 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHogwild! Inference: Parallel LLM Generation via Concurrent Attention
Apr 09, 2025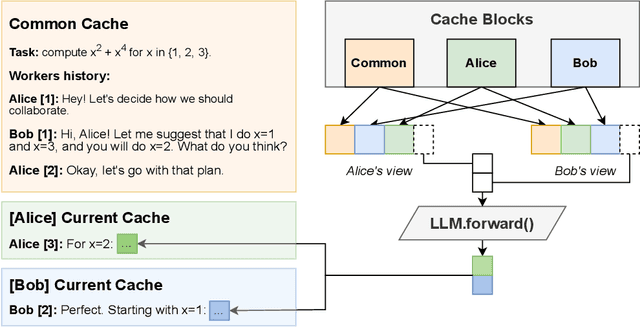
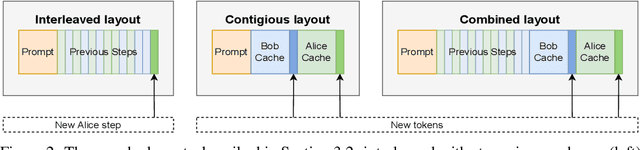
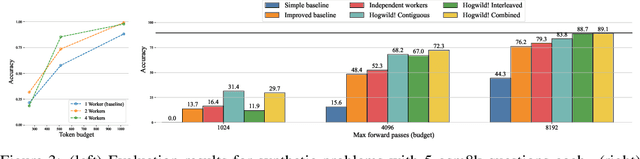
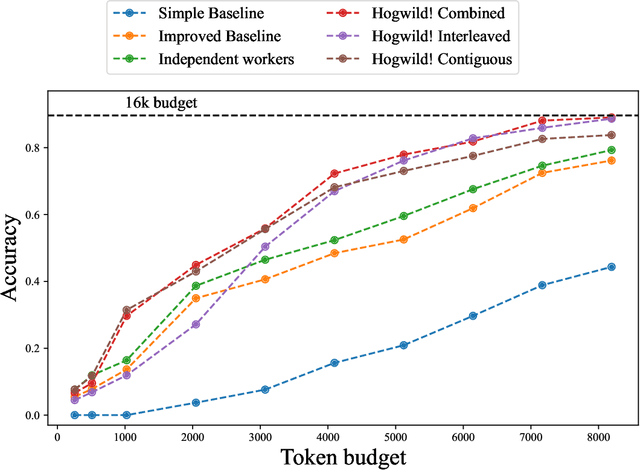
Large Language Models (LLMs) have demonstrated the ability to tackle increasingly complex tasks through advanced reasoning, long-form content generation, and tool use. Solving these tasks often involves long inference-time computations. In human problem solving, a common strategy to expedite work is collaboration: by dividing the problem into sub-tasks, exploring different strategies concurrently, etc. Recent research has shown that LLMs can also operate in parallel by implementing explicit cooperation frameworks, such as voting mechanisms or the explicit creation of independent sub-tasks that can be executed in parallel. However, each of these frameworks may not be suitable for all types of tasks, which can hinder their applicability. In this work, we propose a different design approach: we run LLM "workers" in parallel , allowing them to synchronize via a concurrently-updated attention cache and prompt these workers to decide how best to collaborate. Our approach allows the instances to come up with their own collaboration strategy for the problem at hand, all the while "seeing" each other's partial progress in the concurrent cache. We implement this approach via Hogwild! Inference: a parallel LLM inference engine where multiple instances of the same LLM run in parallel with the same attention cache, with "instant" access to each other's generated tokens. Hogwild! inference takes advantage of Rotary Position Embeddings (RoPE) to avoid recomputation while improving parallel hardware utilization. We find that modern reasoning-capable LLMs can perform inference with shared Key-Value cache out of the box, without additional fine-tuning.
Discrete Neural Algorithmic Reasoning
Feb 18, 2024

Neural algorithmic reasoning aims to capture computations with neural networks via learning the models to imitate the execution of classical algorithms. While common architectures are expressive enough to contain the correct model in the weights space, current neural reasoners are struggling to generalize well on out-of-distribution data. On the other hand, classical computations are not affected by distribution shifts as they can be described as transitions between discrete computational states. In this work, we propose to force neural reasoners to maintain the execution trajectory as a combination of finite predefined states. Trained with supervision on the algorithm's state transitions, such models are able to perfectly align with the original algorithm. To show this, we evaluate our approach on the SALSA-CLRS benchmark, where we get perfect test scores for all tasks. Moreover, the proposed architectural choice allows us to prove the correctness of the learned algorithms for any test data.
Neural Algorithmic Reasoning Without Intermediate Supervision
Jun 23, 2023Neural Algorithmic Reasoning is an emerging area of machine learning focusing on building models which can imitate the execution of classic algorithms, such as sorting, shortest paths, etc. One of the main challenges is to learn algorithms that are able to generalize to out-of-distribution data, in particular with significantly larger input sizes. Recent work on this problem has demonstrated the advantages of learning algorithms step-by-step, giving models access to all intermediate steps of the original algorithm. In this work, we instead focus on learning neural algorithmic reasoning only from the input-output pairs without appealing to the intermediate supervision. We propose simple but effective architectural improvements and also build a self-supervised objective that can regularise intermediate computations of the model without access to the algorithm trajectory. We demonstrate that our approach is competitive to its trajectory-supervised counterpart on tasks from the CLRS Algorithmic Reasoning Benchmark and achieves new state-of-the-art results for several problems, including sorting, where we obtain significant improvements. Thus, learning without intermediate supervision is a promising direction for further research on neural reasoners.