 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Compression of Text-to-Image Diffusion Models via Vector Quantization
Aug 31, 2024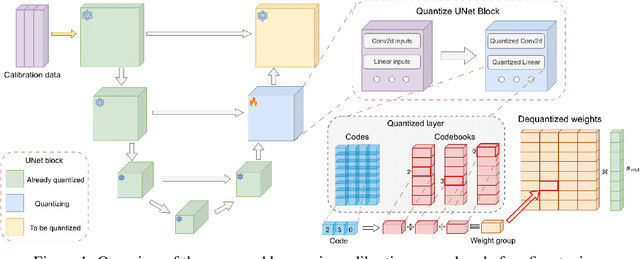
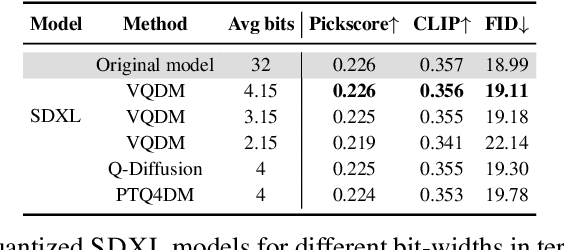


Text-to-image diffusion models have emerged as a powerful framework for high-quality image generation given textual prompts. Their success has driven the rapid development of production-grade diffusion models that consistently increase in size and already contain billions of parameters. As a result, state-of-the-art text-to-image models are becoming less accessible in practice, especially in resource-limited environments. Post-training quantization (PTQ) tackles this issue by compressing the pretrained model weights into lower-bit representations. Recent diffusion quantization techniques primarily rely on uniform scalar quantization, providing decent performance for the models compressed to 4 bits. This work demonstrates that more versatile vector quantization (VQ) may achieve higher compression rates for large-scale text-to-image diffusion models. Specifically, we tailor vector-based PTQ methods to recent billion-scale text-to-image models (SDXL and SDXL-Turbo), and show that the diffusion models of 2B+ parameters compressed to around 3 bits using VQ exhibit the similar image quality and textual alignment as previous 4-bit compression techniques.
Enabling High-Sparsity Foundational Llama Models with Efficient Pretraining and Deployment
May 06, 2024Large language models (LLMs) have revolutionized Natural Language Processing (NLP), but their size creates computational bottlenecks. We introduce a novel approach to create accurate, sparse foundational versions of performant LLMs that achieve full accuracy recovery for fine-tuning tasks at up to 70% sparsity. We achieve this for the LLaMA-2 7B model by combining the SparseGPT one-shot pruning method and sparse pretraining of those models on a subset of the SlimPajama dataset mixed with a Python subset of The Stack dataset. We exhibit training acceleration due to sparsity on Cerebras CS-3 chips that closely matches theoretical scaling. In addition, we establish inference acceleration of up to 3x on CPUs by utilizing Neural Magic's DeepSparse engine and 1.7x on GPUs through Neural Magic's nm-vllm engine. The above gains are realized via sparsity alone, thus enabling further gains through additional use of quantization. Specifically, we show a total speedup on CPUs for sparse-quantized LLaMA models of up to 8.6x. We demonstrate these results across diverse, challenging tasks, including chat, instruction following, code generation, arithmetic reasoning, and summarization to prove their generality. This work paves the way for rapidly creating smaller and faster LLMs without sacrificing accuracy.
Sparse Fine-tuning for Inference Acceleration of Large Language Models
Oct 13, 2023We consider the problem of accurate sparse fine-tuning of large language models (LLMs), that is, fine-tuning pretrained LLMs on specialized tasks, while inducing sparsity in their weights. On the accuracy side, we observe that standard loss-based fine-tuning may fail to recover accuracy, especially at high sparsities. To address this, we perform a detailed study of distillation-type losses, determining an L2-based distillation approach we term SquareHead which enables accurate recovery even at higher sparsities, across all model types. On the practical efficiency side, we show that sparse LLMs can be executed with speedups by taking advantage of sparsity, for both CPU and GPU runtimes. While the standard approach is to leverage sparsity for computational reduction, we observe that in the case of memory-bound LLMs sparsity can also be leveraged for reducing memory bandwidth. We exhibit end-to-end results showing speedups due to sparsity, while recovering accuracy, on T5 (language translation), Whisper (speech translation), and open GPT-type (MPT for text generation). For MPT text generation, we show for the first time that sparse fine-tuning can reach 75% sparsity without accuracy drops, provide notable end-to-end speedups for both CPU and GPU inference, and highlight that sparsity is also compatible with quantization approaches. Models and software for reproducing our results are provided in Section 6.
The Optimal BERT Surgeon: Scalable and Accurate Second-Order Pruning for Large Language Models
Mar 14, 2022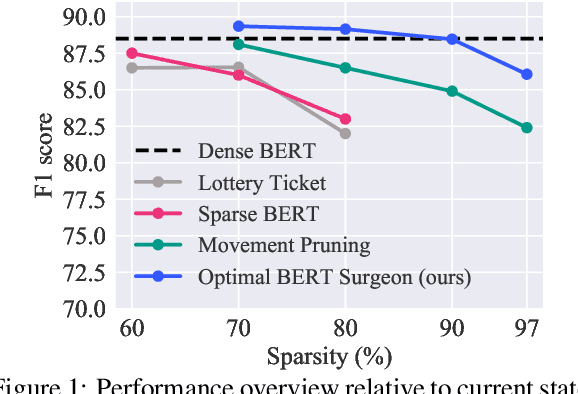
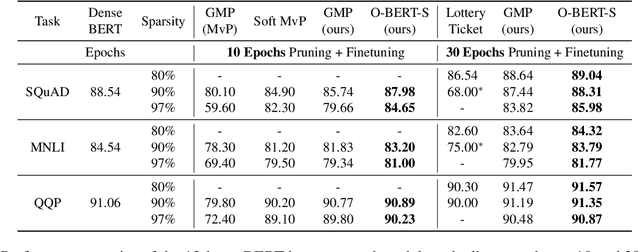

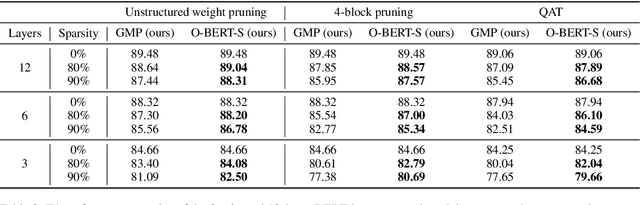
Pre-trained Transformer-based language models have become a key building block for natural language processing (NLP) tasks. While these models are extremely accurate, they can be too large and computationally intensive to run on standard deployments. A variety of compression methods, including distillation, quantization, structured and unstructured pruning are known to be applicable to decrease model size and increase inference speed. In this context, this paper's contributions are two-fold. We begin with an in-depth study of the accuracy-compression trade-off for unstructured weight pruning in the context of BERT models, and introduce Optimal BERT Surgeon (O-BERT-S), an efficient and accurate weight pruning method based on approximate second-order information, which we show to yield state-of-the-art results in terms of the compression/accuracy trade-off. Specifically, Optimal BERT Surgeon extends existing work on second-order pruning by allowing for pruning blocks of weights, and by being applicable at BERT scale. Second, we investigate the impact of this pruning method when compounding compression approaches for Transformer-based models, which allows us to combine state-of-the-art structured and unstructured pruning together with quantization, in order to obtain highly compressed, but accurate models. The resulting compression framework is powerful, yet general and efficient: we apply it to both the fine-tuning and pre-training stages of language tasks, to obtain state-of-the-art results on the accuracy-compression trade-off with relatively simple compression recipes. For example, we obtain 10x model size compression with < 1% relative drop in accuracy to the dense BERT-base, 10x end-to-end CPU-inference speedup with < 2% relative drop in accuracy, and 29x inference speedups with < 7.5% relative accuracy drop.