 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphPipe: Improving Performance and Scalability of DNN Training with Graph Pipeline Parallelism
Jun 24, 2024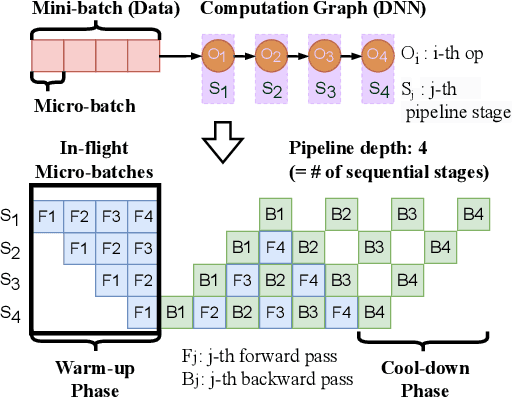

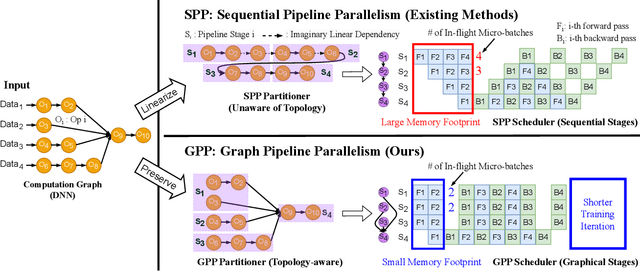
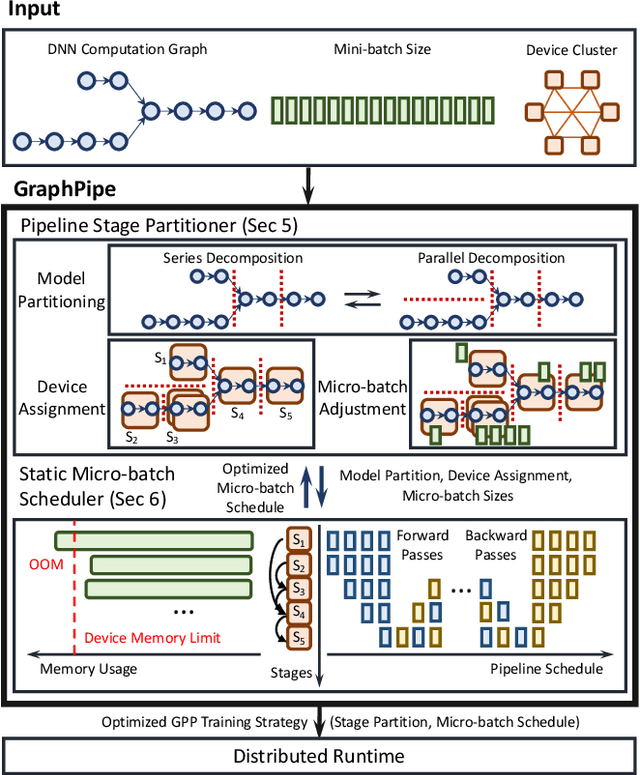
Deep neural networks (DNNs) continue to grow rapidly in size, making them infeasible to train on a single device. Pipeline parallelism is commonly used in existing DNN systems to support large-scale DNN training by partitioning a DNN into multiple stages, which concurrently perform DNN training for different micro-batches in a pipeline fashion. However, existing pipeline-parallel approaches only consider sequential pipeline stages and thus ignore the topology of a DNN, resulting in missed model-parallel opportunities. This paper presents graph pipeline parallelism (GPP), a new pipeline-parallel scheme that partitions a DNN into pipeline stages whose dependencies are identified by a directed acyclic graph. GPP generalizes existing sequential pipeline parallelism and preserves the inherent topology of a DNN to enable concurrent execution of computationally-independent operators, resulting in reduced memory requirement and improved GPU performance. In addition, we develop GraphPipe, a distributed system that exploits GPP strategies to enable performant and scalable DNN training. GraphPipe partitions a DNN into a graph of stages, optimizes micro-batch schedules for these stages, and parallelizes DNN training using the discovered GPP strategies. Evaluation on a variety of DNNs shows that GraphPipe outperforms existing pipeline-parallel systems such as PipeDream and Piper by up to 1.6X. GraphPipe also reduces the search time by 9-21X compared to PipeDream and Piper.
FlexLLM: A System for Co-Serving Large Language Model Inference and Parameter-Efficient Finetuning
Feb 29, 2024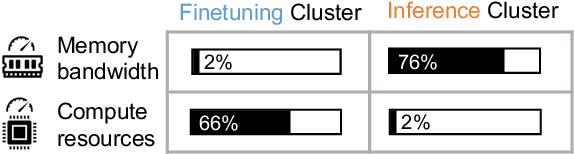
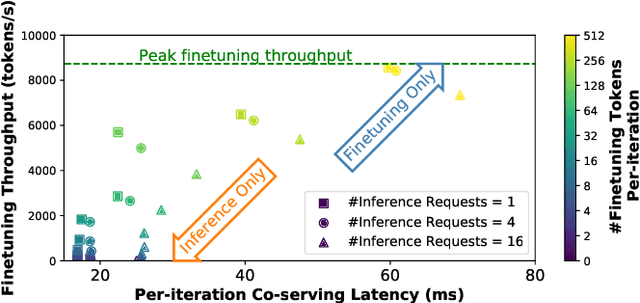

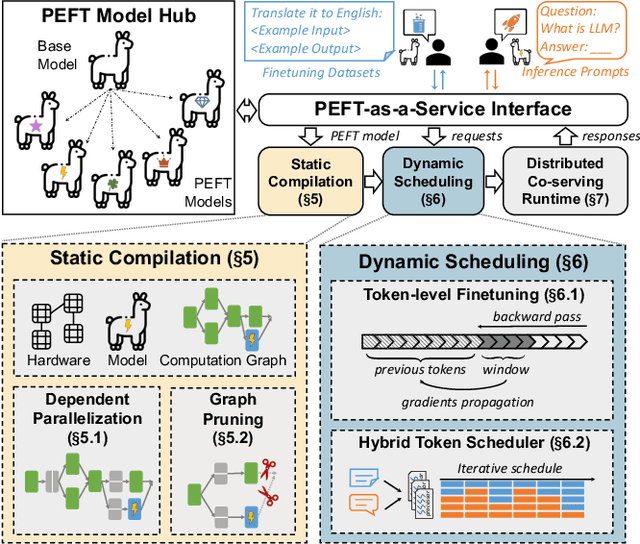
Parameter-efficient finetuning (PEFT) is a widely used technique to adapt large language models for different tasks. Service providers typically create separate systems for users to perform PEFT model finetuning and inference tasks. This is because existing systems cannot handle workloads that include a mix of inference and PEFT finetuning requests. As a result, shared GPU resources are underutilized, leading to inefficiencies. To address this problem, we present FlexLLM, the first system that can serve inference and parameter-efficient finetuning requests in the same iteration. Our system leverages the complementary nature of these two tasks and utilizes shared GPU resources to run them jointly, using a method called co-serving. To achieve this, FlexLLM introduces a novel token-level finetuning mechanism, which breaks down the finetuning computation of a sequence into smaller token-level computations and uses dependent parallelization and graph pruning, two static compilation optimizations, to minimize the memory overhead and latency for co-serving. Compared to existing systems, FlexLLM's co-serving approach reduces the activation GPU memory overhead by up to 8x, and the end-to-end GPU memory requirement of finetuning by up to 36% while maintaining a low inference latency and improving finetuning throughput. For example, under a heavy inference workload, FlexLLM can still preserve more than 80% of the peak finetuning throughput, whereas existing systems cannot make any progress with finetuning. The source code of FlexLLM is publicly available at https://github.com/flexflow/FlexFlow.