 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Optimal Transport in Offline Reinforcement Learning
Oct 17, 2024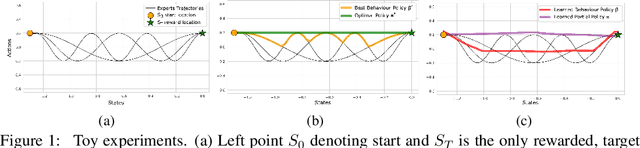
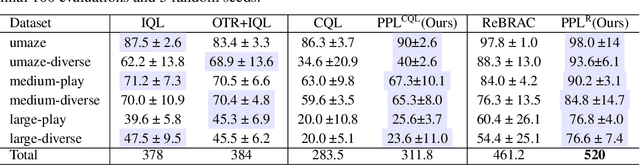
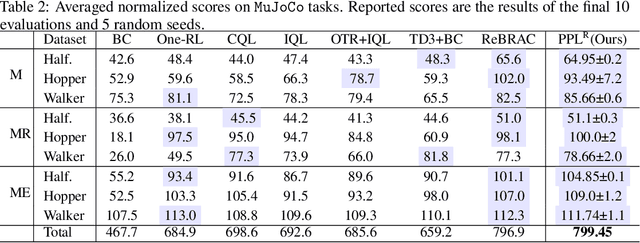
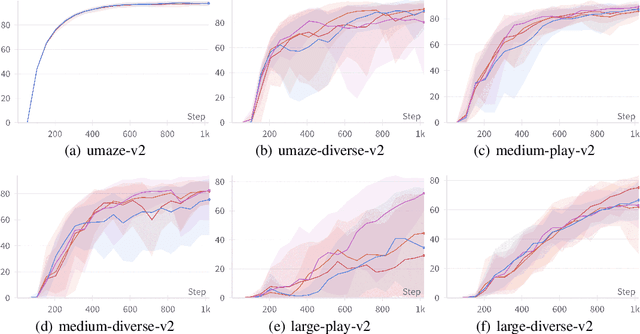
We propose a novel algorithm for offline reinforcement learning using optimal transport. Typically, in offline reinforcement learning, the data is provided by various experts and some of them can be sub-optimal. To extract an efficient policy, it is necessary to \emph{stitch} the best behaviors from the dataset. To address this problem, we rethink offline reinforcement learning as an optimal transportation problem. And based on this, we present an algorithm that aims to find a policy that maps states to a \emph{partial} distribution of the best expert actions for each given state. We evaluate the performance of our algorithm on continuous control problems from the D4RL suite and demonstrate improvements over existing methods.
Image Vectorization: a Review
Jun 10, 2023Nowadays, there are many diffusion and autoregressive models that show impressive results for generating images from text and other input domains. However, these methods are not intended for ultra-high-resolution image synthesis. Vector graphics are devoid of this disadvantage, so the generation of images in this format looks very promising. Instead of generating vector images directly, you can first synthesize a raster image and then apply vectorization. Vectorization is the process of converting a raster image into a similar vector image using primitive shapes. Besides being similar, generated vector image is also required to contain the minimum number of shapes for rendering. In this paper, we focus specifically on machine learning-compatible vectorization methods. We are considering Mang2Vec, Deep Vectorization of Technical Drawings, DiffVG, and LIVE models. We also provide a brief overview of existing online methods. We also recall other algorithmic methods, Im2Vec and ClipGEN models, but they do not participate in the comparison, since there is no open implementation of these methods or their official implementations do not work correctly. Our research shows that despite the ability to directly specify the number and type of shapes, existing machine learning methods work for a very long time and do not accurately recreate the original image. We believe that there is no fast universal automatic approach and human control is required for every method.
Neural Style Transfer for Vector Graphics
Mar 06, 2023
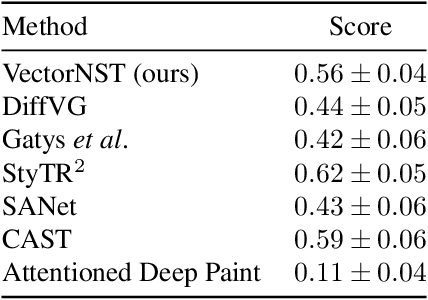
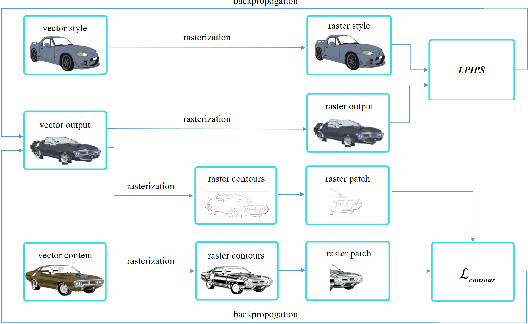
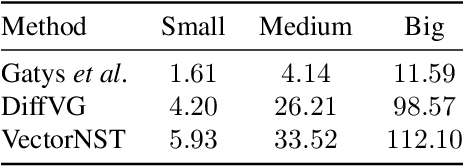
Neural style transfer draws researchers' attention, but the interest focuses on bitmap images. Various models have been developed for bitmap image generation both online and offline with arbitrary and pre-trained styles. However, the style transfer between vector images has not almost been considered. Our research shows that applying standard content and style losses insignificantly changes the vector image drawing style because the structure of vector primitives differs a lot from pixels. To handle this problem, we introduce new loss functions. We also develop a new method based on differentiable rasterization that uses these loss functions and can change the color and shape parameters of the content image corresponding to the drawing of the style image. Qualitative experiments demonstrate the effectiveness of the proposed VectorNST method compared with the state-of-the-art neural style transfer approaches for bitmap images and the only existing approach for stylizing vector images, DiffVG. Although the proposed model does not achieve the quality and smoothness of style transfer between bitmap images, we consider our work an important early step in this area. VectorNST code and demo service are available at https://github.com/IzhanVarsky/VectorNST.
Multi-step domain adaptation by adversarial attack to $\mathcal{H} Δ\mathcal{H}$-divergence
Jul 18, 2022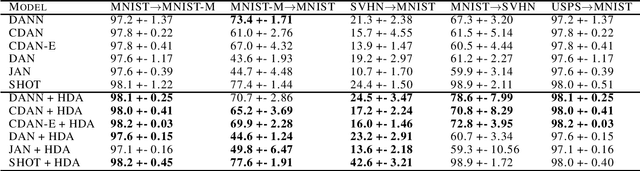

Adversarial examples are transferable between different models. In our paper, we propose to use this property for multi-step domain adaptation. In unsupervised domain adaptation settings, we demonstrate that replacing the source domain with adversarial examples to $\mathcal{H} \Delta \mathcal{H}$-divergence can improve source classifier accuracy on the target domain. Our method can be connected to most domain adaptation techniques. We conducted a range of experiments and achieved improvement in accuracy on Digits and Office-Home datasets.
Easy Batch Normalization
Jul 18, 2022
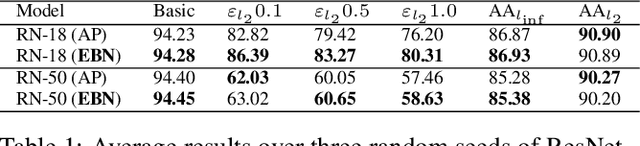
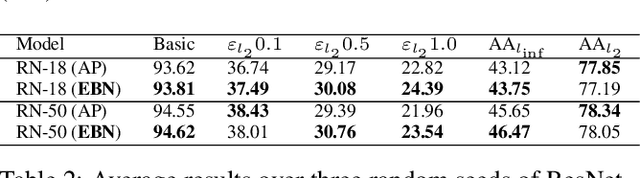
It was shown that adversarial examples improve object recognition. But what about their opposite side, easy examples? Easy examples are samples that the machine learning model classifies correctly with high confidence. In our paper, we are making the first step toward exploring the potential benefits of using easy examples in the training procedure of neural networks. We propose to use an auxiliary batch normalization for easy examples for the standard and robust accuracy improvement.
Connecting adversarial attacks and optimal transport for domain adaptation
Jun 04, 2022

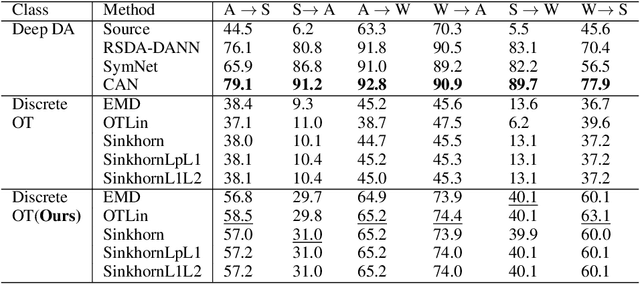
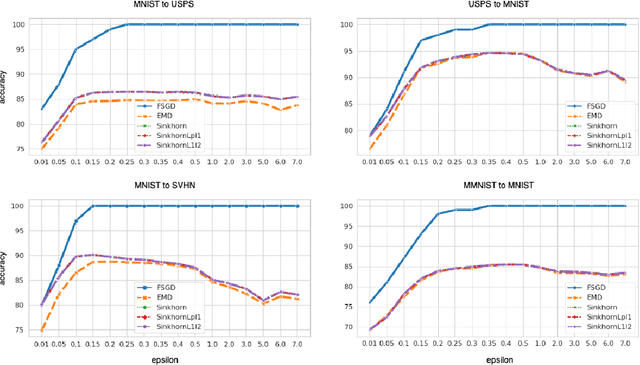
We present a novel algorithm for domain adaptation using optimal transport. In domain adaptation, the goal is to adapt a classifier trained on the source domain samples to the target domain. In our method, we use optimal transport to map target samples to the domain named source fiction. This domain differs from the source but is accurately classified by the source domain classifier. Our main idea is to generate a source fiction by c-cyclically monotone transformation over the target domain. If samples with the same labels in two domains are c-cyclically monotone, the optimal transport map between these domains preserves the class-wise structure, which is the main goal of domain adaptation. To generate a source fiction domain, we propose an algorithm that is based on our finding that adversarial attacks are a c-cyclically monotone transformation of the dataset. We conduct experiments on Digits and Modern Office-31 datasets and achieve improvement in performance for simple discrete optimal transport solvers for all adaptation tasks.
Conditional Vector Graphics Generation for Music Cover Images
May 15, 2022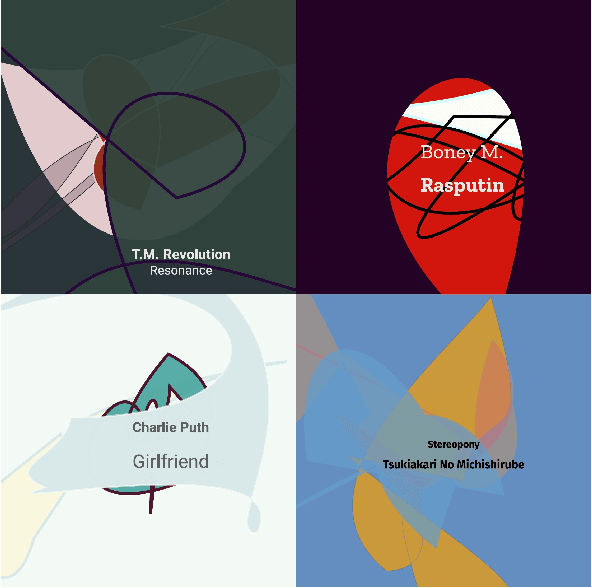
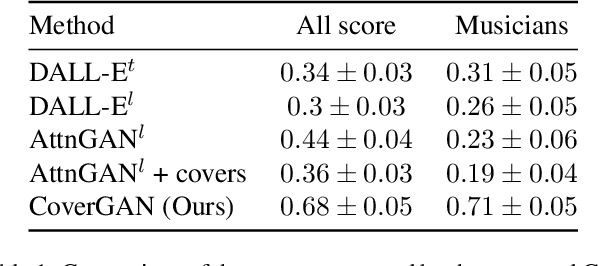

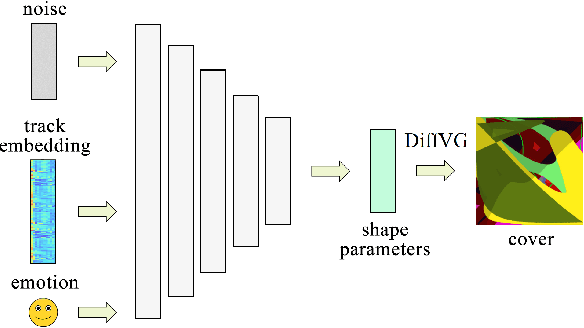
Generative Adversarial Networks (GAN) have motivated a rapid growth of the domain of computer image synthesis. As almost all the existing image synthesis algorithms consider an image as a pixel matrix, the high-resolution image synthesis is complicated.A good alternative can be vector images. However, they belong to the highly sophisticated parametric space, which is a restriction for solving the task of synthesizing vector graphics by GANs. In this paper, we consider a specific application domain that softens this restriction dramatically allowing the usage of vector image synthesis. Music cover images should meet the requirements of Internet streaming services and printing standards, which imply high resolution of graphic materials without any additional requirements on the content of such images. Existing music cover image generation services do not analyze tracks themselves; however, some services mostly consider only genre tags. To generate music covers as vector images that reflect the music and consist of simple geometric objects, we suggest a GAN-based algorithm called CoverGAN. The assessment of resulting images is based on their correspondence to the music compared with AttnGAN and DALL-E text-to-image generation according to title or lyrics. Moreover, the significance of the patterns found by CoverGAN has been evaluated in terms of the correspondence of the generated cover images to the musical tracks. Listeners evaluate the music covers generated by the proposed algorithm as quite satisfactory and corresponding to the tracks. Music cover images generation code and demo are available at https://github.com/IzhanVarsky/CoverGAN.
Towards Robust Object Detection: Bayesian RetinaNet for Homoscedastic Aleatoric Uncertainty Modeling
Aug 02, 2021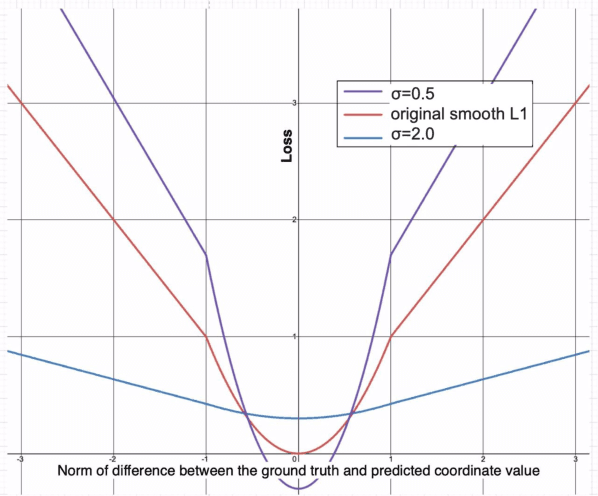
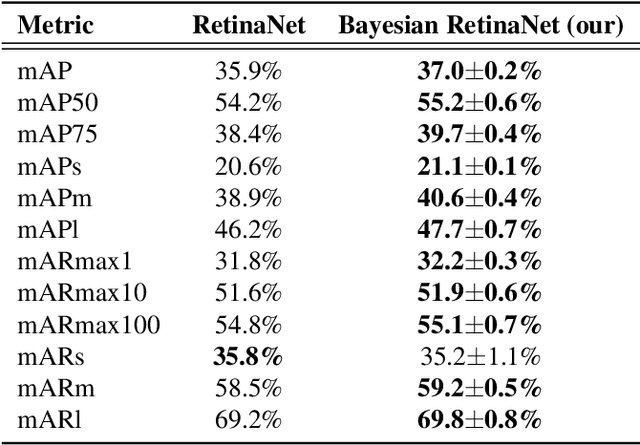
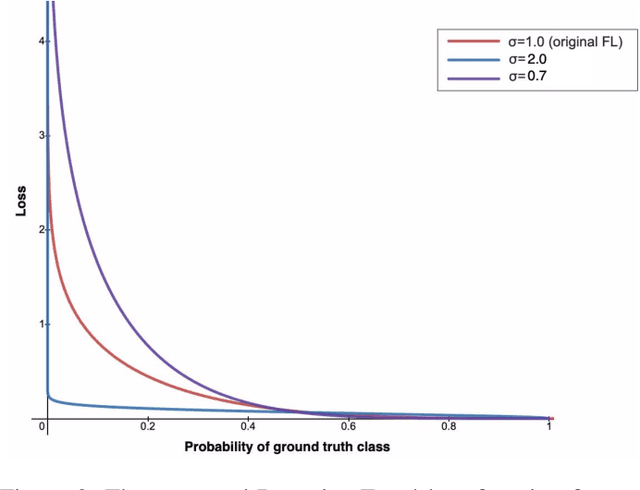
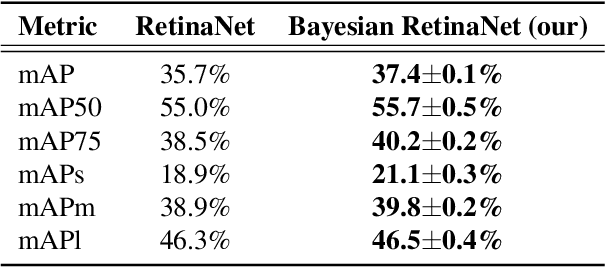
According to recent studies, commonly used computer vision datasets contain about 4% of label errors. For example, the COCO dataset is known for its high level of noise in data labels, which limits its use for training robust neural deep architectures in a real-world scenario. To model such a noise, in this paper we have proposed the homoscedastic aleatoric uncertainty estimation, and present a series of novel loss functions to address the problem of image object detection at scale. Specifically, the proposed functions are based on Bayesian inference and we have incorporated them into the common community-adopted object detection deep learning architecture RetinaNet. We have also shown that modeling of homoscedastic aleatoric uncertainty using our novel functions allows to increase the model interpretability and to improve the object detection performance being evaluated on the COCO dataset.
Two-Faced Humans on Twitter and Facebook: Harvesting Social Multimedia for Human Personality Profiling
Jun 20, 2021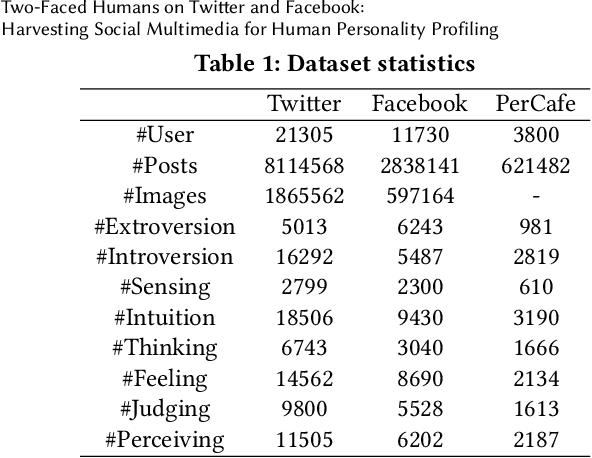

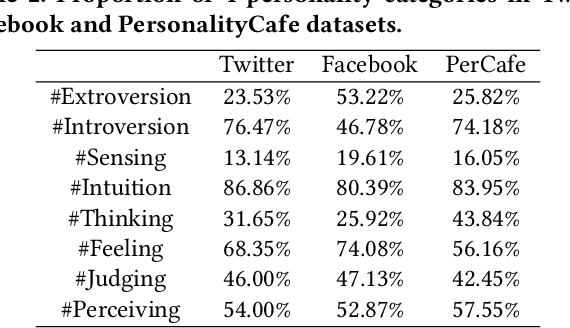
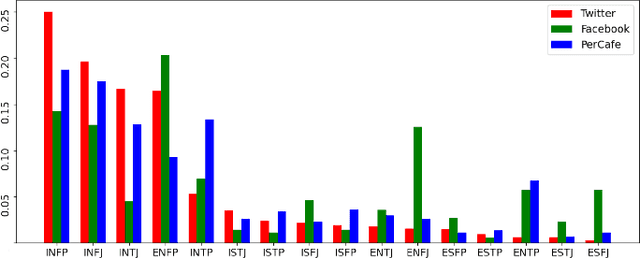
Human personality traits are the key drivers behind our decision-making, influencing our life path on a daily basis. Inference of personality traits, such as Myers-Briggs Personality Type, as well as an understanding of dependencies between personality traits and users' behavior on various social media platforms is of crucial importance to modern research and industry applications. The emergence of diverse and cross-purpose social media avenues makes it possible to perform user personality profiling automatically and efficiently based on data represented across multiple data modalities. However, the research efforts on personality profiling from multi-source multi-modal social media data are relatively sparse, and the level of impact of different social network data on machine learning performance has yet to be comprehensively evaluated. Furthermore, there is not such dataset in the research community to benchmark. This study is one of the first attempts towards bridging such an important research gap. Specifically, in this work, we infer the Myers-Briggs Personality Type indicators, by applying a novel multi-view fusion framework, called "PERS" and comparing the performance results not just across data modalities but also with respect to different social network data sources. Our experimental results demonstrate the PERS's ability to learn from multi-view data for personality profiling by efficiently leveraging on the significantly different data arriving from diverse social multimedia sources. We have also found that the selection of a machine learning approach is of crucial importance when choosing social network data sources and that people tend to reveal multiple facets of their personality in different social media avenues. Our released social multimedia dataset facilitates future research on this direction.
Solving Continuous Control with Episodic Memory
Jun 16, 2021

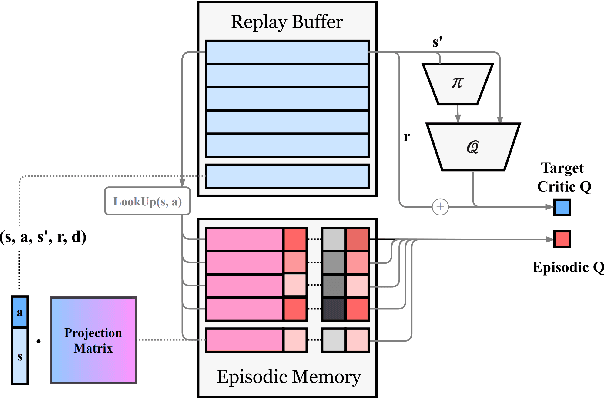
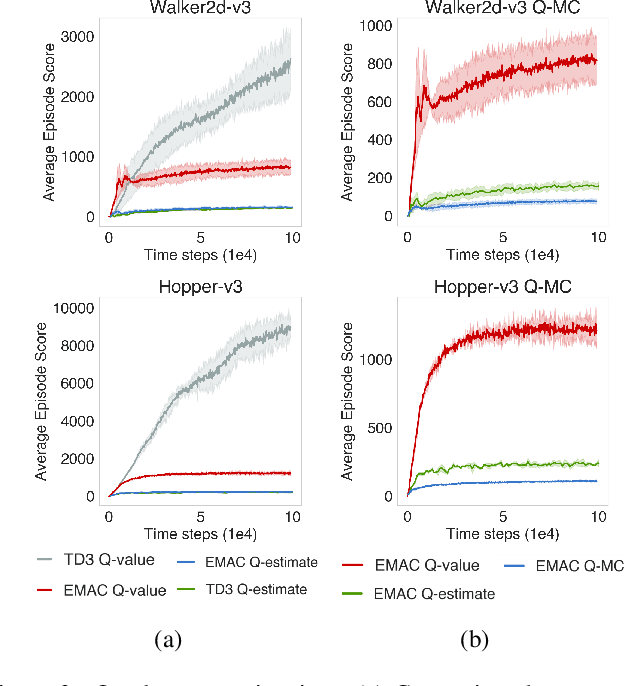
Episodic memory lets reinforcement learning algorithms remember and exploit promising experience from the past to improve agent performance. Previous works on memory mechanisms show benefits of using episodic-based data structures for discrete action problems in terms of sample-efficiency. The application of episodic memory for continuous control with a large action space is not trivial. Our study aims to answer the question: can episodic memory be used to improve agent's performance in continuous control? Our proposed algorithm combines episodic memory with Actor-Critic architecture by modifying critic's objective. We further improve performance by introducing episodic-based replay buffer prioritization. We evaluate our algorithm on OpenAI gym domains and show greater sample-efficiency compared with the state-of-the art model-free off-policy algorithms.