 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Give Me BF16 or Give Me Death"? Accuracy-Performance Trade-Offs in LLM Quantization
Nov 04, 2024



Despite the popularity of large language model (LLM) quantization for inference acceleration, significant uncertainty remains regarding the accuracy-performance trade-offs associated with various quantization formats. We present a comprehensive empirical study of quantized accuracy, evaluating popular quantization formats (FP8, INT8, INT4) across academic benchmarks and real-world tasks, on the entire Llama-3.1 model family. Additionally, our study examines the difference in text generated by quantized models versus their uncompressed counterparts. Beyond benchmarks, we also present a couple of quantization improvements which allowed us to obtain state-of-the-art accuracy recovery results. Our investigation, encompassing over 500,000 individual evaluations, yields several key findings: (1) FP8 weight and activation quantization (W8A8-FP) is lossless across all model scales, (2) INT8 weight and activation quantization (W8A8-INT), when properly tuned, incurs surprisingly low 1-3% accuracy degradation, and (3) INT4 weight-only quantization (W4A16-INT) is competitive with 8-bit integer weight and activation quantization. To address the question of the "best" format for a given deployment environment, we conduct inference performance analysis using the popular open-source vLLM framework on various GPU architectures. We find that W4A16 offers the best cost-efficiency for synchronous deployments, and for asynchronous deployment on mid-tier GPUs. At the same time, W8A8 formats excel in asynchronous "continuous batching" deployment of mid- and large-size models on high-end GPUs. Our results provide a set of practical guidelines for deploying quantized LLMs across scales and performance requirements.
Enabling High-Sparsity Foundational Llama Models with Efficient Pretraining and Deployment
May 06, 2024Large language models (LLMs) have revolutionized Natural Language Processing (NLP), but their size creates computational bottlenecks. We introduce a novel approach to create accurate, sparse foundational versions of performant LLMs that achieve full accuracy recovery for fine-tuning tasks at up to 70% sparsity. We achieve this for the LLaMA-2 7B model by combining the SparseGPT one-shot pruning method and sparse pretraining of those models on a subset of the SlimPajama dataset mixed with a Python subset of The Stack dataset. We exhibit training acceleration due to sparsity on Cerebras CS-3 chips that closely matches theoretical scaling. In addition, we establish inference acceleration of up to 3x on CPUs by utilizing Neural Magic's DeepSparse engine and 1.7x on GPUs through Neural Magic's nm-vllm engine. The above gains are realized via sparsity alone, thus enabling further gains through additional use of quantization. Specifically, we show a total speedup on CPUs for sparse-quantized LLaMA models of up to 8.6x. We demonstrate these results across diverse, challenging tasks, including chat, instruction following, code generation, arithmetic reasoning, and summarization to prove their generality. This work paves the way for rapidly creating smaller and faster LLMs without sacrificing accuracy.
oBERTa: Improving Sparse Transfer Learning via improved initialization, distillation, and pruning regimes
Apr 04, 2023



In this paper, we introduce the range of oBERTa language models, an easy-to-use set of language models which allows Natural Language Processing (NLP) practitioners to obtain between 3.8 and 24.3 times faster models without expertise in model compression. Specifically, oBERTa extends existing work on pruning, knowledge distillation, and quantization and leverages frozen embeddings improves distillation and model initialization to deliver higher accuracy on a broad range of transfer tasks. In generating oBERTa, we explore how the highly optimized RoBERTa differs from the BERT for pruning during pre-training and finetuning. We find it less amenable to compression during fine-tuning. We explore the use of oBERTa on seven representative NLP tasks and find that the improved compression techniques allow a pruned oBERTa model to match the performance of BERTbase and exceed the performance of Prune OFA Large on the SQUAD V1.1 Question Answering dataset, despite being 8x and 2x, respectively faster in inference. We release our code, training regimes, and associated model for broad usage to encourage usage and experimentation
Sparse*BERT: Sparse Models are Robust
May 25, 2022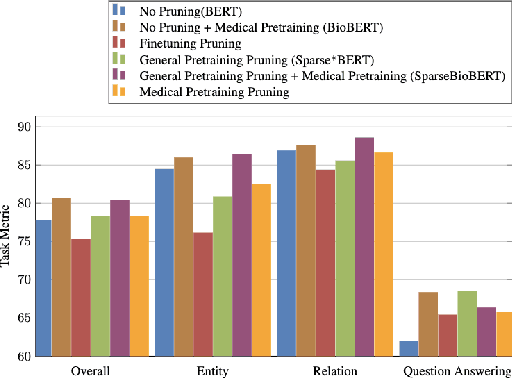
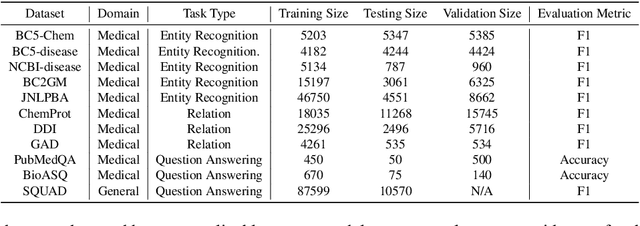
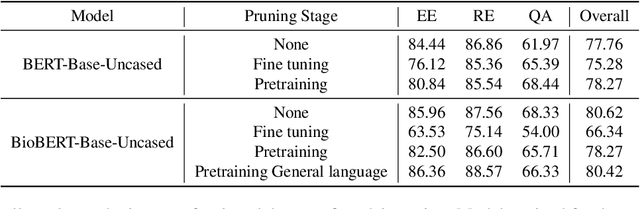
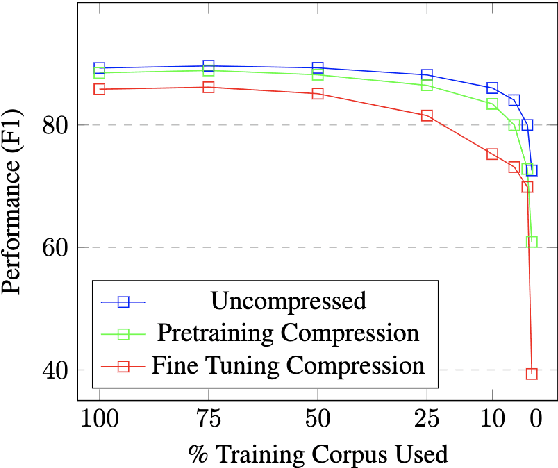
Large Language Models have become the core architecture upon which most modern natural language processing (NLP) systems build. These models can consistently deliver impressive accuracy and robustness across tasks and domains, but their high computational overhead can make inference difficult and expensive. To make the usage of these models less costly recent work has explored leveraging structured and unstructured pruning, quantization, and distillation as ways to improve inference speed and decrease size. This paper studies how models pruned using Gradual Unstructured Magnitude Pruning can transfer between domains and tasks. Our experimentation shows that models that are pruned during pretraining using general domain masked language models can transfer to novel domains and tasks without extensive hyperparameter exploration or specialized approaches. We demonstrate that our general sparse model Sparse*BERT can become SparseBioBERT simply by pretraining the compressed architecture on unstructured biomedical text. Moreover, we show that SparseBioBERT can match the quality of BioBERT with only 10\% of the parameters.