 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwitti: Designing Scale-Wise Transformers for Text-to-Image Synthesis
Paper and Code

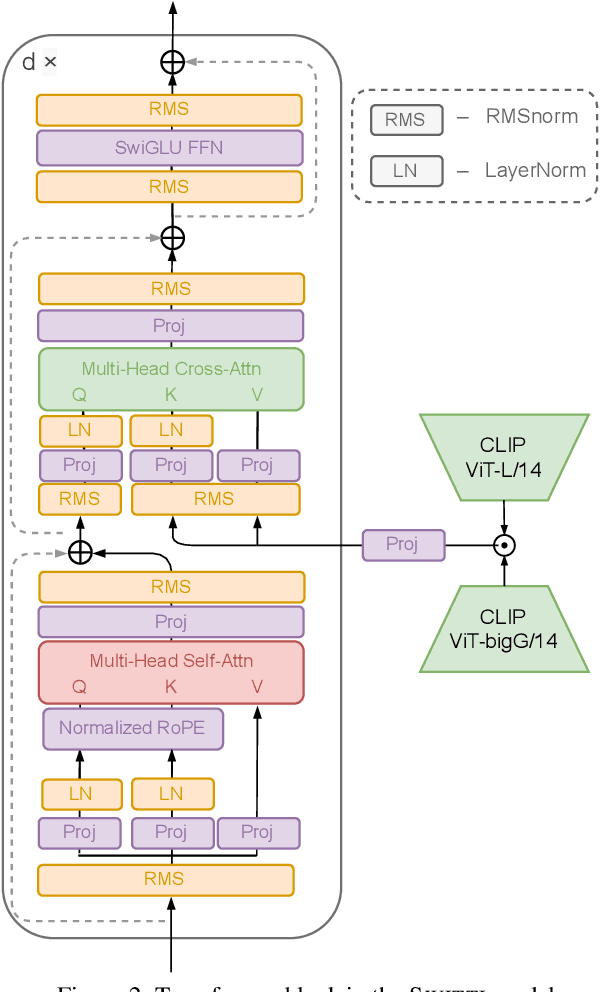

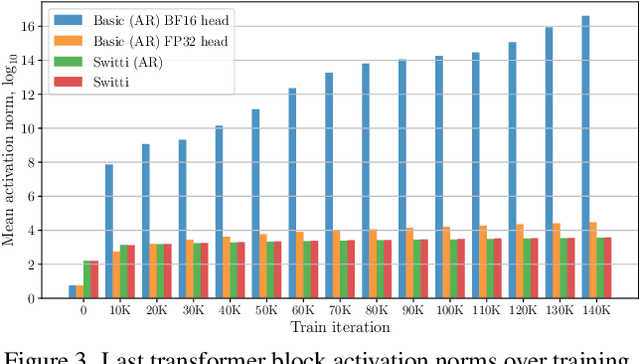
This work presents Switti, a scale-wise transformer for text-to-image generation. Starting from existing next-scale prediction AR models, we first explore them for T2I generation and propose architectural modifications to improve their convergence and overall performance. We then observe that self-attention maps of our pretrained scale-wise AR model exhibit weak dependence on preceding scales. Based on this insight, we propose a non-AR counterpart facilitating ~11% faster sampling and lower memory usage while also achieving slightly better generation quality. Furthermore, we reveal that classifier-free guidance at high-resolution scales is often unnecessary and can even degrade performance. By disabling guidance at these scales, we achieve an additional sampling acceleration of ~20% and improve the generation of fine-grained details. Extensive human preference studies and automated evaluations show that Switti outperforms existing T2I AR models and competes with state-of-the-art T2I diffusion models while being up to 7 times faster.