 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwitti: Designing Scale-Wise Transformers for Text-to-Image Synthesis
Dec 03, 2024
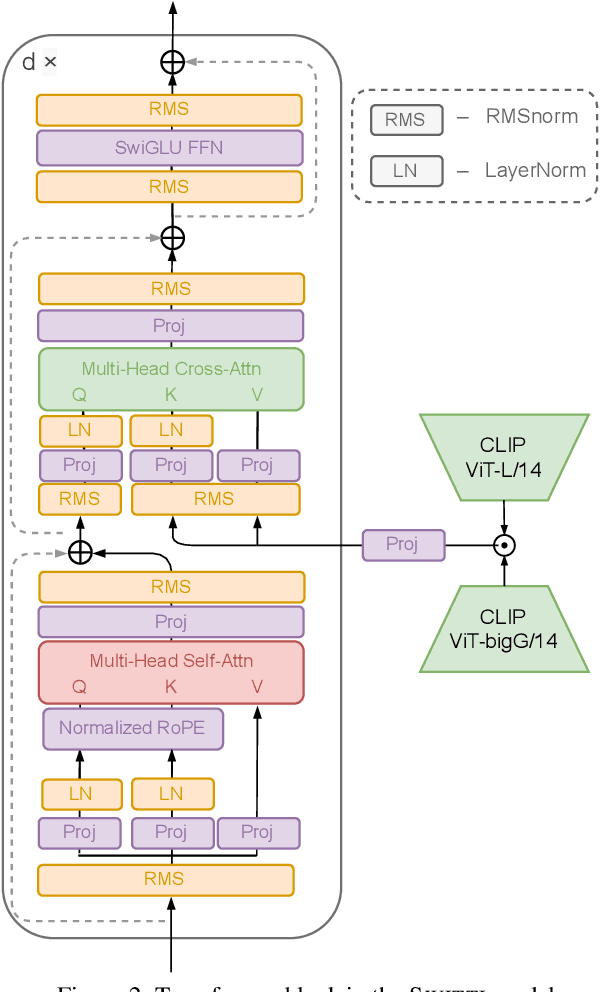

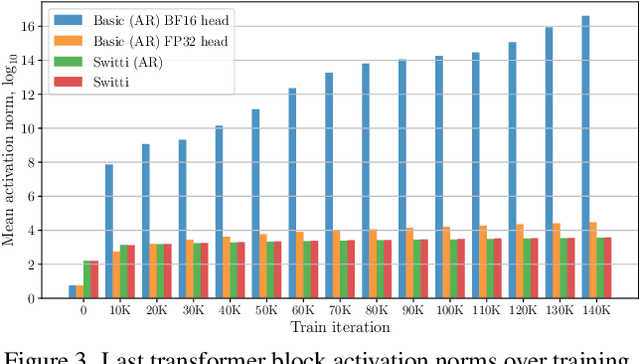
This work presents Switti, a scale-wise transformer for text-to-image generation. Starting from existing next-scale prediction AR models, we first explore them for T2I generation and propose architectural modifications to improve their convergence and overall performance. We then observe that self-attention maps of our pretrained scale-wise AR model exhibit weak dependence on preceding scales. Based on this insight, we propose a non-AR counterpart facilitating ~11% faster sampling and lower memory usage while also achieving slightly better generation quality. Furthermore, we reveal that classifier-free guidance at high-resolution scales is often unnecessary and can even degrade performance. By disabling guidance at these scales, we achieve an additional sampling acceleration of ~20% and improve the generation of fine-grained details. Extensive human preference studies and automated evaluations show that Switti outperforms existing T2I AR models and competes with state-of-the-art T2I diffusion models while being up to 7 times faster.
Invertible Consistency Distillation for Text-Guided Image Editing in Around 7 Steps
Jun 20, 2024
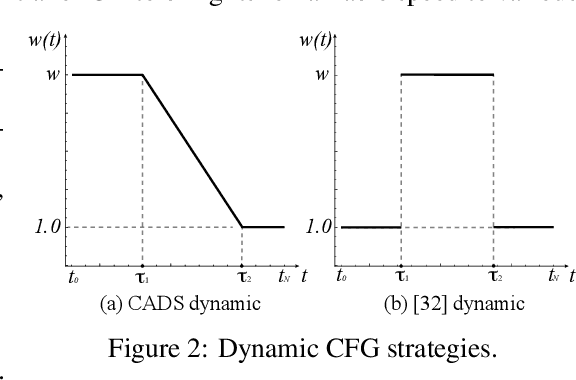


Diffusion distillation represents a highly promising direction for achieving faithful text-to-image generation in a few sampling steps. However, despite recent successes, existing distilled models still do not provide the full spectrum of diffusion abilities, such as real image inversion, which enables many precise image manipulation methods. This work aims to enrich distilled text-to-image diffusion models with the ability to effectively encode real images into their latent space. To this end, we introduce invertible Consistency Distillation (iCD), a generalized consistency distillation framework that facilitates both high-quality image synthesis and accurate image encoding in only 3-4 inference steps. Though the inversion problem for text-to-image diffusion models gets exacerbated by high classifier-free guidance scales, we notice that dynamic guidance significantly reduces reconstruction errors without noticeable degradation in generation performance. As a result, we demonstrate that iCD equipped with dynamic guidance may serve as a highly effective tool for zero-shot text-guided image editing, competing with more expensive state-of-the-art alternatives.
Is This Loss Informative? Speeding Up Textual Inversion with Deterministic Objective Evaluation
Feb 09, 2023Text-to-image generation models represent the next step of evolution in image synthesis, offering natural means of flexible yet fine-grained control over the result. One emerging area of research is the rapid adaptation of large text-to-image models to smaller datasets or new visual concepts. However, the most efficient method of adaptation, called textual inversion, has a known limitation of long training time, which both restricts practical applications and increases the experiment time for research. In this work, we study the training dynamics of textual inversion, aiming to speed it up. We observe that most concepts are learned at early stages and do not improve in quality later, but standard model convergence metrics fail to indicate that. Instead, we propose a simple early stopping criterion that only requires computing the textual inversion loss on the same inputs for all training iterations. Our experiments on both Latent Diffusion and Stable Diffusion models for 93 concepts demonstrate the competitive performance of our method, speeding adaptation up to 15 times with no significant drops in quality.