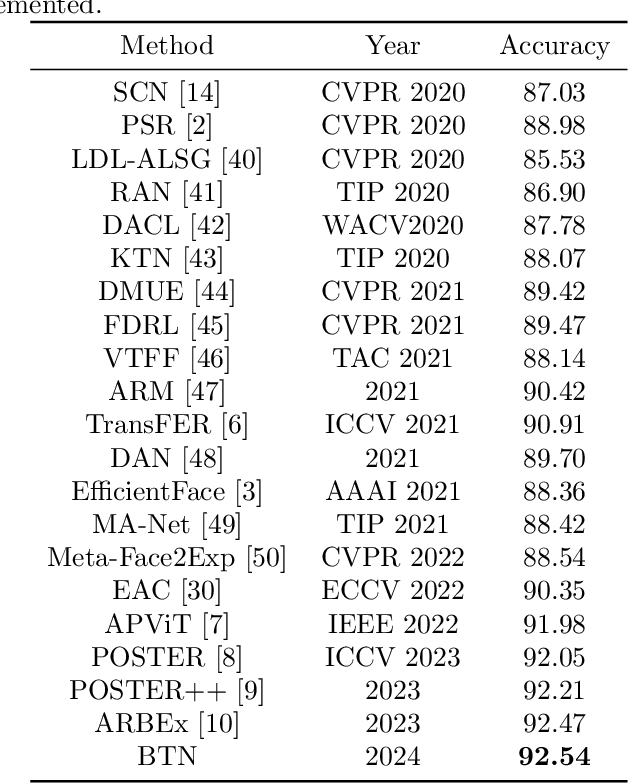
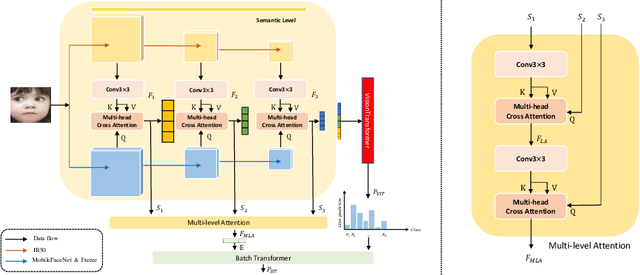
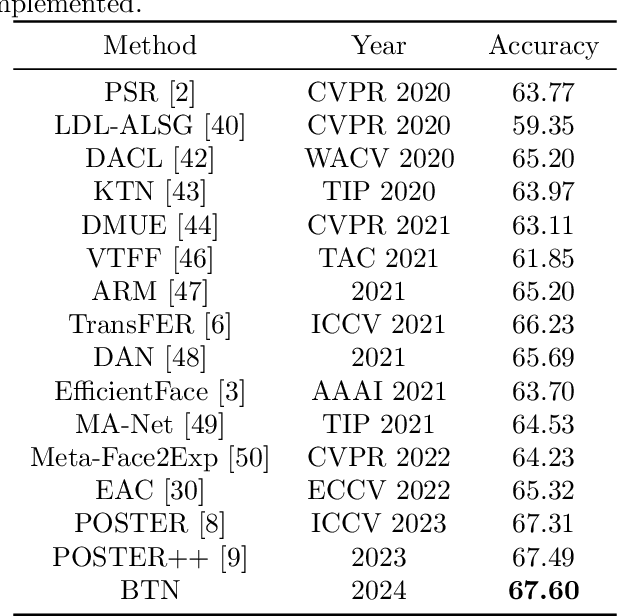
Facial expression recognition (FER) has received considerable attention in computer vision, with "in-the-wild" environments such as human-computer interaction. However, FER images contain uncertainties such as occlusion, low resolution, pose variation, illumination variation, and subjectivity, which includes some expressions that do not match the target label. Consequently, little information is obtained from a noisy single image and it is not trusted. This could significantly degrade the performance of the FER task. To address this issue, we propose a batch transformer (BT), which consists of the proposed class batch attention (CBA) module, to prevent overfitting in noisy data and extract trustworthy information by training on features reflected from several images in a batch, rather than information from a single image. We also propose multi-level attention (MLA) to prevent overfitting the specific features by capturing correlations between each level. In this paper, we present a batch transformer network (BTN) that combines the above proposals. Experimental results on various FER benchmark datasets show that the proposed BTN consistently outperforms the state-ofthe-art in FER datasets. Representative results demonstrate the promise of the proposed BTN for FER.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Pivotal Role of Language Modeling in Recommender Systems: Enriching Task-specific and Task-agnostic Representation Learning
Dec 13, 2022



Recent studies have proposed unified user modeling frameworks that leverage user behavior data from various applications. Many of them benefit from utilizing users' behavior sequences as plain texts, representing rich information in any domain or system without losing generality. Hence, a question arises: Can language modeling for user history corpus help improve recommender systems? While its versatile usability has been widely investigated in many domains, its applications to recommender systems still remain underexplored. We show that language modeling applied directly to task-specific user histories achieves excellent results on diverse recommendation tasks. Also, leveraging additional task-agnostic user histories delivers significant performance benefits. We further demonstrate that our approach can provide promising transfer learning capabilities for a broad spectrum of real-world recommender systems, even on unseen domains and services.
Relation-aware Language-Graph Transformer for Question Answering
Dec 02, 2022



Question Answering (QA) is a task that entails reasoning over natural language contexts, and many relevant works augment language models (LMs) with graph neural networks (GNNs) to encode the Knowledge Graph (KG) information. However, most existing GNN-based modules for QA do not take advantage of rich relational information of KGs and depend on limited information interaction between the LM and the KG. To address these issues, we propose Question Answering Transformer (QAT), which is designed to jointly reason over language and graphs with respect to entity relations in a unified manner. Specifically, QAT constructs Meta-Path tokens, which learn relation-centric embeddings based on diverse structural and semantic relations. Then, our Relation-Aware Self-Attention module comprehensively integrates different modalities via the Cross-Modal Relative Position Bias, which guides information exchange between relevant entities of different modalities. We validate the effectiveness of QAT on commonsense question answering datasets like CommonsenseQA and OpenBookQA, and on a medical question answering dataset, MedQA-USMLE. On all the datasets, our method achieves state-of-the-art performance. Our code is available at http://github.com/mlvlab/QAT.
Meta-node: A Concise Approach to Effectively Learn Complex Relationships in Heterogeneous Graphs
Oct 26, 2022



Existing message passing neural networks for heterogeneous graphs rely on the concepts of meta-paths or meta-graphs due to the intrinsic nature of heterogeneous graphs. However, the meta-paths and meta-graphs need to be pre-configured before learning and are highly dependent on expert knowledge to construct them. To tackle this challenge, we propose a novel concept of meta-node for message passing that can learn enriched relational knowledge from complex heterogeneous graphs without any meta-paths and meta-graphs by explicitly modeling the relations among the same type of nodes. Unlike meta-paths and meta-graphs, meta-nodes do not require any pre-processing steps that require expert knowledge. Going one step further, we propose a meta-node message passing scheme and apply our method to a contrastive learning model. In the experiments on node clustering and classification tasks, the proposed meta-node message passing method outperforms state-of-the-arts that depend on meta-paths. Our results demonstrate that effective heterogeneous graph learning is possible without the need for meta-paths that are frequently used in this field.
Deformable Graph Transformer
Jun 29, 2022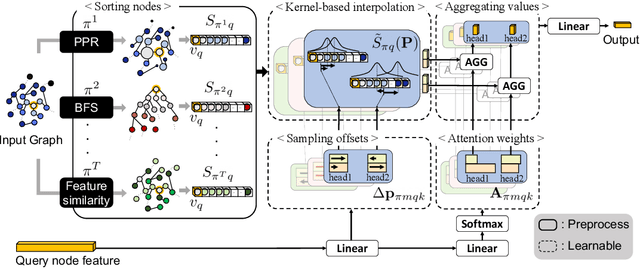
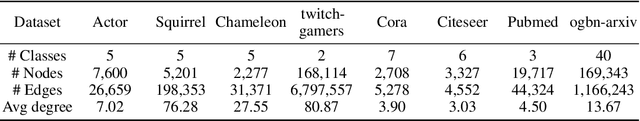
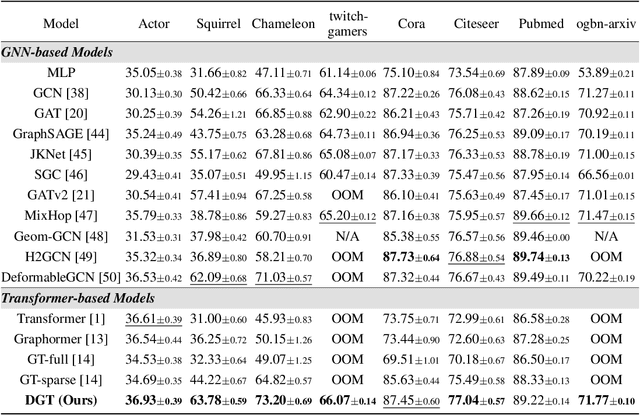
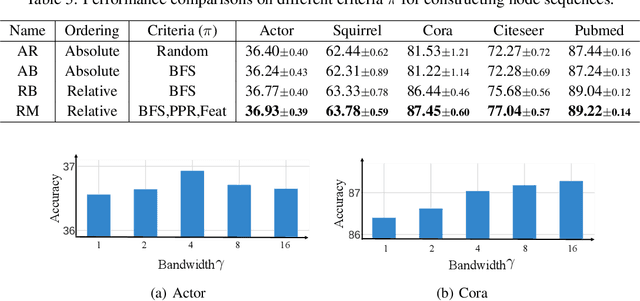
Transformer-based models have been widely used and achieved state-of-the-art performance in various domains such as natural language processing and computer vision. Recent works show that Transformers can also be generalized to graph-structured data. However, the success is limited to small-scale graphs due to technical challenges such as the quadratic complexity in regards to the number of nodes and non-local aggregation that often leads to inferior generalization performance to conventional graph neural networks. In this paper, to address these issues, we propose Deformable Graph Transformer (DGT) that performs sparse attention with dynamically sampled key and value pairs. Specifically, our framework first constructs multiple node sequences with various criteria to consider both structural and semantic proximity. Then, the sparse attention is applied to the node sequences for learning node representations with a reduced computational cost. We also design simple and effective positional encodings to capture structural similarity and distance between nodes. Experiments demonstrate that our novel graph Transformer consistently outperforms existing Transformer-based models and shows competitive performance compared to state-of-the-art models on 8 graph benchmark datasets including large-scale graphs.
Metropolis-Hastings Data Augmentation for Graph Neural Networks
Mar 26, 2022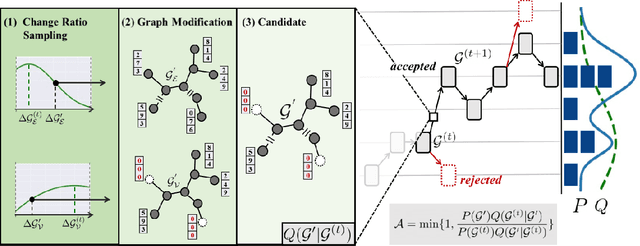
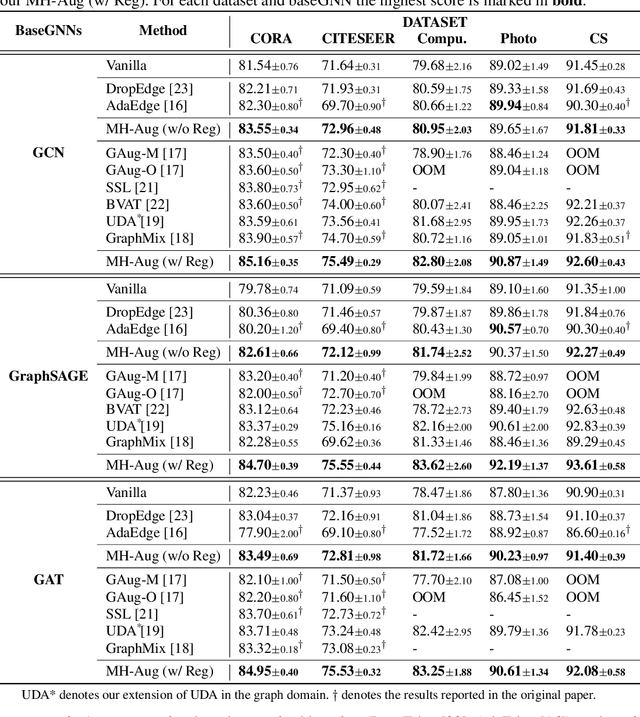
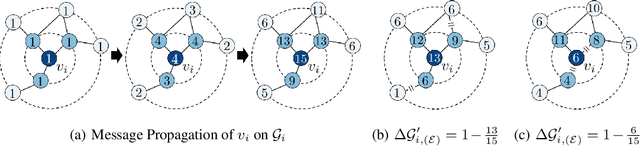
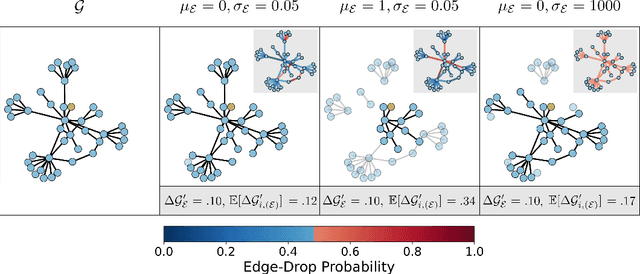
Graph Neural Networks (GNNs) often suffer from weak-generalization due to sparsely labeled data despite their promising results on various graph-based tasks. Data augmentation is a prevalent remedy to improve the generalization ability of models in many domains. However, due to the non-Euclidean nature of data space and the dependencies between samples, designing effective augmentation on graphs is challenging. In this paper, we propose a novel framework Metropolis-Hastings Data Augmentation (MH-Aug) that draws augmented graphs from an explicit target distribution for semi-supervised learning. MH-Aug produces a sequence of augmented graphs from the target distribution enables flexible control of the strength and diversity of augmentation. Since the direct sampling from the complex target distribution is challenging, we adopt the Metropolis-Hastings algorithm to obtain the augmented samples. We also propose a simple and effective semi-supervised learning strategy with generated samples from MH-Aug. Our extensive experiments demonstrate that MH-Aug can generate a sequence of samples according to the target distribution to significantly improve the performance of GNNs.
Scaling Law for Recommendation Models: Towards General-purpose User Representations
Dec 01, 2021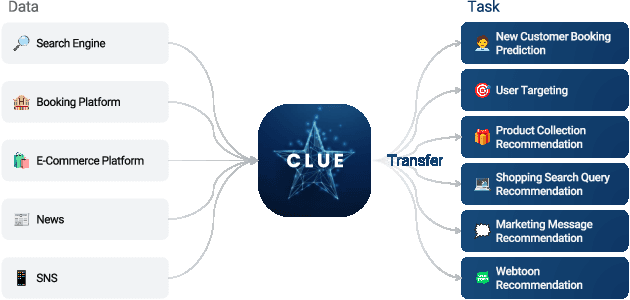
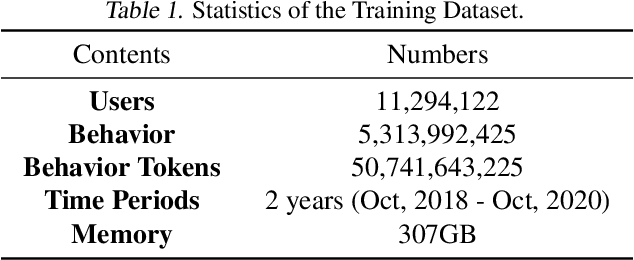
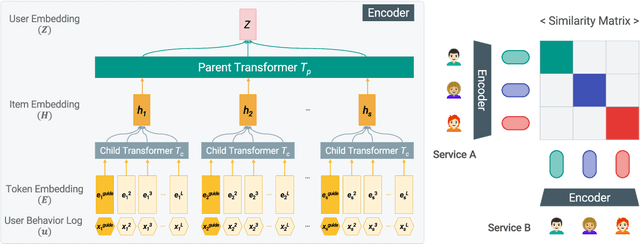

A recent trend shows that a general class of models, e.g., BERT, GPT-3, CLIP, trained on broad data at scale have shown a great variety of functionalities with a single learning architecture. In this work, we explore the possibility of general-purpose user representation learning by training a universal user encoder at large scales. We demonstrate that the scaling law holds in the user modeling areas, where the training error scales as a power-law with the amount of compute. Our Contrastive Learning User Encoder (CLUE), optimizes task-agnostic objectives, and the resulting user embeddings stretches our expectation of what is possible to do in various downstream tasks. CLUE also shows great transferability to other domains and systems, as performances on an online experiment shows significant improvements in online Click-Through-Rate (CTR). Furthermore, we also investigate how the performance changes according to the scale-up factors, i.e., model capacity, sequence length and batch size. Finally, we discuss the broader impacts of CLUE in general.
Intent-based Product Collections for E-commerce using Pretrained Language Models
Oct 15, 2021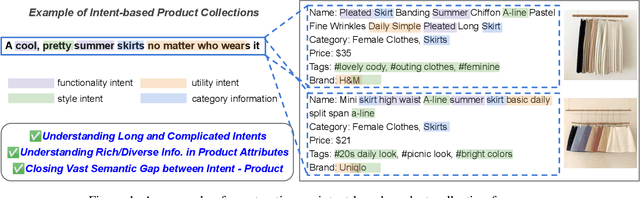
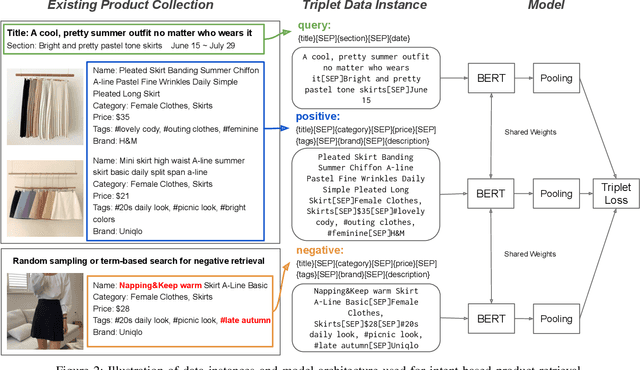
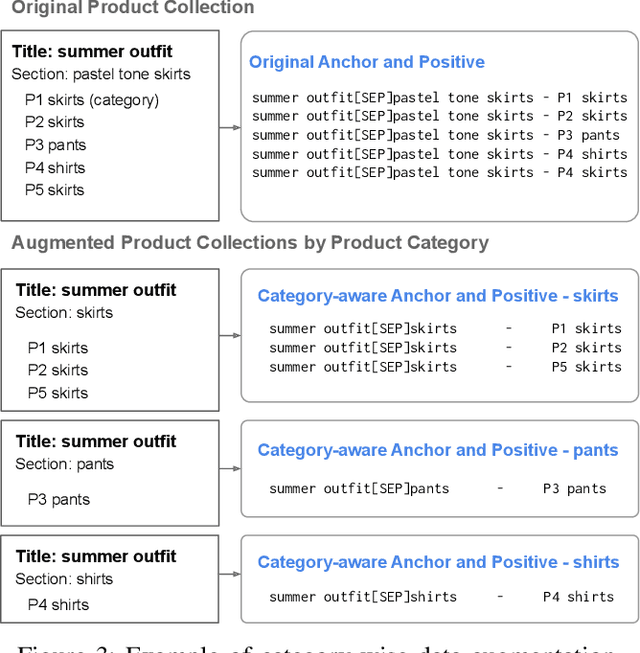
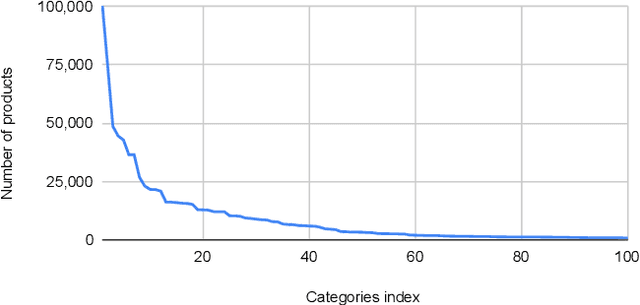
Building a shopping product collection has been primarily a human job. With the manual efforts of craftsmanship, experts collect related but diverse products with common shopping intent that are effective when displayed together, e.g., backpacks, laptop bags, and messenger bags for freshman bag gifts. Automatically constructing a collection requires an ML system to learn a complex relationship between the customer's intent and the product's attributes. However, there have been challenging points, such as 1) long and complicated intent sentences, 2) rich and diverse product attributes, and 3) a huge semantic gap between them, making the problem difficult. In this paper, we use a pretrained language model (PLM) that leverages textual attributes of web-scale products to make intent-based product collections. Specifically, we train a BERT with triplet loss by setting an intent sentence to an anchor and corresponding products to positive examples. Also, we improve the performance of the model by search-based negative sampling and category-wise positive pair augmentation. Our model significantly outperforms the search-based baseline model for intent-based product matching in offline evaluations. Furthermore, online experimental results on our e-commerce platform show that the PLM-based method can construct collections of products with increased CTR, CVR, and order-diversity compared to expert-crafted collections.
What Changes Can Large-scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-scale Korean Generative Pretrained Transformers
Sep 10, 2021

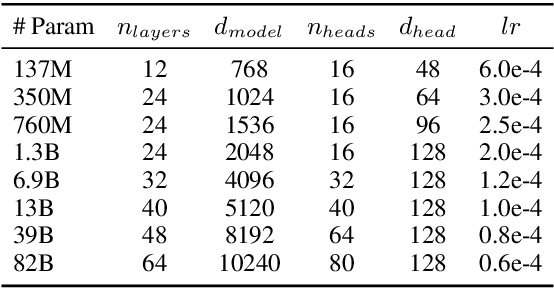
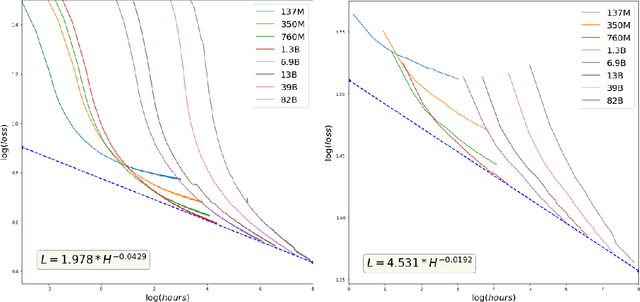
GPT-3 shows remarkable in-context learning ability of large-scale language models (LMs) trained on hundreds of billion scale data. Here we address some remaining issues less reported by the GPT-3 paper, such as a non-English LM, the performances of different sized models, and the effect of recently introduced prompt optimization on in-context learning. To achieve this, we introduce HyperCLOVA, a Korean variant of 82B GPT-3 trained on a Korean-centric corpus of 560B tokens. Enhanced by our Korean-specific tokenization, HyperCLOVA with our training configuration shows state-of-the-art in-context zero-shot and few-shot learning performances on various downstream tasks in Korean. Also, we show the performance benefits of prompt-based learning and demonstrate how it can be integrated into the prompt engineering pipeline. Then we discuss the possibility of materializing the No Code AI paradigm by providing AI prototyping capabilities to non-experts of ML by introducing HyperCLOVA studio, an interactive prompt engineering interface. Lastly, we demonstrate the potential of our methods with three successful in-house applications.