 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Exploration in Reinforcement Learning via Monte Carlo Critic Optimization
Jun 25, 2022



The class of deep deterministic off-policy algorithms is effectively applied to solve challenging continuous control problems. However, current approaches use random noise as a common exploration method that has several weaknesses, such as a need for manual adjusting on a given task and the absence of exploratory calibration during the training process. We address these challenges by proposing a novel guided exploration method that uses a differential directional controller to incorporate scalable exploratory action correction. An ensemble of Monte Carlo Critics that provides exploratory direction is presented as a controller. The proposed method improves the traditional exploration scheme by changing exploration dynamically. We then present a novel algorithm exploiting the proposed directional controller for both policy and critic modification. The presented algorithm outperforms modern reinforcement learning algorithms across a variety of problems from DMControl suite.
Solving Continuous Control with Episodic Memory
Jun 16, 2021

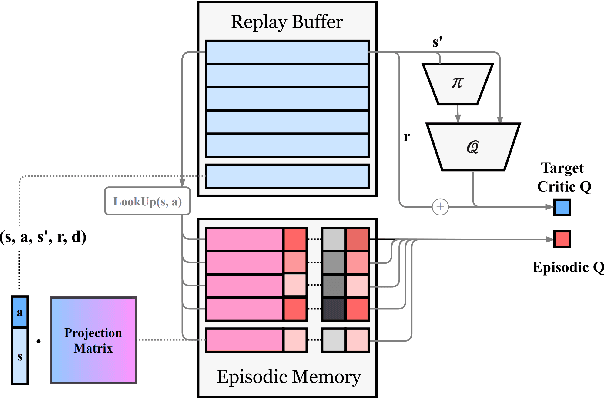
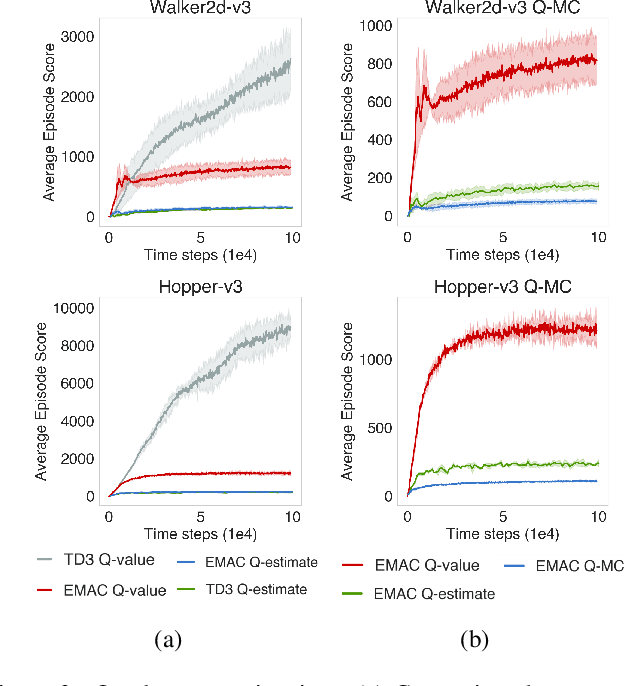
Episodic memory lets reinforcement learning algorithms remember and exploit promising experience from the past to improve agent performance. Previous works on memory mechanisms show benefits of using episodic-based data structures for discrete action problems in terms of sample-efficiency. The application of episodic memory for continuous control with a large action space is not trivial. Our study aims to answer the question: can episodic memory be used to improve agent's performance in continuous control? Our proposed algorithm combines episodic memory with Actor-Critic architecture by modifying critic's objective. We further improve performance by introducing episodic-based replay buffer prioritization. We evaluate our algorithm on OpenAI gym domains and show greater sample-efficiency compared with the state-of-the art model-free off-policy algorithms.
Jacobian Policy Optimizations
Jun 13, 2019
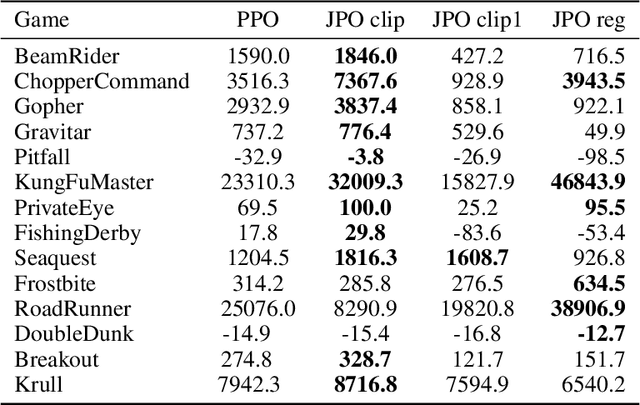
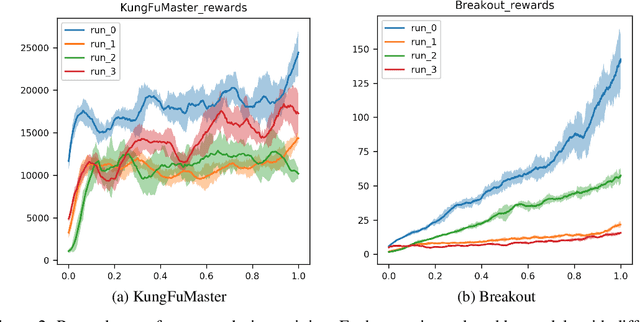
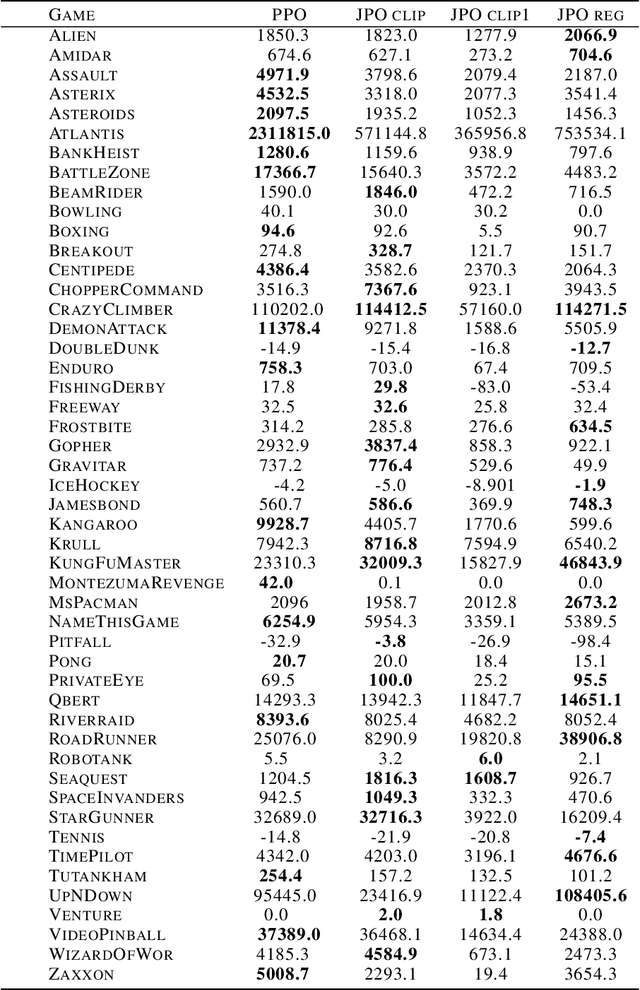
Recently, natural policy gradient algorithms gained widespread recognition due to their strong performance in reinforcement learning tasks. However, their major drawback is the need to secure the policy being in a ``trust region'' and meanwhile allowing for sufficient exploration. The main objective of this study was to present an approach which models dynamical isometry of agents policies by estimating conditioning of its Jacobian at individual points in the environment space. We present a Jacobian Policy Optimization algorithm for policy optimization, which dynamically adapts the trust interval with respect to policy conditioning. The suggested approach was tested across a range of Atari environments. This paper offers some important insights into an improvement of policy optimization in reinforcement learning tasks.
Linear Distillation Learning
Jun 13, 2019



Deep Linear Networks do not have expressive power but they are mathematically tractable. In our work, we found an architecture in which they are expressive. This paper presents a Linear Distillation Learning (LDL) a simple remedy to improve the performance of linear networks through distillation. In deep learning models, distillation often allows the smaller/shallow network to mimic the larger models in a much more accurate way, while a network of the same size trained on the one-hot targets can't achieve comparable results to the cumbersome model. In our method, we train students to distill teacher separately for each class in dataset. The most striking result to emerge from the data is that neural networks without activation functions can achieve high classification score on a small amount of data on MNIST and Omniglot datasets. Due to tractability, linear networks can be used to explain some phenomena observed experimentally in deep non-linear networks. The suggested approach could become a simple and practical instrument while further studies in the field of linear networks and distillation are yet to be undertaken.