 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoJudge: Judge Decoding Without Manual Annotation
Apr 28, 2025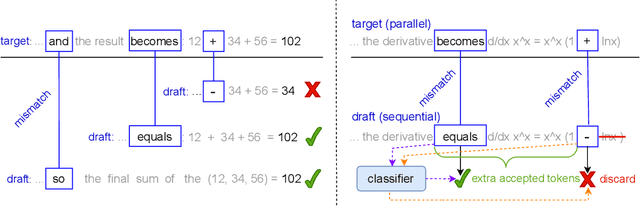

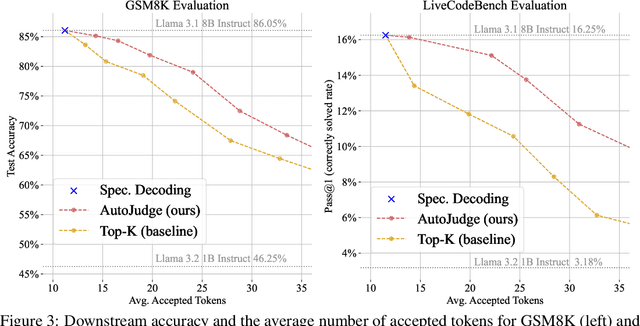
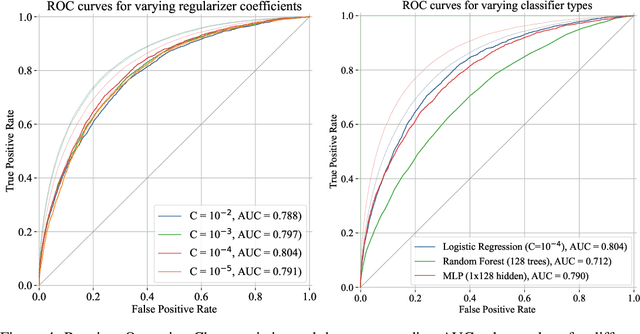
We introduce AutoJudge, a framework that accelerates large language model (LLM) inference with task-specific lossy speculative decoding. Instead of matching the original model output distribution token-by-token, we identify which of the generated tokens affect the downstream quality of the generated response, relaxing the guarantee so that the "unimportant" tokens can be generated faster. Our approach relies on a semi-greedy search algorithm to test which of the mismatches between target and draft model should be corrected to preserve quality, and which ones may be skipped. We then train a lightweight classifier based on existing LLM embeddings to predict, at inference time, which mismatching tokens can be safely accepted without compromising the final answer quality. We test our approach with Llama 3.2 1B (draft) and Llama 3.1 8B (target) models on zero-shot GSM8K reasoning, where it achieves up to 1.5x more accepted tokens per verification cycle with under 1% degradation in answer accuracy compared to standard speculative decoding and over 2x with small loss in accuracy. When applied to the LiveCodeBench benchmark, our approach automatically detects other, programming-specific important tokens and shows similar speedups, demonstrating its ability to generalize across tasks.
Label Privacy in Split Learning for Large Models with Parameter-Efficient Training
Dec 21, 2024As deep learning models become larger and more expensive, many practitioners turn to fine-tuning APIs. These web services allow fine-tuning a model between two parties: the client that provides the data, and the server that hosts the model. While convenient, these APIs raise a new concern: the data of the client is at risk of privacy breach during the training procedure. This challenge presents an important practical case of vertical federated learning, where the two parties perform parameter-efficient fine-tuning (PEFT) of a large model. In this study, we systematically search for a way to fine-tune models over an API while keeping the labels private. We analyze the privacy of LoRA, a popular approach for parameter-efficient fine-tuning when training over an API. Using this analysis, we propose P$^3$EFT, a multi-party split learning algorithm that takes advantage of existing PEFT properties to maintain privacy at a lower performance overhead. To validate our algorithm, we fine-tune DeBERTa-v2-XXLarge, Flan-T5 Large and LLaMA-2 7B using LoRA adapters on a range of NLP tasks. We find that P$^3$EFT is competitive with existing privacy-preserving methods in multi-party and two-party setups while having higher accuracy.
Accurate Compression of Text-to-Image Diffusion Models via Vector Quantization
Aug 31, 2024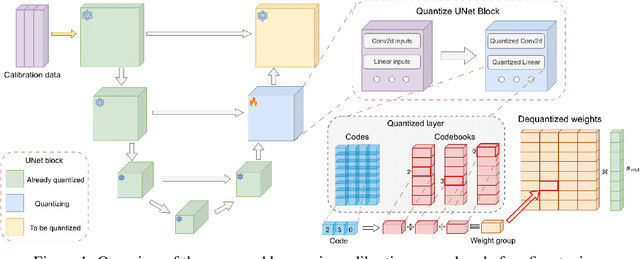
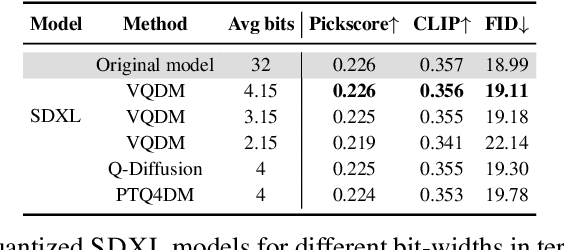


Text-to-image diffusion models have emerged as a powerful framework for high-quality image generation given textual prompts. Their success has driven the rapid development of production-grade diffusion models that consistently increase in size and already contain billions of parameters. As a result, state-of-the-art text-to-image models are becoming less accessible in practice, especially in resource-limited environments. Post-training quantization (PTQ) tackles this issue by compressing the pretrained model weights into lower-bit representations. Recent diffusion quantization techniques primarily rely on uniform scalar quantization, providing decent performance for the models compressed to 4 bits. This work demonstrates that more versatile vector quantization (VQ) may achieve higher compression rates for large-scale text-to-image diffusion models. Specifically, we tailor vector-based PTQ methods to recent billion-scale text-to-image models (SDXL and SDXL-Turbo), and show that the diffusion models of 2B+ parameters compressed to around 3 bits using VQ exhibit the similar image quality and textual alignment as previous 4-bit compression techniques.
SpecExec: Massively Parallel Speculative Decoding for Interactive LLM Inference on Consumer Devices
Jun 04, 2024



As large language models gain widespread adoption, running them efficiently becomes crucial. Recent works on LLM inference use speculative decoding to achieve extreme speedups. However, most of these works implicitly design their algorithms for high-end datacenter hardware. In this work, we ask the opposite question: how fast can we run LLMs on consumer machines? Consumer GPUs can no longer fit the largest available models (50B+ parameters) and must offload them to RAM or SSD. When running with offloaded parameters, the inference engine can process batches of hundreds or thousands of tokens at the same time as just one token, making it a natural fit for speculative decoding. We propose SpecExec (Speculative Execution), a simple parallel decoding method that can generate up to 20 tokens per target model iteration for popular LLM families. It utilizes the high spikiness of the token probabilities distribution in modern LLMs and a high degree of alignment between model output probabilities. SpecExec takes the most probable tokens continuation from the draft model to build a "cache" tree for the target model, which then gets validated in a single pass. Using SpecExec, we demonstrate inference of 50B+ parameter LLMs on consumer GPUs with RAM offloading at 4-6 tokens per second with 4-bit quantization or 2-3 tokens per second with 16-bit weights.
Sequoia: Scalable, Robust, and Hardware-aware Speculative Decoding
Feb 29, 2024

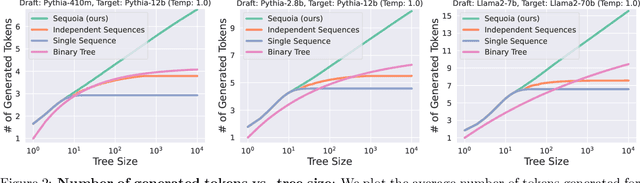

As the usage of large language models (LLMs) grows, performing efficient inference with these models becomes increasingly important. While speculative decoding has recently emerged as a promising direction for speeding up inference, existing methods are limited in their ability to scale to larger speculation budgets, and adapt to different hyperparameters and hardware. This paper introduces Sequoia, a scalable, robust, and hardware-aware algorithm for speculative decoding. To attain better scalability, Sequoia introduces a dynamic programming algorithm to find the optimal tree structure for the speculated tokens. To achieve robust speculative performance, Sequoia uses a novel sampling and verification method that outperforms prior work across different decoding temperatures. Finally, Sequoia introduces a hardware-aware tree optimizer that maximizes speculative performance by automatically selecting the token tree size and depth for a given hardware platform. Evaluation shows that Sequoia improves the decoding speed of Llama2-7B, Llama2-13B, and Vicuna-33B on an A100 by up to $4.04\times$, $3.73\times$, and $2.27\times$. For offloading setting on L40, Sequoia achieves as low as 0.56 s/token for exact Llama2-70B inference latency, which is $9.96\times$ on our optimized offloading system (5.6 s/token), $9.7\times$ than DeepSpeed-Zero-Inference, $19.5\times$ than Huggingface Accelerate.
SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression
Jun 05, 2023

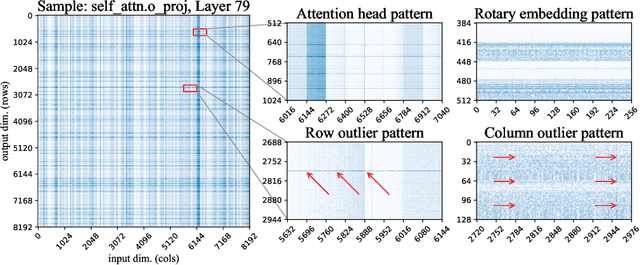

Recent advances in large language model (LLM) pretraining have led to high-quality LLMs with impressive abilities. By compressing such LLMs via quantization to 3-4 bits per parameter, they can fit into memory-limited devices such as laptops and mobile phones, enabling personalized use. However, quantization down to 3-4 bits per parameter usually leads to moderate-to-high accuracy losses, especially for smaller models in the 1-10B parameter range, which are well-suited for edge deployments. To address this accuracy issue, we introduce the Sparse-Quantized Representation (SpQR), a new compressed format and quantization technique which enables for the first time near-lossless compression of LLMs across model scales, while reaching similar compression levels to previous methods. SpQR works by identifying and isolating outlier weights, which cause particularly-large quantization errors, and storing them in higher precision, while compressing all other weights to 3-4 bits, and achieves relative accuracy losses of less than 1% in perplexity for highly-accurate LLaMA and Falcon LLMs. This makes it possible to run 33B parameter LLM on a single 24 GB consumer GPU without any performance degradation at 15% speedup thus making powerful LLMs available to consumer without any downsides. SpQR comes with efficient algorithms for both encoding weights into its format, as well as decoding them efficiently at runtime. Specifically, we provide an efficient GPU inference algorithm for SpQR which yields faster inference than 16-bit baselines at similar accuracy, while enabling memory compression gains of more than 4x.