 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Advantage Fields
Jun 02, 2026Offline goal-conditioned reinforcement learning requires both long-horizon reachability estimates and local action comparisons. Dual goal representations provide value fields that capture global goal reachability, but they do not directly specify which action should be preferred at a given state. We propose Dual Advantage Fields, a policy-extraction method that turns a bilinear dual value model into a local advantage signal. Under bilinear dual parameterization, the goal embedding is the gradient of the value field with respect to the state representation. DAF learns an action-effect model that predicts the discounted feature displacement induced by an action and scores actions by the alignment between this displacement and the goal direction. In the realizable case, this score equals the goal-conditioned Bellman advantage, yielding a standard local policy-improvement guarantee. On OGBench locomotion, manipulation, and puzzle tasks, DAF improves aggregate RLiable metrics and performs strongly in settings where locally correct actions differ from direct movement toward the final goal.
Convex Compositional Reasoning Models
May 25, 2026Compositional energy-based models can generalize to larger combinatorial reasoning problems by reusing a learned factor energy across many local constraints. In our paper, we show that a key bottleneck in compositional reasoning is not composition itself, but the non-convex geometry of the learned energy landscape. To solve this problem, we introduce Convex Compositional Energy Minimization (CCEM), a framework that parameterizes each factor with an input-convex neural network and optimizes the composed energy over a tight convex relaxation of the feasible set. Because convexity is preserved under summation, the global relaxed objective remains convex, enabling deterministic projected first-order optimization. CCEM is trained in two stages: factor-level contrastive learning to shape local energy basins, followed by end-to-end refinement through an unrolled projected solver. Our experiments show that our models trained on small subproblems or a single problem size transfer to larger instances without retraining.
Value-Gradient Hypothesis of RL for LLMs
May 20, 2026Reinforcement learning substantially improves pretrained language models, but it remains understudied why critic-free methods such as PPO and GRPO work as well as they do, and when they should provide the largest gains. We develop a value-gradient perspective of critic-free RL for LLM post-training. First, under a differentiable rollout and additive-noise parameterization, we show that the actor update is value-gradient-like in expectation: the backward pass propagates costates whose conditional expectation equals the value gradient. Second, for discrete transformer policies, we show that autodifferentiation through attention produces empirical costates that approximate this value signal, with an error controlled by the sampling gap and policy entropy. These results motivate a decomposition of RL impact into value gradient signal and reachable reward headroom, yielding a criterion for when RL should be most effective along a pretraining trajectory.
Zero-shot adaptation to order book dynamics
May 20, 2026We describe an adaptive market-making architecture that preserves the analytical structure of the Avellaneda--Stoikov framework while introducing a successor measure-style adaptation mechanism. In our paper we keep Avellaneda--Stoikov fast Hamilton--Jacobi--Bellman structure and make it adaptive to changing market regimes and trading objectives. The central idea is to separate market dynamics from the trading objective. The market state determines a low-dimensional set of Avellaneda--Stoikov parameters, while recent realized rewards determine a low-dimensional objective vector. The HJB forward map then converts this objective into optimal bid and ask quotes through a scalarization of future reward features.
Guess & Guide: Gradient-Free Zero-Shot Diffusion Guidance
Mar 09, 2026Pretrained diffusion models serve as effective priors for Bayesian inverse problems. These priors enable zero-shot generation by sampling from the conditional distribution, which avoids the need for task-specific retraining. However, a major limitation of existing methods is their reliance on surrogate likelihoods that require vector-Jacobian products at each denoising step, creating a substantial computational burden. To address this, we introduce a lightweight likelihood surrogate that eliminates the need to calculate gradients through the denoiser network. This enables us to handle diverse inverse problems without backpropagation overhead. Experiments confirm that using our method, the inference cost drops dramatically. At the same time, our approach delivers the highest results in multiple tasks. Broadly speaking, we propose the fastest and Pareto optimal method for Bayesian inverse problems.
Zero-Shot Off-Policy Learning
Feb 02, 2026Off-policy learning methods seek to derive an optimal policy directly from a fixed dataset of prior interactions. This objective presents significant challenges, primarily due to the inherent distributional shift and value function overestimation bias. These issues become even more noticeable in zero-shot reinforcement learning, where an agent trained on reward-free data must adapt to new tasks at test time without additional training. In this work, we address the off-policy problem in a zero-shot setting by discovering a theoretical connection of successor measures to stationary density ratios. Using this insight, our algorithm can infer optimal importance sampling ratios, effectively performing a stationary distribution correction with an optimal policy for any task on the fly. We benchmark our method in motion tracking tasks on SMPL Humanoid, continuous control on ExoRL, and for the long-horizon OGBench tasks. Our technique seamlessly integrates into forward-backward representation frameworks and enables fast-adaptation to new tasks in a training-free regime. More broadly, this work bridges off-policy learning and zero-shot adaptation, offering benefits to both research areas.
Expert or not? assessing data quality in offline reinforcement learning
Oct 14, 2025Offline reinforcement learning (RL) learns exclusively from static datasets, without further interaction with the environment. In practice, such datasets vary widely in quality, often mixing expert, suboptimal, and even random trajectories. The choice of algorithm therefore depends on dataset fidelity. Behavior cloning can suffice on high-quality data, whereas mixed- or low-quality data typically benefits from offline RL methods that stitch useful behavior across trajectories. Yet in the wild it is difficult to assess dataset quality a priori because the data's provenance and skill composition are unknown. We address the problem of estimating offline dataset quality without training an agent. We study a spectrum of proxies from simple cumulative rewards to learned value based estimators, and introduce the Bellman Wasserstein distance (BWD), a value aware optimal transport score that measures how dissimilar a dataset's behavioral policy is from a random reference policy. BWD is computed from a behavioral critic and a state conditional OT formulation, requiring no environment interaction or full policy optimization. Across D4RL MuJoCo tasks, BWD strongly correlates with an oracle performance score that aggregates multiple offline RL algorithms, enabling efficient prediction of how well standard agents will perform on a given dataset. Beyond prediction, integrating BWD as a regularizer during policy optimization explicitly pushes the learned policy away from random behavior and improves returns. These results indicate that value aware, distributional signals such as BWD are practical tools for triaging offline RL datasets and policy optimization.
Rethinking Optimal Transport in Offline Reinforcement Learning
Oct 17, 2024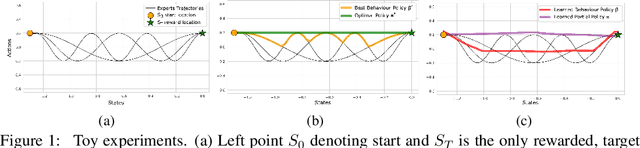
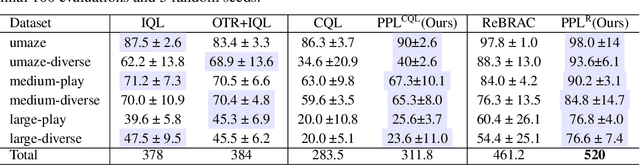
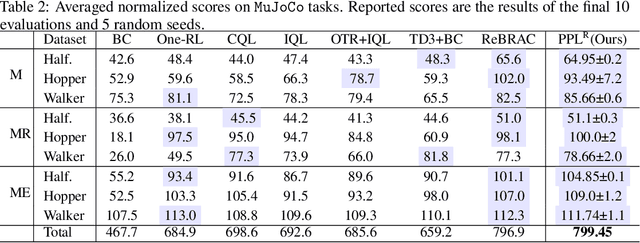
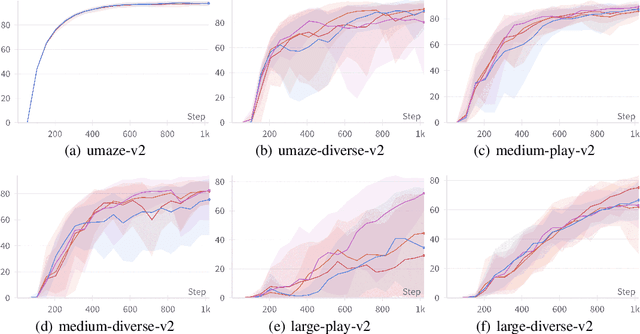
We propose a novel algorithm for offline reinforcement learning using optimal transport. Typically, in offline reinforcement learning, the data is provided by various experts and some of them can be sub-optimal. To extract an efficient policy, it is necessary to \emph{stitch} the best behaviors from the dataset. To address this problem, we rethink offline reinforcement learning as an optimal transportation problem. And based on this, we present an algorithm that aims to find a policy that maps states to a \emph{partial} distribution of the best expert actions for each given state. We evaluate the performance of our algorithm on continuous control problems from the D4RL suite and demonstrate improvements over existing methods.
Inverse Entropic Optimal Transport Solves Semi-supervised Learning via Data Likelihood Maximization
Oct 03, 2024



Learning conditional distributions $\pi^*(\cdot|x)$ is a central problem in machine learning, which is typically approached via supervised methods with paired data $(x,y) \sim \pi^*$. However, acquiring paired data samples is often challenging, especially in problems such as domain translation. This necessitates the development of $\textit{semi-supervised}$ models that utilize both limited paired data and additional unpaired i.i.d. samples $x \sim \pi^*_x$ and $y \sim \pi^*_y$ from the marginal distributions. The usage of such combined data is complex and often relies on heuristic approaches. To tackle this issue, we propose a new learning paradigm that integrates both paired and unpaired data $\textbf{seamlessly}$ through the data likelihood maximization techniques. We demonstrate that our approach also connects intriguingly with inverse entropic optimal transport (OT). This finding allows us to apply recent advances in computational OT to establish a $\textbf{light}$ learning algorithm to get $\pi^*(\cdot|x)$. Furthermore, we demonstrate through empirical tests that our method effectively learns conditional distributions using paired and unpaired data simultaneously.
Adversarial Training Improves Joint Energy-Based Generative Modelling
Jul 18, 2022

We propose the novel framework for generative modelling using hybrid energy-based models. In our method we combine the interpretable input gradients of the robust classifier and Langevin Dynamics for sampling. Using the adversarial training we improve not only the training stability, but robustness and generative modelling of the joint energy-based models.