 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonuniform-Tensor-Parallelism: Mitigating GPU failure impact for Scaled-up LLM Training
Apr 08, 2025



LLM training is scaled up to 10Ks of GPUs by a mix of data-(DP) and model-parallel (MP) execution. Critical to achieving efficiency is tensor-parallel (TP; a form of MP) execution within tightly-coupled subsets of GPUs, referred to as a scale-up domain, and the larger the scale-up domain the better the performance. New datacenter architectures are emerging with more GPUs able to be tightly-coupled in a scale-up domain, such as moving from 8 GPUs to 72 GPUs connected via NVLink. Unfortunately, larger scale-up domains increase the blast-radius of failures, with a failure of single GPU potentially impacting TP execution on the full scale-up domain, which can degrade overall LLM training throughput dramatically. With as few as 0.1% of GPUs being in a failed state, a high TP-degree job can experience nearly 10% reduction in LLM training throughput. We propose nonuniform-tensor-parallelism (NTP) to mitigate this amplified impact of GPU failures. In NTP, a DP replica that experiences GPU failures operates at a reduced TP degree, contributing throughput equal to the percentage of still-functional GPUs. We also propose a rack-design with improved electrical and thermal capabilities in order to sustain power-boosting of scale-up domains that have experienced failures; combined with NTP, this can allow the DP replica with the reduced TP degree (i.e., with failed GPUs) to keep up with the others, thereby achieving near-zero throughput loss for large-scale LLM training.
GraphPipe: Improving Performance and Scalability of DNN Training with Graph Pipeline Parallelism
Jun 24, 2024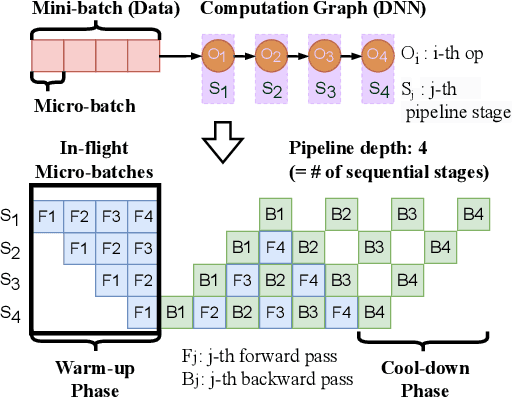

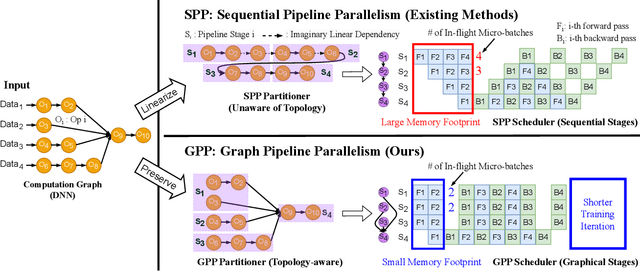
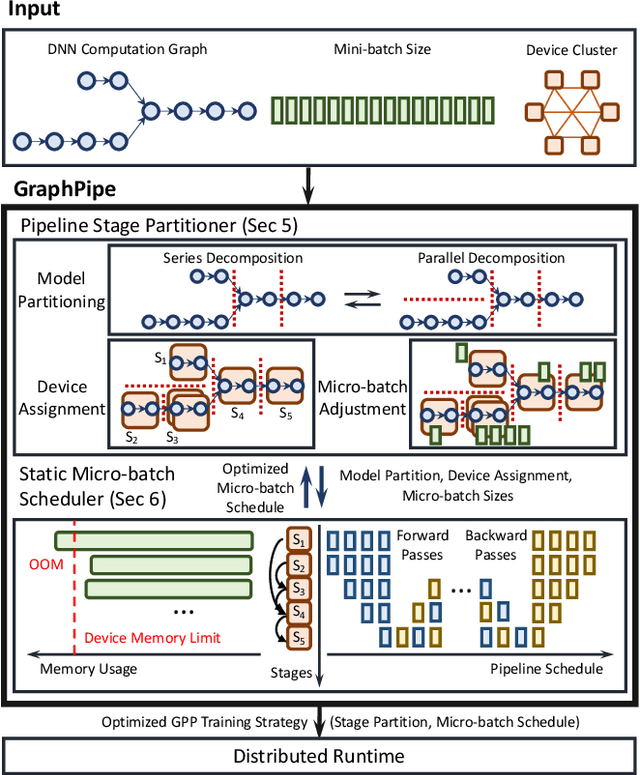
Deep neural networks (DNNs) continue to grow rapidly in size, making them infeasible to train on a single device. Pipeline parallelism is commonly used in existing DNN systems to support large-scale DNN training by partitioning a DNN into multiple stages, which concurrently perform DNN training for different micro-batches in a pipeline fashion. However, existing pipeline-parallel approaches only consider sequential pipeline stages and thus ignore the topology of a DNN, resulting in missed model-parallel opportunities. This paper presents graph pipeline parallelism (GPP), a new pipeline-parallel scheme that partitions a DNN into pipeline stages whose dependencies are identified by a directed acyclic graph. GPP generalizes existing sequential pipeline parallelism and preserves the inherent topology of a DNN to enable concurrent execution of computationally-independent operators, resulting in reduced memory requirement and improved GPU performance. In addition, we develop GraphPipe, a distributed system that exploits GPP strategies to enable performant and scalable DNN training. GraphPipe partitions a DNN into a graph of stages, optimizes micro-batch schedules for these stages, and parallelizes DNN training using the discovered GPP strategies. Evaluation on a variety of DNNs shows that GraphPipe outperforms existing pipeline-parallel systems such as PipeDream and Piper by up to 1.6X. GraphPipe also reduces the search time by 9-21X compared to PipeDream and Piper.
SpecInfer: Accelerating Generative LLM Serving with Speculative Inference and Token Tree Verification
May 16, 2023



The high computational and memory requirements of generative large language models (LLMs) make it challenging to serve them quickly and cheaply. This paper introduces SpecInfer, an LLM serving system that accelerates generative LLM inference with speculative inference and token tree verification. A key insight behind SpecInfer is to combine various collectively boost-tuned small language models to jointly predict the LLM's outputs; the predictions are organized as a token tree, whose nodes each represent a candidate token sequence. The correctness of all candidate token sequences represented by a token tree is verified by the LLM in parallel using a novel tree-based parallel decoding mechanism. SpecInfer uses an LLM as a token tree verifier instead of an incremental decoder, which significantly reduces the end-to-end latency and computational requirement for serving generative LLMs while provably preserving model quality.
HAWQ-V2: Hessian Aware trace-Weighted Quantization of Neural Networks
Nov 10, 2019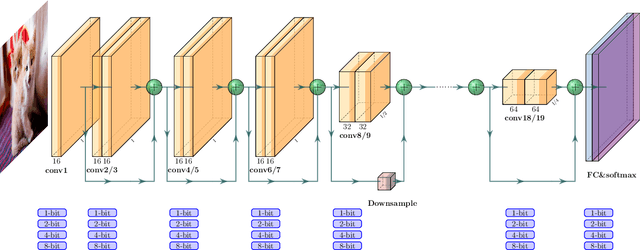
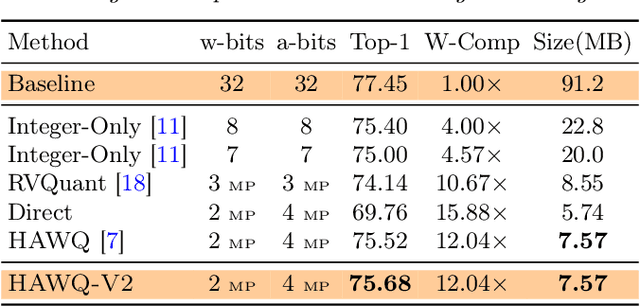
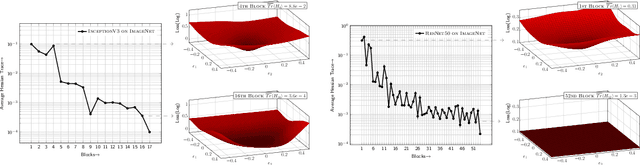
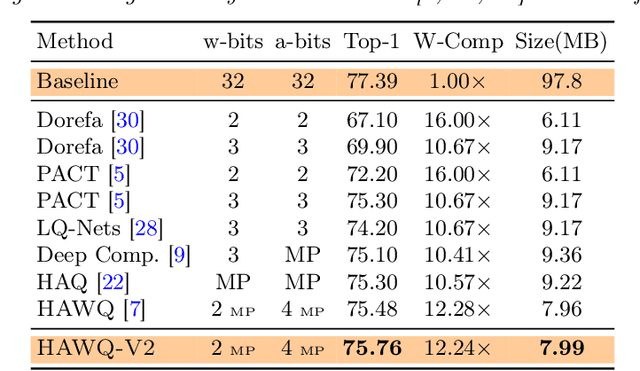
Quantization is an effective method for reducing memory footprint and inference time of Neural Networks, e.g., for efficient inference in the cloud, especially at the edge. However, ultra low precision quantization could lead to significant degradation in model generalization. A promising method to address this is to perform mixed-precision quantization, where more sensitive layers are kept at higher precision. However, the search space for a mixed-precision quantization is exponential in the number of layers. Recent work has proposed HAWQ, a novel Hessian based framework, with the aim of reducing this exponential search space by using second-order information. While promising, this prior work has three major limitations: (i) HAWQV1 only uses the top Hessian eigenvalue as a measure of sensitivity and do not consider the rest of the Hessian spectrum; (ii) HAWQV1 approach only provides relative sensitivity of different layers and therefore requires a manual selection of the mixed-precision setting; and (iii) HAWQV1 does not consider mixed-precision activation quantization. Here, we present HAWQV2 which addresses these shortcomings. For (i), we perform a theoretical analysis showing that a better sensitivity metric is to compute the average of all of the Hessian eigenvalues. For (ii), we develop a Pareto frontier based method for selecting the exact bit precision of different layers without any manual selection. For (iii), we extend the Hessian analysis to mixed-precision activation quantization. We have found this to be very beneficial for object detection. We show that HAWQV2 achieves new state-of-the-art results for a wide range of tasks.
Unsupervised Projection Networks for Generative Adversarial Networks
Oct 06, 2019



We propose the use of unsupervised learning to train projection networks that project onto the latent space of an already trained generator. We apply our method to a trained StyleGAN, and use our projection network to perform image super-resolution and clustering of images into semantically identifiable groups.