 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous Reasoning: Training-Free Interactive Thinking LLMs
Dec 11, 2025Many state-of-the-art LLMs are trained to think before giving their answer. Reasoning can greatly improve language model capabilities and safety, but it also makes them less interactive: given a new input, a model must stop thinking before it can respond. Real-world use cases such as voice-based or embedded assistants require an LLM agent to respond and adapt to additional information in real time, which is incompatible with sequential interactions. In contrast, humans can listen, think, and act asynchronously: we begin thinking about the problem while reading it and continue thinking while formulating the answer. In this work, we augment LLMs capable of reasoning to operate in a similar way without additional training. Our method uses the properties of rotary embeddings to enable LLMs built for sequential interactions to simultaneously think, listen, and generate outputs. We evaluate our approach on math, commonsense, and safety reasoning and find that it can generate accurate thinking-augmented answers in real time, reducing time to first non-thinking token from minutes to <= 5s. and the overall real-time delays by 6-11x.
Hogwild! Inference: Parallel LLM Generation via Concurrent Attention
Apr 09, 2025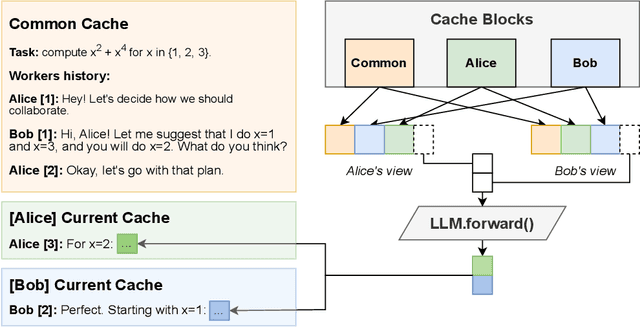
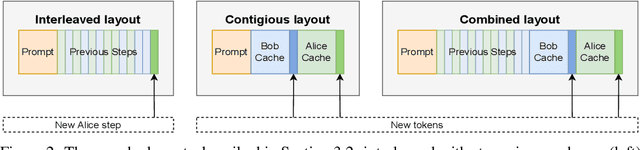
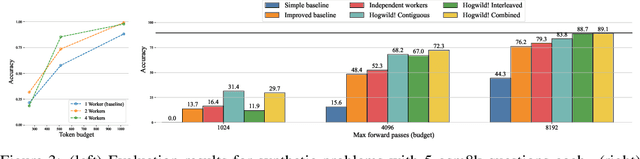
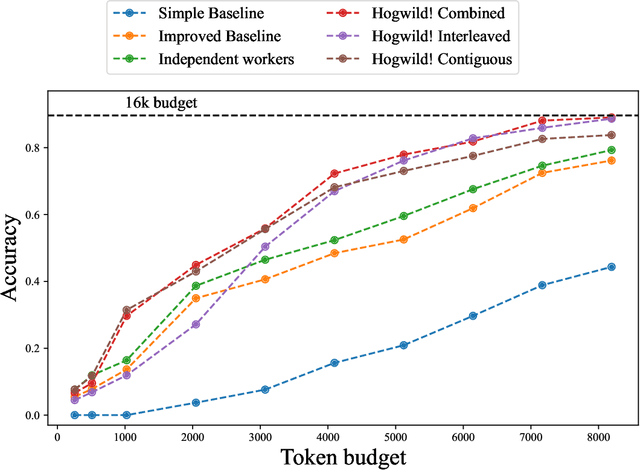
Large Language Models (LLMs) have demonstrated the ability to tackle increasingly complex tasks through advanced reasoning, long-form content generation, and tool use. Solving these tasks often involves long inference-time computations. In human problem solving, a common strategy to expedite work is collaboration: by dividing the problem into sub-tasks, exploring different strategies concurrently, etc. Recent research has shown that LLMs can also operate in parallel by implementing explicit cooperation frameworks, such as voting mechanisms or the explicit creation of independent sub-tasks that can be executed in parallel. However, each of these frameworks may not be suitable for all types of tasks, which can hinder their applicability. In this work, we propose a different design approach: we run LLM "workers" in parallel , allowing them to synchronize via a concurrently-updated attention cache and prompt these workers to decide how best to collaborate. Our approach allows the instances to come up with their own collaboration strategy for the problem at hand, all the while "seeing" each other's partial progress in the concurrent cache. We implement this approach via Hogwild! Inference: a parallel LLM inference engine where multiple instances of the same LLM run in parallel with the same attention cache, with "instant" access to each other's generated tokens. Hogwild! inference takes advantage of Rotary Position Embeddings (RoPE) to avoid recomputation while improving parallel hardware utilization. We find that modern reasoning-capable LLMs can perform inference with shared Key-Value cache out of the box, without additional fine-tuning.
Cache Me If You Must: Adaptive Key-Value Quantization for Large Language Models
Jan 31, 2025Efficient real-world deployments of large language models (LLMs) rely on Key-Value (KV) caching for processing and generating long outputs, reducing the need for repetitive computation. For large contexts, Key-Value caches can take up tens of gigabytes of device memory, as they store vector representations for each token and layer. Recent work has shown that the cached vectors can be compressed through quantization, pruning or merging, but these techniques often compromise quality towards higher compression rates. In this work, we aim to improve Key & Value compression by exploiting two observations: 1) the inherent dependencies between keys and values across different layers, and 2) high-compression mechanisms for internal network states. We propose AQUA-KV, an adaptive quantization for Key-Value caches that relies on compact adapters to exploit existing dependencies between Keys and Values, and aims to "optimally" compress the information that cannot be predicted. AQUA-KV significantly improves compression rates, while maintaining high accuracy on state-of-the-art LLM families. On Llama 3.2 LLMs, we achieve near-lossless inference at 2-2.5 bits per value with under $1\%$ relative error in perplexity and LongBench scores. AQUA-KV is one-shot, simple, and efficient: it can be calibrated on a single GPU within 1-6 hours, even for 70B models.