 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Efficient Fine-Tuning Diffusion Transformers via Dynamic Patch Sampling and Block Skipping
Mar 21, 2026Diffusion Transformers (DiTs) have significantly enhanced text-to-image (T2I) generation quality, enabling high-quality personalized content creation. However, fine-tuning these models requires substantial computational complexity and memory, limiting practical deployment under resource constraints. To tackle these challenges, we propose a memory-efficient fine-tuning framework called DiT-BlockSkip, integrating timestep-aware dynamic patch sampling and block skipping by precomputing residual features. Our dynamic patch sampling strategy adjusts patch sizes based on the diffusion timestep, then resizes the cropped patches to a fixed lower resolution. This approach reduces forward & backward memory usage while allowing the model to capture global structures at higher timesteps and fine-grained details at lower timesteps. The block skipping mechanism selectively fine-tunes essential transformer blocks and precomputes residual features for the skipped blocks, significantly reducing training memory. To identify vital blocks for personalization, we introduce a block selection strategy based on cross-attention masking. Evaluations demonstrate that our approach achieves competitive personalization performance qualitatively and quantitatively, while reducing memory usage substantially, moving toward on-device feasibility (e.g., smartphones, IoT devices) for large-scale diffusion transformers.
Steering Guidance for Personalized Text-to-Image Diffusion Models
Aug 01, 2025Personalizing text-to-image diffusion models is crucial for adapting the pre-trained models to specific target concepts, enabling diverse image generation. However, fine-tuning with few images introduces an inherent trade-off between aligning with the target distribution (e.g., subject fidelity) and preserving the broad knowledge of the original model (e.g., text editability). Existing sampling guidance methods, such as classifier-free guidance (CFG) and autoguidance (AG), fail to effectively guide the output toward well-balanced space: CFG restricts the adaptation to the target distribution, while AG compromises text alignment. To address these limitations, we propose personalization guidance, a simple yet effective method leveraging an unlearned weak model conditioned on a null text prompt. Moreover, our method dynamically controls the extent of unlearning in a weak model through weight interpolation between pre-trained and fine-tuned models during inference. Unlike existing guidance methods, which depend solely on guidance scales, our method explicitly steers the outputs toward a balanced latent space without additional computational overhead. Experimental results demonstrate that our proposed guidance can improve text alignment and target distribution fidelity, integrating seamlessly with various fine-tuning strategies.
MultiHuman-Testbench: Benchmarking Image Generation for Multiple Humans
Jun 25, 2025Generation of images containing multiple humans, performing complex actions, while preserving their facial identities, is a significant challenge. A major factor contributing to this is the lack of a a dedicated benchmark. To address this, we introduce MultiHuman-Testbench, a novel benchmark for rigorously evaluating generative models for multi-human generation. The benchmark comprises 1800 samples, including carefully curated text prompts, describing a range of simple to complex human actions. These prompts are matched with a total of 5,550 unique human face images, sampled uniformly to ensure diversity across age, ethnic background, and gender. Alongside captions, we provide human-selected pose conditioning images which accurately match the prompt. We propose a multi-faceted evaluation suite employing four key metrics to quantify face count, ID similarity, prompt alignment, and action detection. We conduct a thorough evaluation of a diverse set of models, including zero-shot approaches and training-based methods, with and without regional priors. We also propose novel techniques to incorporate image and region isolation using human segmentation and Hungarian matching, significantly improving ID similarity. Our proposed benchmark and key findings provide valuable insights and a standardized tool for advancing research in multi-human image generation.
Concept-Aware LoRA for Domain-Aligned Segmentation Dataset Generation
Mar 28, 2025This paper addresses the challenge of data scarcity in semantic segmentation by generating datasets through text-to-image (T2I) generation models, reducing image acquisition and labeling costs. Segmentation dataset generation faces two key challenges: 1) aligning generated samples with the target domain and 2) producing informative samples beyond the training data. Fine-tuning T2I models can help generate samples aligned with the target domain. However, it often overfits and memorizes training data, limiting their ability to generate diverse and well-aligned samples. To overcome these issues, we propose Concept-Aware LoRA (CA-LoRA), a novel fine-tuning approach that selectively identifies and updates only the weights associated with necessary concepts (e.g., style or viewpoint) for domain alignment while preserving the pretrained knowledge of the T2I model to produce informative samples. We demonstrate its effectiveness in generating datasets for urban-scene segmentation, outperforming baseline and state-of-the-art methods in in-domain (few-shot and fully-supervised) settings, as well as in domain generalization tasks, especially under challenging conditions such as adverse weather and varying illumination, further highlighting its superiority.
PromptDresser: Improving the Quality and Controllability of Virtual Try-On via Generative Textual Prompt and Prompt-aware Mask
Dec 22, 2024Recent virtual try-on approaches have advanced by fine-tuning the pre-trained text-to-image diffusion models to leverage their powerful generative ability. However, the use of text prompts in virtual try-on is still underexplored. This paper tackles a text-editable virtual try-on task that changes the clothing item based on the provided clothing image while editing the wearing style (e.g., tucking style, fit) according to the text descriptions. In the text-editable virtual try-on, three key aspects exist: (i) designing rich text descriptions for paired person-clothing data to train the model, (ii) addressing the conflicts where textual information of the existing person's clothing interferes the generation of the new clothing, and (iii) adaptively adjust the inpainting mask aligned with the text descriptions, ensuring proper editing areas while preserving the original person's appearance irrelevant to the new clothing. To address these aspects, we propose PromptDresser, a text-editable virtual try-on model that leverages large multimodal model (LMM) assistance to enable high-quality and versatile manipulation based on generative text prompts. Our approach utilizes LMMs via in-context learning to generate detailed text descriptions for person and clothing images independently, including pose details and editing attributes using minimal human cost. Moreover, to ensure the editing areas, we adjust the inpainting mask depending on the text prompts adaptively. We found that our approach, utilizing detailed text prompts, not only enhances text editability but also effectively conveys clothing details that are difficult to capture through images alone, thereby enhancing image quality. Our code is available at https://github.com/rlawjdghek/PromptDresser.
What to Preserve and What to Transfer: Faithful, Identity-Preserving Diffusion-based Hairstyle Transfer
Aug 29, 2024
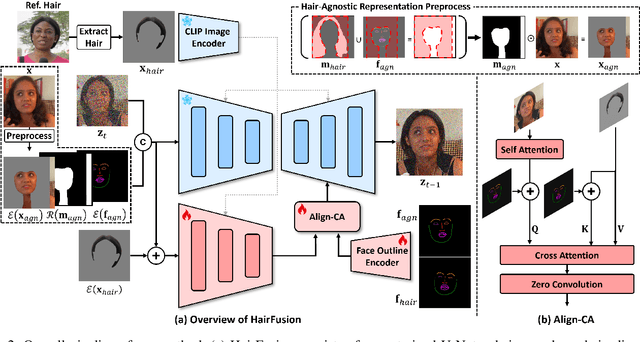


Hairstyle transfer is a challenging task in the image editing field that modifies the hairstyle of a given face image while preserving its other appearance and background features. The existing hairstyle transfer approaches heavily rely on StyleGAN, which is pre-trained on cropped and aligned face images. Hence, they struggle to generalize under challenging conditions such as extreme variations of head poses or focal lengths. To address this issue, we propose a one-stage hairstyle transfer diffusion model, HairFusion, that applies to real-world scenarios. Specifically, we carefully design a hair-agnostic representation as the input of the model, where the original hair information is thoroughly eliminated. Next, we introduce a hair align cross-attention (Align-CA) to accurately align the reference hairstyle with the face image while considering the difference in their face shape. To enhance the preservation of the face image's original features, we leverage adaptive hair blending during the inference, where the output's hair regions are estimated by the cross-attention map in Align-CA and blended with non-hair areas of the face image. Our experimental results show that our method achieves state-of-the-art performance compared to the existing methods in preserving the integrity of both the transferred hairstyle and the surrounding features. The codes are available at https://github.com/cychungg/HairFusion.
GraphPipe: Improving Performance and Scalability of DNN Training with Graph Pipeline Parallelism
Jun 24, 2024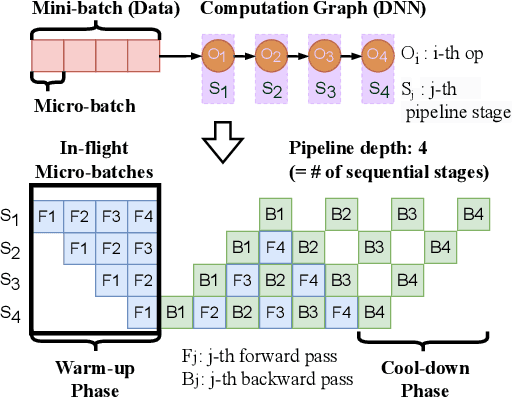

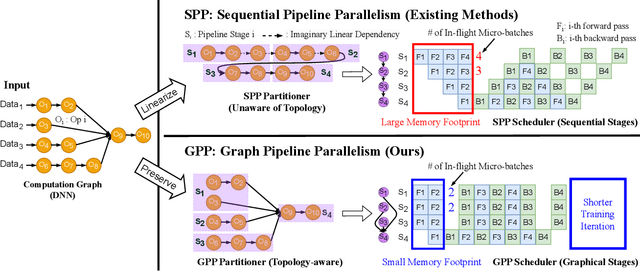
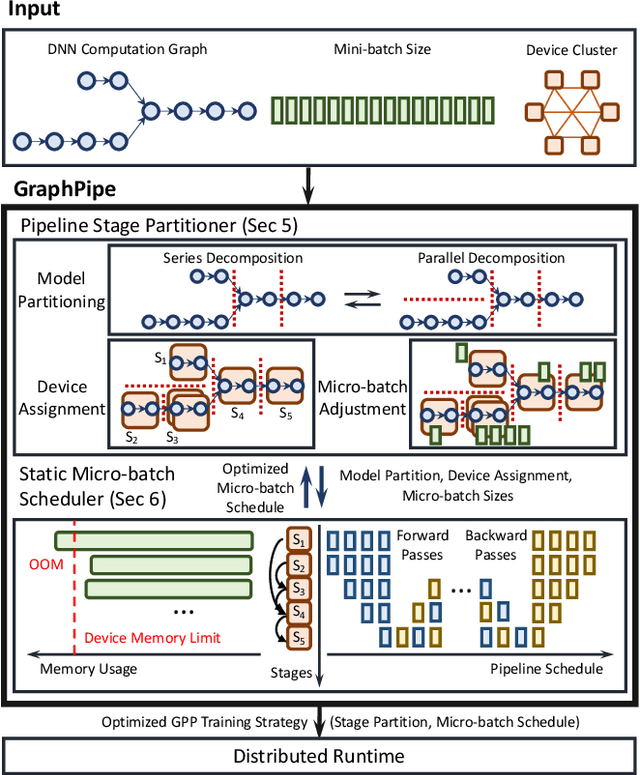
Deep neural networks (DNNs) continue to grow rapidly in size, making them infeasible to train on a single device. Pipeline parallelism is commonly used in existing DNN systems to support large-scale DNN training by partitioning a DNN into multiple stages, which concurrently perform DNN training for different micro-batches in a pipeline fashion. However, existing pipeline-parallel approaches only consider sequential pipeline stages and thus ignore the topology of a DNN, resulting in missed model-parallel opportunities. This paper presents graph pipeline parallelism (GPP), a new pipeline-parallel scheme that partitions a DNN into pipeline stages whose dependencies are identified by a directed acyclic graph. GPP generalizes existing sequential pipeline parallelism and preserves the inherent topology of a DNN to enable concurrent execution of computationally-independent operators, resulting in reduced memory requirement and improved GPU performance. In addition, we develop GraphPipe, a distributed system that exploits GPP strategies to enable performant and scalable DNN training. GraphPipe partitions a DNN into a graph of stages, optimizes micro-batch schedules for these stages, and parallelizes DNN training using the discovered GPP strategies. Evaluation on a variety of DNNs shows that GraphPipe outperforms existing pipeline-parallel systems such as PipeDream and Piper by up to 1.6X. GraphPipe also reduces the search time by 9-21X compared to PipeDream and Piper.
Regularized Training with Generated Datasets for Name-Only Transfer of Vision-Language Models
Jun 08, 2024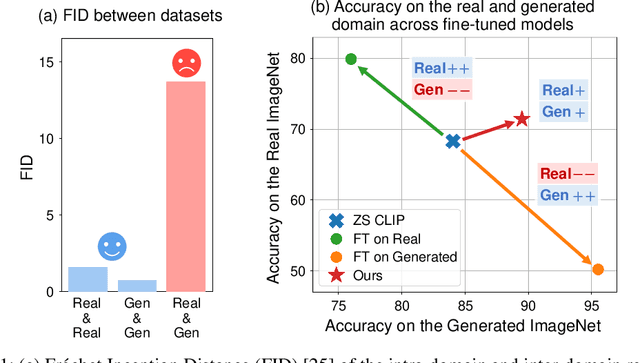
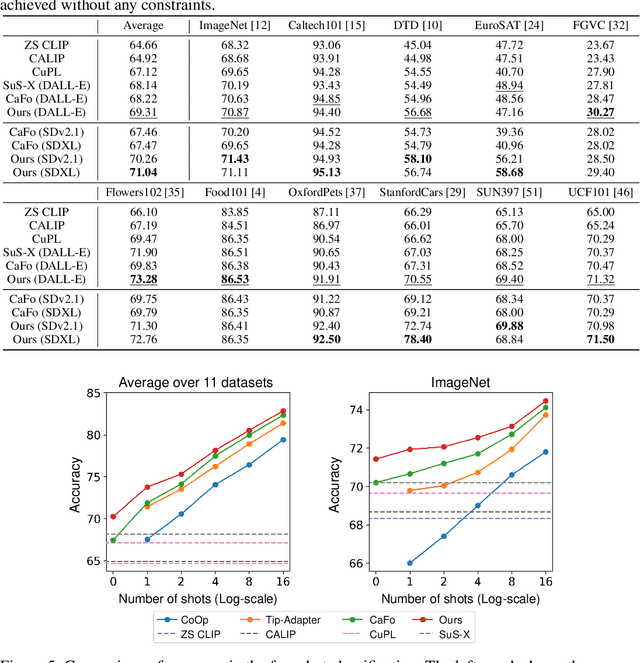
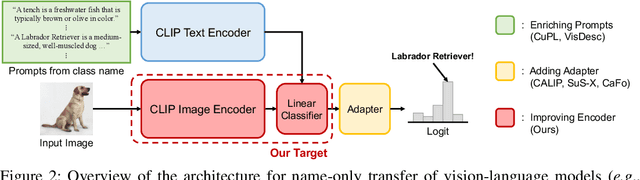
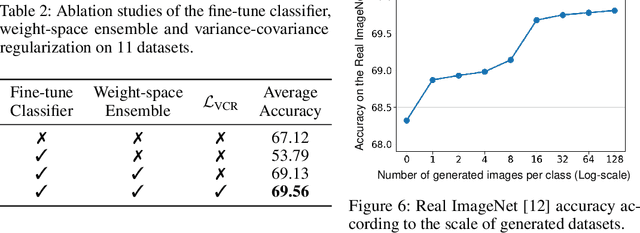
Recent advancements in text-to-image generation have inspired researchers to generate datasets tailored for perception models using generative models, which prove particularly valuable in scenarios where real-world data is limited. In this study, our goal is to address the challenges when fine-tuning vision-language models (e.g., CLIP) on generated datasets. Specifically, we aim to fine-tune vision-language models to a specific classification model without access to any real images, also known as name-only transfer. However, despite the high fidelity of generated images, we observed a significant performance degradation when fine-tuning the model using the generated datasets due to the domain gap between real and generated images. To overcome the domain gap, we provide two regularization methods for training and post-training, respectively. First, we leverage the domain-agnostic knowledge from the original pre-trained vision-language model by conducting the weight-space ensemble of the fine-tuned model on the generated dataset with the original pre-trained model at the post-training. Secondly, we reveal that fine-tuned models with high feature diversity score high performance in the real domain, which indicates that increasing feature diversity prevents learning the generated domain-specific knowledge. Thus, we encourage feature diversity by providing additional regularization at training time. Extensive experiments on various classification datasets and various text-to-image generation models demonstrated that our analysis and regularization techniques effectively mitigate the domain gap, which has long been overlooked, and enable us to achieve state-of-the-art performance by training with generated images. Code is available at https://github.com/pmh9960/regft-for-gen
Reinforcement Learning from Reflective Feedback (RLRF): Aligning and Improving LLMs via Fine-Grained Self-Reflection
Mar 21, 2024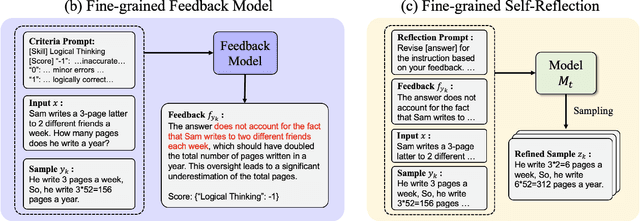
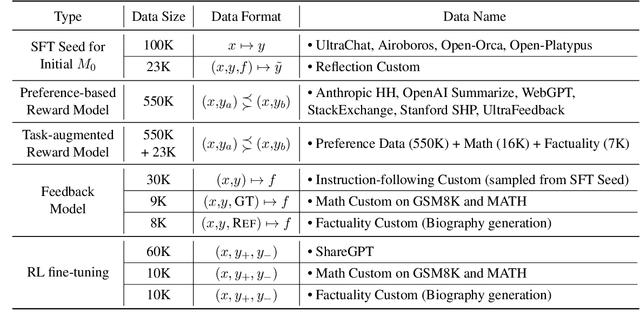
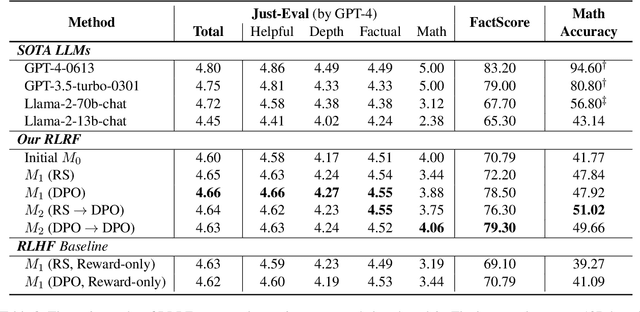

Despite the promise of RLHF in aligning LLMs with human preferences, it often leads to superficial alignment, prioritizing stylistic changes over improving downstream performance of LLMs. Underspecified preferences could obscure directions to align the models. Lacking exploration restricts identification of desirable outputs to improve the models. To overcome these challenges, we propose a novel framework: Reinforcement Learning from Reflective Feedback (RLRF), which leverages fine-grained feedback based on detailed criteria to improve the core capabilities of LLMs. RLRF employs a self-reflection mechanism to systematically explore and refine LLM responses, then fine-tuning the models via a RL algorithm along with promising responses. Our experiments across Just-Eval, Factuality, and Mathematical Reasoning demonstrate the efficacy and transformative potential of RLRF beyond superficial surface-level adjustment.
YTCommentQA: Video Question Answerability in Instructional Videos
Jan 30, 2024



Instructional videos provide detailed how-to guides for various tasks, with viewers often posing questions regarding the content. Addressing these questions is vital for comprehending the content, yet receiving immediate answers is difficult. While numerous computational models have been developed for Video Question Answering (Video QA) tasks, they are primarily trained on questions generated based on video content, aiming to produce answers from within the content. However, in real-world situations, users may pose questions that go beyond the video's informational boundaries, highlighting the necessity to determine if a video can provide the answer. Discerning whether a question can be answered by video content is challenging due to the multi-modal nature of videos, where visual and verbal information are intertwined. To bridge this gap, we present the YTCommentQA dataset, which contains naturally-generated questions from YouTube, categorized by their answerability and required modality to answer -- visual, script, or both. Experiments with answerability classification tasks demonstrate the complexity of YTCommentQA and emphasize the need to comprehend the combined role of visual and script information in video reasoning. The dataset is available at https://github.com/lgresearch/YTCommentQA.