 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrid Games: The Power of Multiple Grids for Quantizing Large Language Models
May 12, 2026A major recent advance in quantization is given by microscaled 4-bit formats such as NVFP4 and MXFP4, quantizing values into small groups sharing a scale, assuming a fixed floating-point grid. In this paper, we study the following natural extension: assume that, for each group of values, we are free to select the "better" among two or more 4-bit grids marked by one or more bits in the scale value. We formalize the power-of-two-grids (PO2) problem, and provide theoretical results showing that practical small-group formats such as MXFP or NVFP can benefit significantly from PO2 grids, while the advantage vanishes for very large groups. On the practical side, we instantiate several grid families, including 1) PO2(NF4), which pairs the standard NF4 normal grid with a learned grid, 2) MPO2, a grid pair that is fully learned over real weights and activations, 3) PO2(Split87), an explicit-zero asymmetric grid and 4) SFP4, a TensorCore-implementable triple which pairs NVFP4 with two shifted variants. Results for post-training quantization of standard open models and pre-training of Llama-like models show that adaptive grids consistently improve accuracy vs single-grid FP4 under both weight-only and weight+activation. Source code is available at https://github.com/IST-DASLab/GridGames.
AutoJudge: Judge Decoding Without Manual Annotation
Apr 28, 2025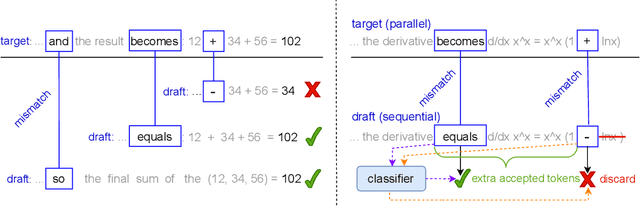

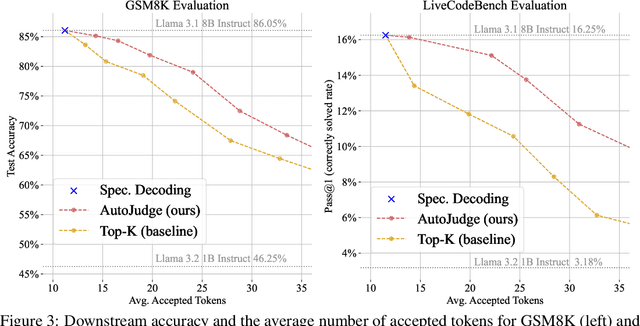
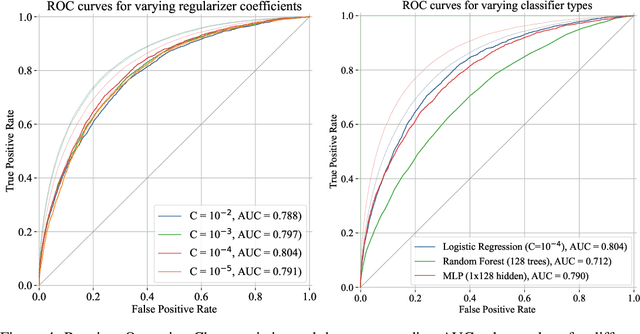
We introduce AutoJudge, a framework that accelerates large language model (LLM) inference with task-specific lossy speculative decoding. Instead of matching the original model output distribution token-by-token, we identify which of the generated tokens affect the downstream quality of the generated response, relaxing the guarantee so that the "unimportant" tokens can be generated faster. Our approach relies on a semi-greedy search algorithm to test which of the mismatches between target and draft model should be corrected to preserve quality, and which ones may be skipped. We then train a lightweight classifier based on existing LLM embeddings to predict, at inference time, which mismatching tokens can be safely accepted without compromising the final answer quality. We test our approach with Llama 3.2 1B (draft) and Llama 3.1 8B (target) models on zero-shot GSM8K reasoning, where it achieves up to 1.5x more accepted tokens per verification cycle with under 1% degradation in answer accuracy compared to standard speculative decoding and over 2x with small loss in accuracy. When applied to the LiveCodeBench benchmark, our approach automatically detects other, programming-specific important tokens and shows similar speedups, demonstrating its ability to generalize across tasks.
Hogwild! Inference: Parallel LLM Generation via Concurrent Attention
Apr 09, 2025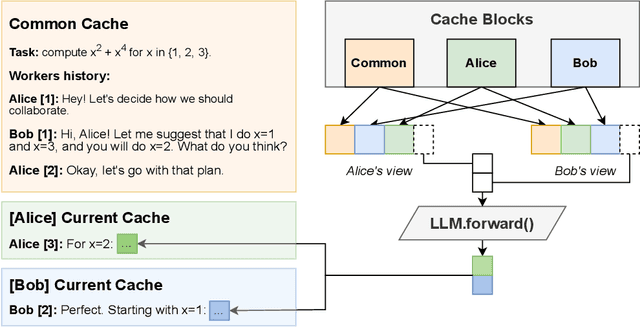
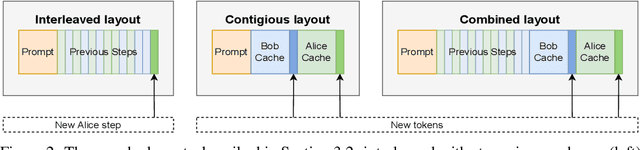
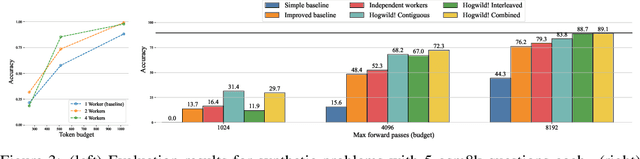
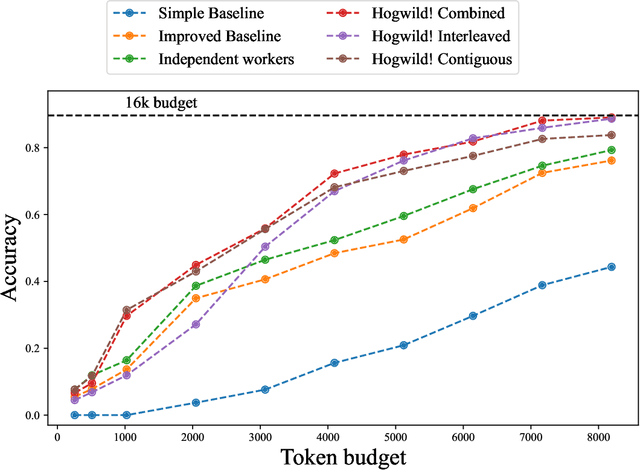
Large Language Models (LLMs) have demonstrated the ability to tackle increasingly complex tasks through advanced reasoning, long-form content generation, and tool use. Solving these tasks often involves long inference-time computations. In human problem solving, a common strategy to expedite work is collaboration: by dividing the problem into sub-tasks, exploring different strategies concurrently, etc. Recent research has shown that LLMs can also operate in parallel by implementing explicit cooperation frameworks, such as voting mechanisms or the explicit creation of independent sub-tasks that can be executed in parallel. However, each of these frameworks may not be suitable for all types of tasks, which can hinder their applicability. In this work, we propose a different design approach: we run LLM "workers" in parallel , allowing them to synchronize via a concurrently-updated attention cache and prompt these workers to decide how best to collaborate. Our approach allows the instances to come up with their own collaboration strategy for the problem at hand, all the while "seeing" each other's partial progress in the concurrent cache. We implement this approach via Hogwild! Inference: a parallel LLM inference engine where multiple instances of the same LLM run in parallel with the same attention cache, with "instant" access to each other's generated tokens. Hogwild! inference takes advantage of Rotary Position Embeddings (RoPE) to avoid recomputation while improving parallel hardware utilization. We find that modern reasoning-capable LLMs can perform inference with shared Key-Value cache out of the box, without additional fine-tuning.
Cache Me If You Must: Adaptive Key-Value Quantization for Large Language Models
Jan 31, 2025Efficient real-world deployments of large language models (LLMs) rely on Key-Value (KV) caching for processing and generating long outputs, reducing the need for repetitive computation. For large contexts, Key-Value caches can take up tens of gigabytes of device memory, as they store vector representations for each token and layer. Recent work has shown that the cached vectors can be compressed through quantization, pruning or merging, but these techniques often compromise quality towards higher compression rates. In this work, we aim to improve Key & Value compression by exploiting two observations: 1) the inherent dependencies between keys and values across different layers, and 2) high-compression mechanisms for internal network states. We propose AQUA-KV, an adaptive quantization for Key-Value caches that relies on compact adapters to exploit existing dependencies between Keys and Values, and aims to "optimally" compress the information that cannot be predicted. AQUA-KV significantly improves compression rates, while maintaining high accuracy on state-of-the-art LLM families. On Llama 3.2 LLMs, we achieve near-lossless inference at 2-2.5 bits per value with under $1\%$ relative error in perplexity and LongBench scores. AQUA-KV is one-shot, simple, and efficient: it can be calibrated on a single GPU within 1-6 hours, even for 70B models.
Rethinking Optimal Transport in Offline Reinforcement Learning
Oct 17, 2024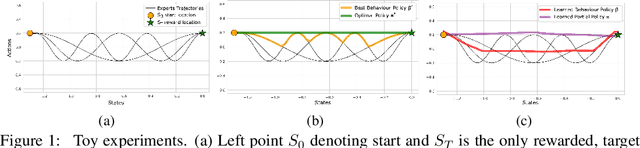
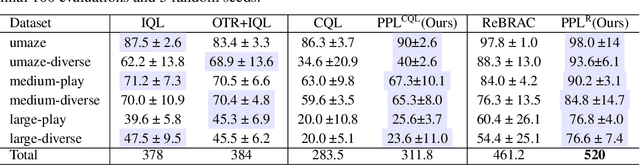
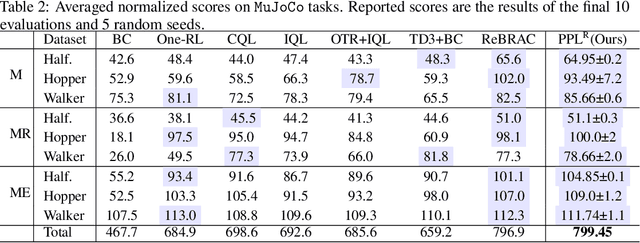
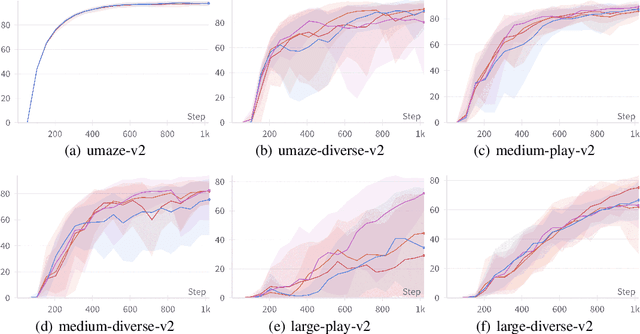
We propose a novel algorithm for offline reinforcement learning using optimal transport. Typically, in offline reinforcement learning, the data is provided by various experts and some of them can be sub-optimal. To extract an efficient policy, it is necessary to \emph{stitch} the best behaviors from the dataset. To address this problem, we rethink offline reinforcement learning as an optimal transportation problem. And based on this, we present an algorithm that aims to find a policy that maps states to a \emph{partial} distribution of the best expert actions for each given state. We evaluate the performance of our algorithm on continuous control problems from the D4RL suite and demonstrate improvements over existing methods.
Accurate Compression of Text-to-Image Diffusion Models via Vector Quantization
Aug 31, 2024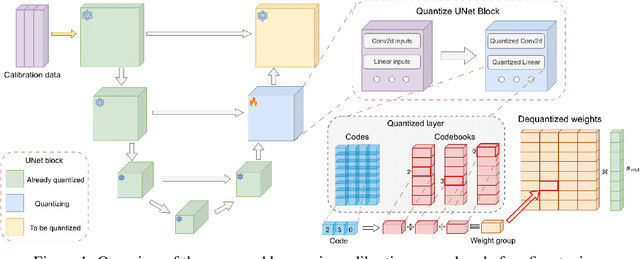
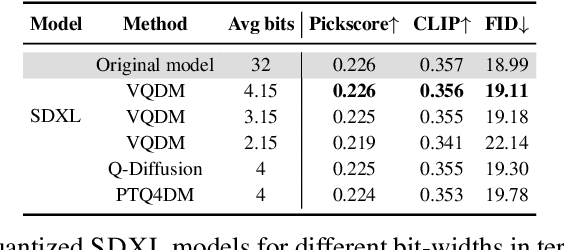


Text-to-image diffusion models have emerged as a powerful framework for high-quality image generation given textual prompts. Their success has driven the rapid development of production-grade diffusion models that consistently increase in size and already contain billions of parameters. As a result, state-of-the-art text-to-image models are becoming less accessible in practice, especially in resource-limited environments. Post-training quantization (PTQ) tackles this issue by compressing the pretrained model weights into lower-bit representations. Recent diffusion quantization techniques primarily rely on uniform scalar quantization, providing decent performance for the models compressed to 4 bits. This work demonstrates that more versatile vector quantization (VQ) may achieve higher compression rates for large-scale text-to-image diffusion models. Specifically, we tailor vector-based PTQ methods to recent billion-scale text-to-image models (SDXL and SDXL-Turbo), and show that the diffusion models of 2B+ parameters compressed to around 3 bits using VQ exhibit the similar image quality and textual alignment as previous 4-bit compression techniques.
Extreme Compression of Large Language Models via Additive Quantization
Jan 11, 2024



The emergence of accurate open large language models (LLMs) has led to a race towards quantization techniques for such models enabling execution on end-user devices. In this paper, we revisit the problem of "extreme" LLM compression--defined as targeting extremely low bit counts, such as 2 to 3 bits per parameter, from the point of view of classic methods in Multi-Codebook Quantization (MCQ). Our work builds on top of Additive Quantization, a classic algorithm from the MCQ family, and adapts it to the quantization of language models. The resulting algorithm advances the state-of-the-art in LLM compression, outperforming all recently-proposed techniques in terms of accuracy at a given compression budget. For instance, when compressing Llama 2 models to 2 bits per parameter, our algorithm quantizes the 7B model to 6.93 perplexity (a 1.29 improvement relative to the best prior work, and 1.81 points from FP16), the 13B model to 5.70 perplexity (a .36 improvement) and the 70B model to 3.94 perplexity (a .22 improvement) on WikiText2. We release our implementation of Additive Quantization for Language Models AQLM as a baseline to facilitate future research in LLM quantization.
SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression
Jun 05, 2023

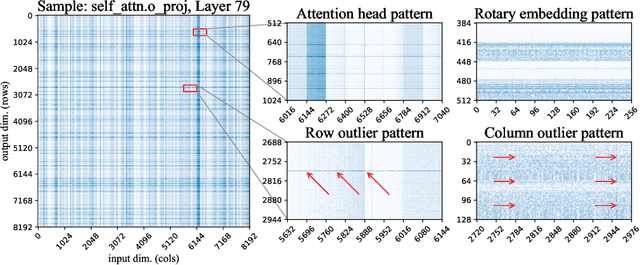

Recent advances in large language model (LLM) pretraining have led to high-quality LLMs with impressive abilities. By compressing such LLMs via quantization to 3-4 bits per parameter, they can fit into memory-limited devices such as laptops and mobile phones, enabling personalized use. However, quantization down to 3-4 bits per parameter usually leads to moderate-to-high accuracy losses, especially for smaller models in the 1-10B parameter range, which are well-suited for edge deployments. To address this accuracy issue, we introduce the Sparse-Quantized Representation (SpQR), a new compressed format and quantization technique which enables for the first time near-lossless compression of LLMs across model scales, while reaching similar compression levels to previous methods. SpQR works by identifying and isolating outlier weights, which cause particularly-large quantization errors, and storing them in higher precision, while compressing all other weights to 3-4 bits, and achieves relative accuracy losses of less than 1% in perplexity for highly-accurate LLaMA and Falcon LLMs. This makes it possible to run 33B parameter LLM on a single 24 GB consumer GPU without any performance degradation at 15% speedup thus making powerful LLMs available to consumer without any downsides. SpQR comes with efficient algorithms for both encoding weights into its format, as well as decoding them efficiently at runtime. Specifically, we provide an efficient GPU inference algorithm for SpQR which yields faster inference than 16-bit baselines at similar accuracy, while enabling memory compression gains of more than 4x.
Neural Optimal Transport with General Cost Functionals
May 30, 2022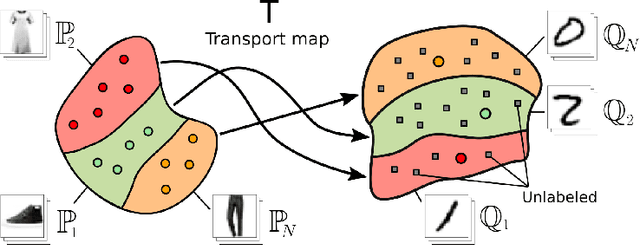
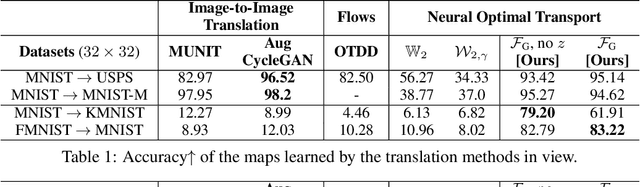
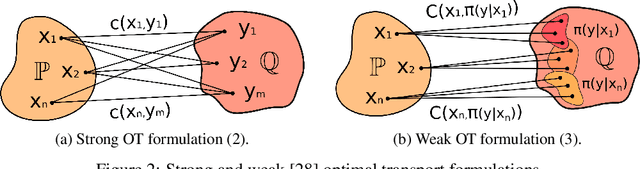
We present a novel neural-networks-based algorithm to compute optimal transport (OT) plans and maps for general cost functionals. The algorithm is based on a saddle point reformulation of the OT problem and generalizes prior OT methods for weak and strong cost functionals. As an application, we construct a functional to map data distributions with preserving the class-wise structure of data.
Wasserstein Iterative Networks for Barycenter Estimation
Jan 28, 2022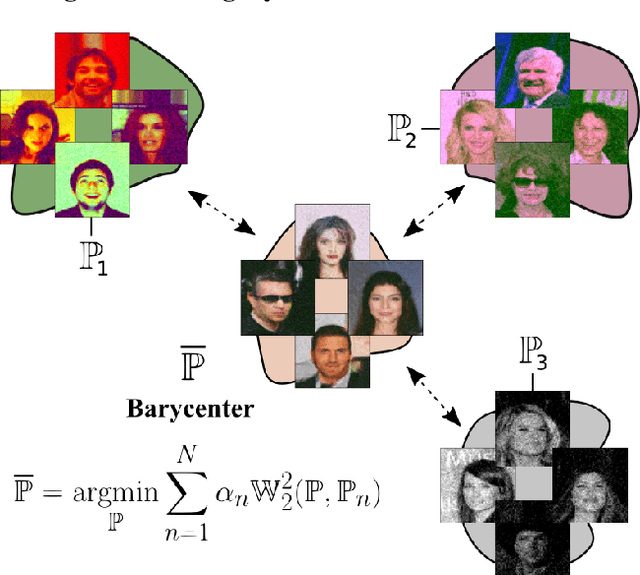

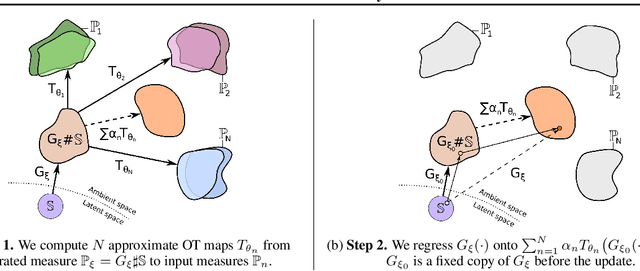

Wasserstein barycenters have become popular due to their ability to represent the average of probability measures in a geometrically meaningful way. In this paper, we present an algorithm to approximate the Wasserstein-2 barycenters of continuous measures via a generative model. Previous approaches rely on regularization (entropic/quadratic) which introduces bias or on input convex neural networks which are not expressive enough for large-scale tasks. In contrast, our algorithm does not introduce bias and allows using arbitrary neural networks. In addition, based on the celebrity faces dataset, we construct Ave, celeba! dataset which can be used for quantitative evaluation of barycenter algorithms by using standard metrics of generative models such as FID.