 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Autoregressive Models for Generative Image Classification
Mar 19, 2026Class-conditional generative models have emerged as accurate and robust classifiers, with diffusion models demonstrating clear advantages over other visual generative paradigms, including autoregressive (AR) models. In this work, we revisit visual AR-based generative classifiers and identify an important limitation of prior approaches: their reliance on a fixed token order, which imposes a restrictive inductive bias for image understanding. We observe that single-order predictions rely more on partial discriminative cues, while averaging over multiple token orders provides a more comprehensive signal. Based on this insight, we leverage recent any-order AR models to estimate order-marginalized predictions, unlocking the high classification potential of AR models. Our approach consistently outperforms diffusion-based classifiers across diverse image classification benchmarks, while being up to 25x more efficient. Compared to state-of-the-art self-supervised discriminative models, our method delivers competitive classification performance - a notable achievement for generative classifiers.
Rethinking Global Text Conditioning in Diffusion Transformers
Feb 09, 2026Diffusion transformers typically incorporate textual information via attention layers and a modulation mechanism using a pooled text embedding. Nevertheless, recent approaches discard modulation-based text conditioning and rely exclusively on attention. In this paper, we address whether modulation-based text conditioning is necessary and whether it can provide any performance advantage. Our analysis shows that, in its conventional usage, the pooled embedding contributes little to overall performance, suggesting that attention alone is generally sufficient for faithfully propagating prompt information. However, we reveal that the pooled embedding can provide significant gains when used from a different perspective-serving as guidance and enabling controllable shifts toward more desirable properties. This approach is training-free, simple to implement, incurs negligible runtime overhead, and can be applied to various diffusion models, bringing improvements across diverse tasks, including text-to-image/video generation and image editing.
MADrive: Memory-Augmented Driving Scene Modeling
Jun 26, 2025Recent advances in scene reconstruction have pushed toward highly realistic modeling of autonomous driving (AD) environments using 3D Gaussian splatting. However, the resulting reconstructions remain closely tied to the original observations and struggle to support photorealistic synthesis of significantly altered or novel driving scenarios. This work introduces MADrive, a memory-augmented reconstruction framework designed to extend the capabilities of existing scene reconstruction methods by replacing observed vehicles with visually similar 3D assets retrieved from a large-scale external memory bank. Specifically, we release MAD-Cars, a curated dataset of ${\sim}70$K 360{\deg} car videos captured in the wild and present a retrieval module that finds the most similar car instances in the memory bank, reconstructs the corresponding 3D assets from video, and integrates them into the target scene through orientation alignment and relighting. The resulting replacements provide complete multi-view representations of vehicles in the scene, enabling photorealistic synthesis of substantially altered configurations, as demonstrated in our experiments. Project page: https://yandex-research.github.io/madrive/
Alchemist: Turning Public Text-to-Image Data into Generative Gold
May 25, 2025Pre-training equips text-to-image (T2I) models with broad world knowledge, but this alone is often insufficient to achieve high aesthetic quality and alignment. Consequently, supervised fine-tuning (SFT) is crucial for further refinement. However, its effectiveness highly depends on the quality of the fine-tuning dataset. Existing public SFT datasets frequently target narrow domains (e.g., anime or specific art styles), and the creation of high-quality, general-purpose SFT datasets remains a significant challenge. Current curation methods are often costly and struggle to identify truly impactful samples. This challenge is further complicated by the scarcity of public general-purpose datasets, as leading models often rely on large, proprietary, and poorly documented internal data, hindering broader research progress. This paper introduces a novel methodology for creating general-purpose SFT datasets by leveraging a pre-trained generative model as an estimator of high-impact training samples. We apply this methodology to construct and release Alchemist, a compact (3,350 samples) yet highly effective SFT dataset. Experiments demonstrate that Alchemist substantially improves the generative quality of five public T2I models while preserving diversity and style. Additionally, we release the fine-tuned models' weights to the public.
CasTex: Cascaded Text-to-Texture Synthesis via Explicit Texture Maps and Physically-Based Shading
Apr 09, 2025This work investigates text-to-texture synthesis using diffusion models to generate physically-based texture maps. We aim to achieve realistic model appearances under varying lighting conditions. A prominent solution for the task is score distillation sampling. It allows recovering a complex texture using gradient guidance given a differentiable rasterization and shading pipeline. However, in practice, the aforementioned solution in conjunction with the widespread latent diffusion models produces severe visual artifacts and requires additional regularization such as implicit texture parameterization. As a more direct alternative, we propose an approach using cascaded diffusion models for texture synthesis (CasTex). In our setup, score distillation sampling yields high-quality textures out-of-the box. In particular, we were able to omit implicit texture parameterization in favor of an explicit parameterization to improve the procedure. In the experiments, we show that our approach significantly outperforms state-of-the-art optimization-based solutions on public texture synthesis benchmarks.
Scale-wise Distillation of Diffusion Models
Mar 20, 2025



We present SwD, a scale-wise distillation framework for diffusion models (DMs), which effectively employs next-scale prediction ideas for diffusion-based few-step generators. In more detail, SwD is inspired by the recent insights relating diffusion processes to the implicit spectral autoregression. We suppose that DMs can initiate generation at lower data resolutions and gradually upscale the samples at each denoising step without loss in performance while significantly reducing computational costs. SwD naturally integrates this idea into existing diffusion distillation methods based on distribution matching. Also, we enrich the family of distribution matching approaches by introducing a novel patch loss enforcing finer-grained similarity to the target distribution. When applied to state-of-the-art text-to-image diffusion models, SwD approaches the inference times of two full resolution steps and significantly outperforms the counterparts under the same computation budget, as evidenced by automated metrics and human preference studies.
Inverse Bridge Matching Distillation
Feb 03, 2025Learning diffusion bridge models is easy; making them fast and practical is an art. Diffusion bridge models (DBMs) are a promising extension of diffusion models for applications in image-to-image translation. However, like many modern diffusion and flow models, DBMs suffer from the problem of slow inference. To address it, we propose a novel distillation technique based on the inverse bridge matching formulation and derive the tractable objective to solve it in practice. Unlike previously developed DBM distillation techniques, the proposed method can distill both conditional and unconditional types of DBMs, distill models in a one-step generator, and use only the corrupted images for training. We evaluate our approach for both conditional and unconditional types of bridge matching on a wide set of setups, including super-resolution, JPEG restoration, sketch-to-image, and other tasks, and show that our distillation technique allows us to accelerate the inference of DBMs from 4x to 100x and even provide better generation quality than used teacher model depending on particular setup.
Switti: Designing Scale-Wise Transformers for Text-to-Image Synthesis
Dec 03, 2024
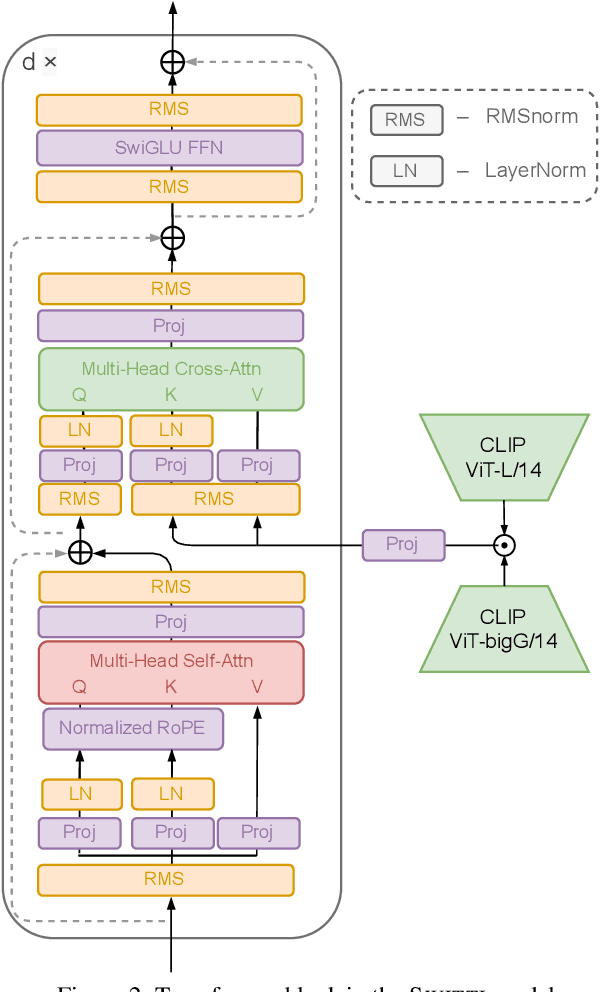

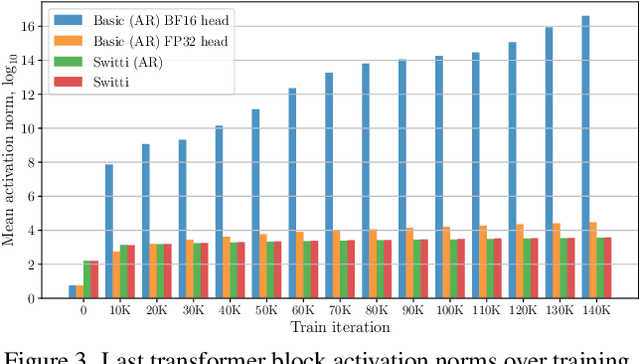
This work presents Switti, a scale-wise transformer for text-to-image generation. Starting from existing next-scale prediction AR models, we first explore them for T2I generation and propose architectural modifications to improve their convergence and overall performance. We then observe that self-attention maps of our pretrained scale-wise AR model exhibit weak dependence on preceding scales. Based on this insight, we propose a non-AR counterpart facilitating ~11% faster sampling and lower memory usage while also achieving slightly better generation quality. Furthermore, we reveal that classifier-free guidance at high-resolution scales is often unnecessary and can even degrade performance. By disabling guidance at these scales, we achieve an additional sampling acceleration of ~20% and improve the generation of fine-grained details. Extensive human preference studies and automated evaluations show that Switti outperforms existing T2I AR models and competes with state-of-the-art T2I diffusion models while being up to 7 times faster.
Inverse Entropic Optimal Transport Solves Semi-supervised Learning via Data Likelihood Maximization
Oct 03, 2024



Learning conditional distributions $\pi^*(\cdot|x)$ is a central problem in machine learning, which is typically approached via supervised methods with paired data $(x,y) \sim \pi^*$. However, acquiring paired data samples is often challenging, especially in problems such as domain translation. This necessitates the development of $\textit{semi-supervised}$ models that utilize both limited paired data and additional unpaired i.i.d. samples $x \sim \pi^*_x$ and $y \sim \pi^*_y$ from the marginal distributions. The usage of such combined data is complex and often relies on heuristic approaches. To tackle this issue, we propose a new learning paradigm that integrates both paired and unpaired data $\textbf{seamlessly}$ through the data likelihood maximization techniques. We demonstrate that our approach also connects intriguingly with inverse entropic optimal transport (OT). This finding allows us to apply recent advances in computational OT to establish a $\textbf{light}$ learning algorithm to get $\pi^*(\cdot|x)$. Furthermore, we demonstrate through empirical tests that our method effectively learns conditional distributions using paired and unpaired data simultaneously.
Results of the Big ANN: NeurIPS'23 competition
Sep 25, 2024

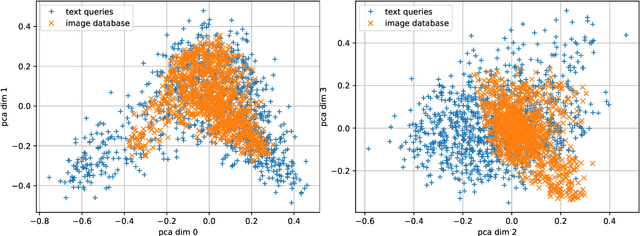

The 2023 Big ANN Challenge, held at NeurIPS 2023, focused on advancing the state-of-the-art in indexing data structures and search algorithms for practical variants of Approximate Nearest Neighbor (ANN) search that reflect the growing complexity and diversity of workloads. Unlike prior challenges that emphasized scaling up classical ANN search ~\cite{DBLP:conf/nips/SimhadriWADBBCH21}, this competition addressed filtered search, out-of-distribution data, sparse and streaming variants of ANNS. Participants developed and submitted innovative solutions that were evaluated on new standard datasets with constrained computational resources. The results showcased significant improvements in search accuracy and efficiency over industry-standard baselines, with notable contributions from both academic and industrial teams. This paper summarizes the competition tracks, datasets, evaluation metrics, and the innovative approaches of the top-performing submissions, providing insights into the current advancements and future directions in the field of approximate nearest neighbor search.