 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequoia: Scalable, Robust, and Hardware-aware Speculative Decoding
Feb 29, 2024

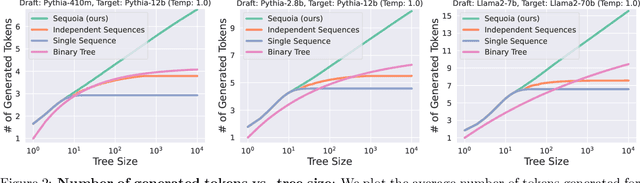

As the usage of large language models (LLMs) grows, performing efficient inference with these models becomes increasingly important. While speculative decoding has recently emerged as a promising direction for speeding up inference, existing methods are limited in their ability to scale to larger speculation budgets, and adapt to different hyperparameters and hardware. This paper introduces Sequoia, a scalable, robust, and hardware-aware algorithm for speculative decoding. To attain better scalability, Sequoia introduces a dynamic programming algorithm to find the optimal tree structure for the speculated tokens. To achieve robust speculative performance, Sequoia uses a novel sampling and verification method that outperforms prior work across different decoding temperatures. Finally, Sequoia introduces a hardware-aware tree optimizer that maximizes speculative performance by automatically selecting the token tree size and depth for a given hardware platform. Evaluation shows that Sequoia improves the decoding speed of Llama2-7B, Llama2-13B, and Vicuna-33B on an A100 by up to $4.04\times$, $3.73\times$, and $2.27\times$. For offloading setting on L40, Sequoia achieves as low as 0.56 s/token for exact Llama2-70B inference latency, which is $9.96\times$ on our optimized offloading system (5.6 s/token), $9.7\times$ than DeepSpeed-Zero-Inference, $19.5\times$ than Huggingface Accelerate.