 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparrow: Sparse Rollout for Stable and Efficient Long-context RL of Large Language Models
Jun 07, 2026Despite being powerful, reinforcement learning with verifiable rewards (RLVR) induces extremely long COT, making it computationally expensive. Since RLVR per-step cost is dominated by long-context rollout generation, sparse attention offers a promising way to accelerate dense rollout. However, sparse rollouts require a delicate stability-efficiency tradeoff: overly aggressive sparsity causes collapse, while overly lenient sparsity gives insufficient speedup. In this work, we study this tradeoff through sparse-to-dense actor-policy mismatch. We first observe that sparse rollout collapse is not driven by uniform degradation across tokens: most sparse tokens align perfectly with dense even under aggressive sparsity. Motivated by this, we hypothesize that sparse rollout training remains stable if the lower tail of per-token actor-policy mismatch stays above a critical threshold throughout the trajectory. We introduce a dynamic sparsity schedule that keeps this tail statistic constant during generation and validate our hypothesis. Across Qwen3 thinking-family models, keeping the tail mismatch statistic near a consistent threshold generally enables stable training. We then use a cost model to find the sparsity schedule for maximum speedup under this mismatch threshold, achieving 2.2x, 2.4x, and 2.0x rollout speedups when training Qwen3-1.7B, Qwen3-4B, and Qwen3-8B. Empirically, we show the thresholds generalize to a larger model (Qwen3-14B) and another RL domain (coding). Finally, our analysis naturally motivates DistillSparse: lightweight LoRA-based distillation on sparse rollout lets more aggressive sparsity reach the same sparse-to-dense mismatch threshold, yielding higher speedup.
Vortex: Efficient and Programmable Sparse Attention Serving for AI Agents
Jun 04, 2026Sparse attention is becoming increasingly important for serving large language models (LLMs) as generation lengths continue to grow. However, deploying and evaluating new sparse attention algorithms at scale remains highly engineering-intensive, slowing both human researchers and AI agents in exploring the sparse attention design. To address this challenge, we present Vortex, a system that combines a Python-embedded frontend language atop a page-centric tensor abstraction for expressing a broad range of sparse attention algorithms, with an efficient backend tightly integrated into modern LLM serving stacks. Vortex enables rapid prototyping, deployment, and evaluation of sparse attention algorithms, effectively translating their theoretical efficiency gains into real-world throughput improvements. As a result, Vortex substantially accelerates the design and iteration of sparse attention algorithms. First, AI agents use Vortex to automatically generate and refine diverse algorithms, the best reaching up to $3.46\times$ higher throughput than full attention while preserving accuracy. Second, Vortex extends sparse attention to emerging architectures and very large models that are otherwise hard to experiment with, reaching up to $4.7\times$ higher throughput on the MLA-based GLM-4.7-Flash and $1.37\times$ on the 229B-parameter MiniMax-M2.7 on NVIDIA B200 GPUs.
MonarchRT: Efficient Attention for Real-Time Video Generation
Feb 12, 2026Real-time video generation with Diffusion Transformers is bottlenecked by the quadratic cost of 3D self-attention, especially in real-time regimes that are both few-step and autoregressive, where errors compound across time and each denoising step must carry substantially more information. In this setting, we find that prior sparse-attention approximations break down, despite showing strong results for bidirectional, many-step diffusion. Specifically, we observe that video attention is not reliably sparse, but instead combines pronounced periodic structure driven by spatiotemporal position with dynamic, sparse semantic correspondences and dense mixing, exceeding the representational capacity of even oracle top-k attention. Building on this insight, we propose Monarch-RT, a structured attention parameterization for video diffusion models that factorizes attention using Monarch matrices. Through appropriately aligned block structure and our extended tiled Monarch parameterization, we achieve high expressivity while preserving computational efficiency. We further overcome the overhead of parameterization through finetuning, with custom Triton kernels. We first validate the high efficacy of Monarch-RT over existing sparse baselines designed only for bidirectional models. We further observe that Monarch-RT attains up to 95% attention sparsity with no loss in quality when applied to the state-of-the-art model Self-Forcing, making Monarch-RT a pioneering work on highly-capable sparse attention parameterization for real-time video generation. Our optimized implementation outperforms FlashAttention-2, FlashAttention-3, and FlashAttention-4 kernels on Nvidia RTX 5090, H100, and B200 GPUs respectively, providing kernel speedups in the range of 1.4-11.8X. This enables us, for the first time, to achieve true real-time video generation with Self-Forcing at 16 FPS on a single RTX 5090.
Jackpot: Optimal Budgeted Rejection Sampling for Extreme Actor-Policy Mismatch Reinforcement Learning
Feb 05, 2026Reinforcement learning (RL) for large language models (LLMs) remains expensive, particularly because the rollout is expensive. Decoupling rollout generation from policy optimization (e.g., leveraging a more efficient model to rollout) could enable substantial efficiency gains, yet doing so introduces a severe distribution mismatch that destabilizes learning. We propose Jackpot, a framework that leverages Optimal Budget Rejection Sampling (OBRS) to directly reduce the discrepancy between the rollout model and the evolving policy. Jackpot integrates a principled OBRS procedure, a unified training objective that jointly updates the policy and rollout models, and an efficient system implementation enabled by top-$k$ probability estimation and batch-level bias correction. Our theoretical analysis shows that OBRS consistently moves the rollout distribution closer to the target distribution under a controllable acceptance budget. Empirically, \sys substantially improves training stability compared to importance-sampling baselines, achieving performance comparable to on-policy RL when training Qwen3-8B-Base for up to 300 update steps of batchsize 64. Taken together, our results show that OBRS-based alignment brings us a step closer to practical and effective decoupling of rollout generation from policy optimization for RL for LLMs.
Kinetics: Rethinking Test-Time Scaling Laws
Jun 06, 2025We rethink test-time scaling laws from a practical efficiency perspective, revealing that the effectiveness of smaller models is significantly overestimated. Prior work, grounded in compute-optimality, overlooks critical memory access bottlenecks introduced by inference-time strategies (e.g., Best-of-$N$, long CoTs). Our holistic analysis, spanning models from 0.6B to 32B parameters, reveals a new Kinetics Scaling Law that better guides resource allocation by incorporating both computation and memory access costs. Kinetics Scaling Law suggests that test-time compute is more effective when used on models above a threshold than smaller ones. A key reason is that in TTS, attention, rather than parameter count, emerges as the dominant cost factor. Motivated by this, we propose a new scaling paradigm centered on sparse attention, which lowers per-token cost and enables longer generations and more parallel samples within the same resource budget. Empirically, we show that sparse attention models consistently outperform dense counterparts, achieving over 60 points gains in low-cost regimes and over 5 points gains in high-cost regimes for problem-solving accuracy on AIME, encompassing evaluations on state-of-the-art MoEs. These results suggest that sparse attention is essential and increasingly important with more computing invested, for realizing the full potential of test-time scaling where, unlike training, accuracy has yet to saturate as a function of computation, and continues to improve through increased generation. The code is available at https://github.com/Infini-AI-Lab/Kinetics.
GSM-Infinite: How Do Your LLMs Behave over Infinitely Increasing Context Length and Reasoning Complexity?
Feb 07, 2025Long-context large language models (LLMs) have recently shown strong performance in information retrieval and long-document QA. However, to tackle the most challenging intellectual problems, LLMs must reason effectively in long and complex contexts (e.g., frontier mathematical research). Studying how LLMs handle increasing reasoning complexity and context length is essential, yet existing benchmarks lack a solid basis for quantitative evaluation. Inspired by the abstraction of GSM-8K problems as computational graphs, and the ability to introduce noise by adding unnecessary nodes and edges, we develop a grade school math problem generator capable of producing arithmetic problems with infinite difficulty and context length under fine-grained control. Using our newly synthesized GSM-Infinite benchmark, we comprehensively evaluate existing LLMs. We find a consistent sigmoid decline in reasoning performance as complexity increases, along with a systematic inference scaling trend: exponentially increasing inference computation yields only linear performance gains. These findings underscore the fundamental limitations of current long-context LLMs and the key challenges in scaling reasoning capabilities. Our GSM-Infinite benchmark provides a scalable and controllable testbed for systematically studying and advancing LLM reasoning in long and complex contexts.
AdaServe: SLO-Customized LLM Serving with Fine-Grained Speculative Decoding
Jan 21, 2025This paper introduces AdaServe, the first LLM serving system to support SLO customization through fine-grained speculative decoding. AdaServe leverages the logits of a draft model to predict the speculative accuracy of tokens and employs a theoretically optimal algorithm to construct token trees for verification. To accommodate diverse SLO requirements without compromising throughput, AdaServe employs a speculation-and-selection scheme that first constructs candidate token trees for each request and then dynamically selects tokens to meet individual SLO constraints while optimizing throughput. Comprehensive evaluations demonstrate that AdaServe achieves up to 73% higher SLO attainment and 74% higher goodput compared to state-of-the-art systems. These results underscore AdaServe's potential to enhance the efficiency and adaptability of LLM deployments across varied application scenarios.
MagicPIG: LSH Sampling for Efficient LLM Generation
Oct 21, 2024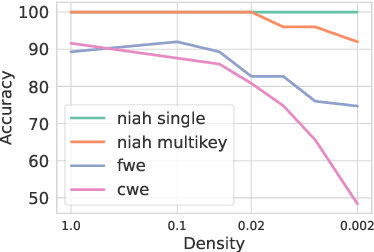
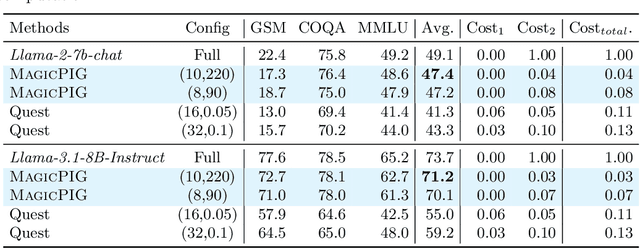
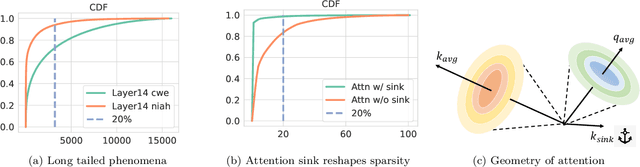
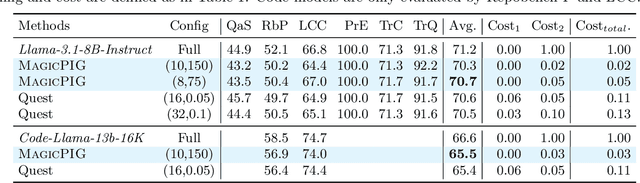
Large language models (LLMs) with long context windows have gained significant attention. However, the KV cache, stored to avoid re-computation, becomes a bottleneck. Various dynamic sparse or TopK-based attention approximation methods have been proposed to leverage the common insight that attention is sparse. In this paper, we first show that TopK attention itself suffers from quality degradation in certain downstream tasks because attention is not always as sparse as expected. Rather than selecting the keys and values with the highest attention scores, sampling with theoretical guarantees can provide a better estimation for attention output. To make the sampling-based approximation practical in LLM generation, we propose MagicPIG, a heterogeneous system based on Locality Sensitive Hashing (LSH). MagicPIG significantly reduces the workload of attention computation while preserving high accuracy for diverse tasks. MagicPIG stores the LSH hash tables and runs the attention computation on the CPU, which allows it to serve longer contexts and larger batch sizes with high approximation accuracy. MagicPIG can improve decoding throughput by $1.9\sim3.9\times$ across various GPU hardware and achieve 110ms decoding latency on a single RTX 4090 for Llama-3.1-8B-Instruct model with a context of 96k tokens. The code is available at \url{https://github.com/Infini-AI-Lab/MagicPIG}.
Sirius: Contextual Sparsity with Correction for Efficient LLMs
Sep 05, 2024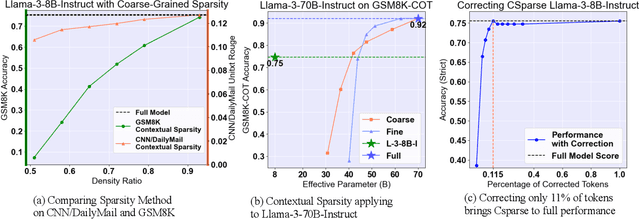
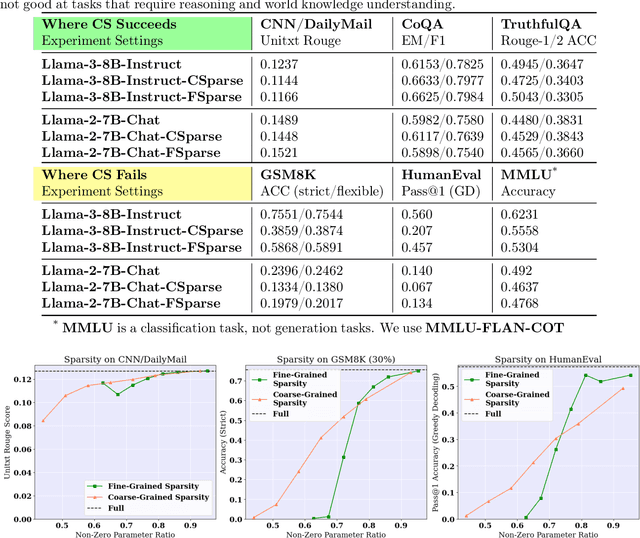


With the blossom of large language models (LLMs), inference efficiency becomes increasingly important. Various approximation methods are proposed to reduce the cost at inference time. Contextual Sparsity (CS) is appealing for its training-free nature and its ability to reach a higher compression ratio seemingly without quality degradation. However, after a comprehensive evaluation of contextual sparsity methods on various complex generation tasks, we find that although CS succeeds in prompt-understanding tasks, CS significantly degrades the model performance for reasoning, deduction, and knowledge-based tasks. Despite the gap in end-to-end accuracy, we observed that sparse models often share general problem-solving logic and require only a few token corrections to recover the original model performance. This paper introduces Sirius, an efficient correction mechanism, which significantly recovers CS models quality on reasoning tasks while maintaining its efficiency gain. Sirius is evaluated on 6 models with 8 difficult generation tasks in reasoning, math, and coding and shows consistent effectiveness and efficiency. Also, we carefully develop a system implementation for Sirius and show that Sirius achieves roughly 20% reduction in latency for 8B model on-chip and 35% reduction for 70B model offloading. We open-source our implementation of Sirius at https://github.com/Infini-AI-Lab/Sirius.git.
MagicDec: Breaking the Latency-Throughput Tradeoff for Long Context Generation with Speculative Decoding
Aug 21, 2024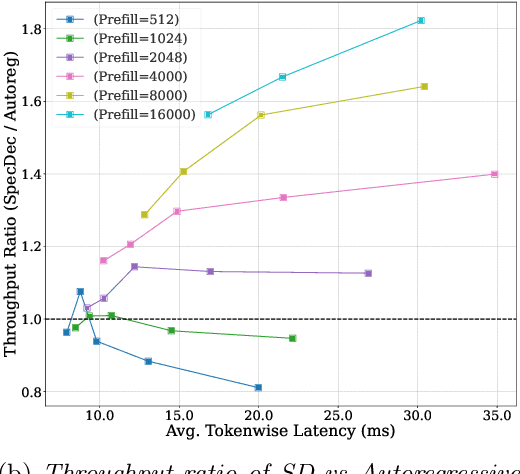
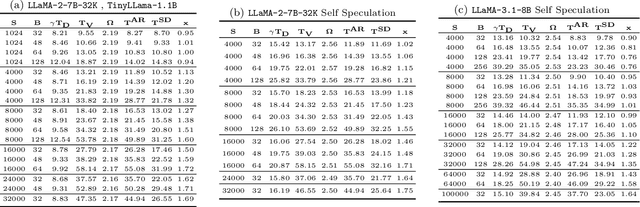
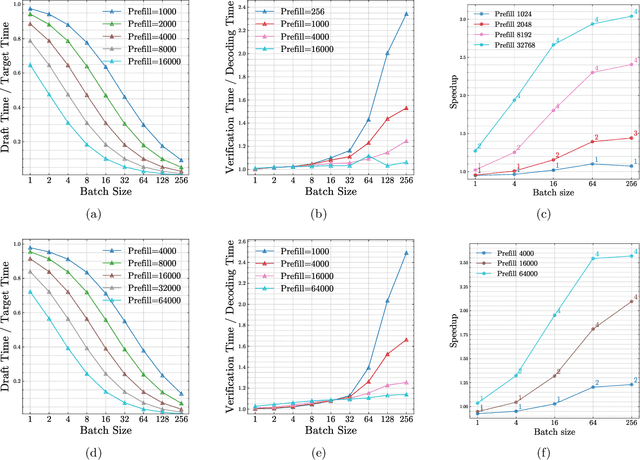
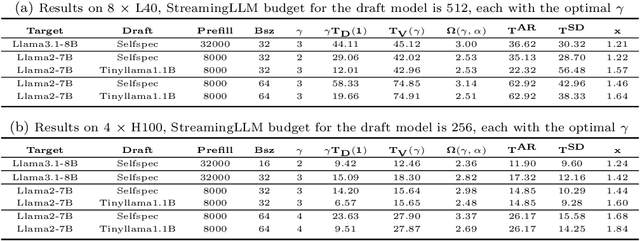
Large Language Models (LLMs) have become more prevalent in long-context applications such as interactive chatbots, document analysis, and agent workflows, but it is challenging to serve long-context requests with low latency and high throughput. Speculative decoding (SD) is a widely used technique to reduce latency without sacrificing performance but the conventional wisdom suggests that its efficacy is limited to small batch sizes. In MagicDec, we show that surprisingly SD can achieve speedup even for a high throughput inference regime for moderate to long sequences. More interestingly, an intelligent drafting strategy can achieve better speedup with increasing batch size based on our rigorous analysis. MagicDec first identifies the bottleneck shifts with increasing batch size and sequence length, and uses these insights to deploy speculative decoding more effectively for high throughput inference. Then, it leverages draft models with sparse KV cache to address the KV bottleneck that scales with both sequence length and batch size. This finding underscores the broad applicability of speculative decoding in long-context serving, as it can enhance throughput and reduce latency without compromising accuracy. For moderate to long sequences, we demonstrate up to 2x speedup for LLaMA-2-7B-32K and 1.84x speedup for LLaMA-3.1-8B when serving batch sizes ranging from 32 to 256 on 8 NVIDIA A100 GPUs. The code is available at https://github.com/Infini-AI-Lab/MagicDec/.