 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Global Text Conditioning in Diffusion Transformers
Feb 09, 2026Diffusion transformers typically incorporate textual information via attention layers and a modulation mechanism using a pooled text embedding. Nevertheless, recent approaches discard modulation-based text conditioning and rely exclusively on attention. In this paper, we address whether modulation-based text conditioning is necessary and whether it can provide any performance advantage. Our analysis shows that, in its conventional usage, the pooled embedding contributes little to overall performance, suggesting that attention alone is generally sufficient for faithfully propagating prompt information. However, we reveal that the pooled embedding can provide significant gains when used from a different perspective-serving as guidance and enabling controllable shifts toward more desirable properties. This approach is training-free, simple to implement, incurs negligible runtime overhead, and can be applied to various diffusion models, bringing improvements across diverse tasks, including text-to-image/video generation and image editing.
Scale-wise Distillation of Diffusion Models
Mar 20, 2025



We present SwD, a scale-wise distillation framework for diffusion models (DMs), which effectively employs next-scale prediction ideas for diffusion-based few-step generators. In more detail, SwD is inspired by the recent insights relating diffusion processes to the implicit spectral autoregression. We suppose that DMs can initiate generation at lower data resolutions and gradually upscale the samples at each denoising step without loss in performance while significantly reducing computational costs. SwD naturally integrates this idea into existing diffusion distillation methods based on distribution matching. Also, we enrich the family of distribution matching approaches by introducing a novel patch loss enforcing finer-grained similarity to the target distribution. When applied to state-of-the-art text-to-image diffusion models, SwD approaches the inference times of two full resolution steps and significantly outperforms the counterparts under the same computation budget, as evidenced by automated metrics and human preference studies.
Inverse Entropic Optimal Transport Solves Semi-supervised Learning via Data Likelihood Maximization
Oct 03, 2024



Learning conditional distributions $\pi^*(\cdot|x)$ is a central problem in machine learning, which is typically approached via supervised methods with paired data $(x,y) \sim \pi^*$. However, acquiring paired data samples is often challenging, especially in problems such as domain translation. This necessitates the development of $\textit{semi-supervised}$ models that utilize both limited paired data and additional unpaired i.i.d. samples $x \sim \pi^*_x$ and $y \sim \pi^*_y$ from the marginal distributions. The usage of such combined data is complex and often relies on heuristic approaches. To tackle this issue, we propose a new learning paradigm that integrates both paired and unpaired data $\textbf{seamlessly}$ through the data likelihood maximization techniques. We demonstrate that our approach also connects intriguingly with inverse entropic optimal transport (OT). This finding allows us to apply recent advances in computational OT to establish a $\textbf{light}$ learning algorithm to get $\pi^*(\cdot|x)$. Furthermore, we demonstrate through empirical tests that our method effectively learns conditional distributions using paired and unpaired data simultaneously.
Invertible Consistency Distillation for Text-Guided Image Editing in Around 7 Steps
Jun 20, 2024
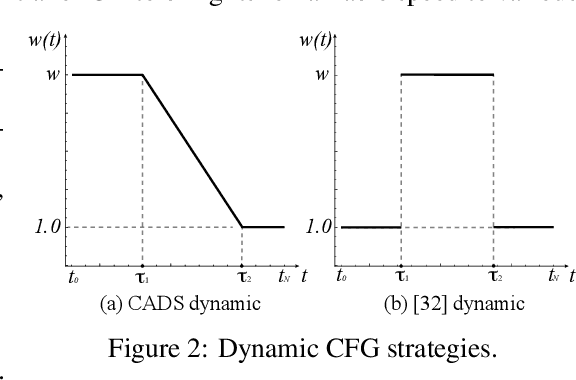


Diffusion distillation represents a highly promising direction for achieving faithful text-to-image generation in a few sampling steps. However, despite recent successes, existing distilled models still do not provide the full spectrum of diffusion abilities, such as real image inversion, which enables many precise image manipulation methods. This work aims to enrich distilled text-to-image diffusion models with the ability to effectively encode real images into their latent space. To this end, we introduce invertible Consistency Distillation (iCD), a generalized consistency distillation framework that facilitates both high-quality image synthesis and accurate image encoding in only 3-4 inference steps. Though the inversion problem for text-to-image diffusion models gets exacerbated by high classifier-free guidance scales, we notice that dynamic guidance significantly reduces reconstruction errors without noticeable degradation in generation performance. As a result, we demonstrate that iCD equipped with dynamic guidance may serve as a highly effective tool for zero-shot text-guided image editing, competing with more expensive state-of-the-art alternatives.
Your Student is Better Than Expected: Adaptive Teacher-Student Collaboration for Text-Conditional Diffusion Models
Dec 28, 2023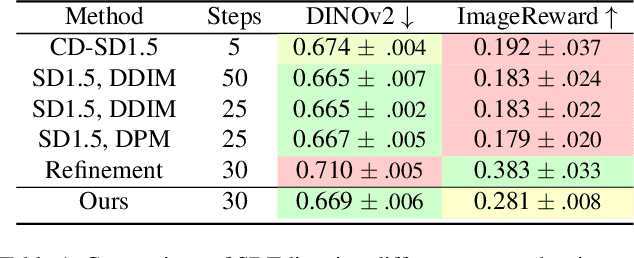

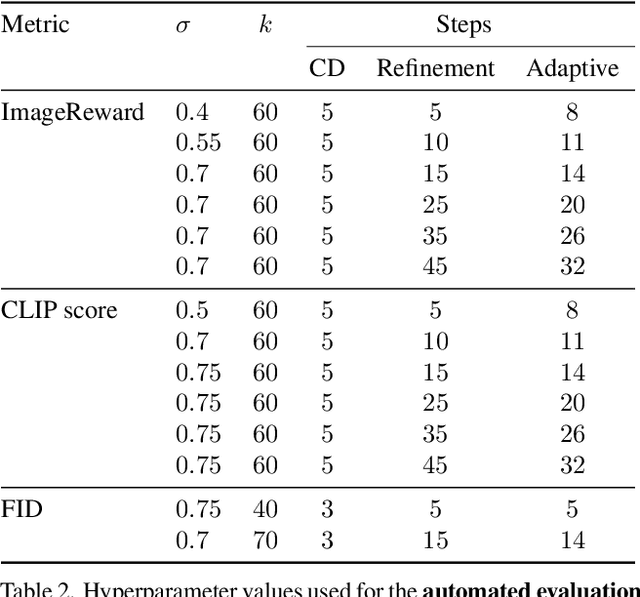

Knowledge distillation methods have recently shown to be a promising direction to speedup the synthesis of large-scale diffusion models by requiring only a few inference steps. While several powerful distillation methods were recently proposed, the overall quality of student samples is typically lower compared to the teacher ones, which hinders their practical usage. In this work, we investigate the relative quality of samples produced by the teacher text-to-image diffusion model and its distilled student version. As our main empirical finding, we discover that a noticeable portion of student samples exhibit superior fidelity compared to the teacher ones, despite the ``approximate'' nature of the student. Based on this finding, we propose an adaptive collaboration between student and teacher diffusion models for effective text-to-image synthesis. Specifically, the distilled model produces the initial sample, and then an oracle decides whether it needs further improvements with a slow teacher model. Extensive experiments demonstrate that the designed pipeline surpasses state-of-the-art text-to-image alternatives for various inference budgets in terms of human preference. Furthermore, the proposed approach can be naturally used in popular applications such as text-guided image editing and controllable generation.
Towards Real-time Text-driven Image Manipulation with Unconditional Diffusion Models
Apr 10, 2023



Recent advances in diffusion models enable many powerful instruments for image editing. One of these instruments is text-driven image manipulations: editing semantic attributes of an image according to the provided text description. % Popular text-conditional diffusion models offer various high-quality image manipulation methods for a broad range of text prompts. Existing diffusion-based methods already achieve high-quality image manipulations for a broad range of text prompts. However, in practice, these methods require high computation costs even with a high-end GPU. This greatly limits potential real-world applications of diffusion-based image editing, especially when running on user devices. In this paper, we address efficiency of the recent text-driven editing methods based on unconditional diffusion models and develop a novel algorithm that learns image manipulations 4.5-10 times faster and applies them 8 times faster. We carefully evaluate the visual quality and expressiveness of our approach on multiple datasets using human annotators. Our experiments demonstrate that our algorithm achieves the quality of much more expensive methods. Finally, we show that our approach can adapt the pretrained model to the user-specified image and text description on the fly just for 4 seconds. In this setting, we notice that more compact unconditional diffusion models can be considered as a rational alternative to the popular text-conditional counterparts.