 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse*BERT: Sparse Models are Robust
Paper and Code
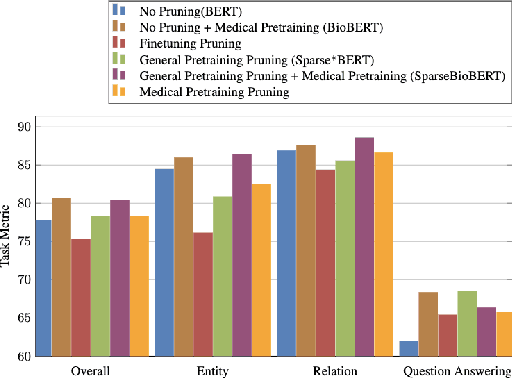
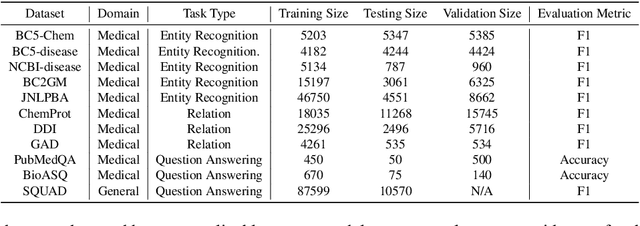
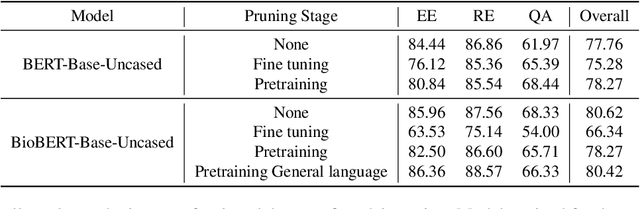
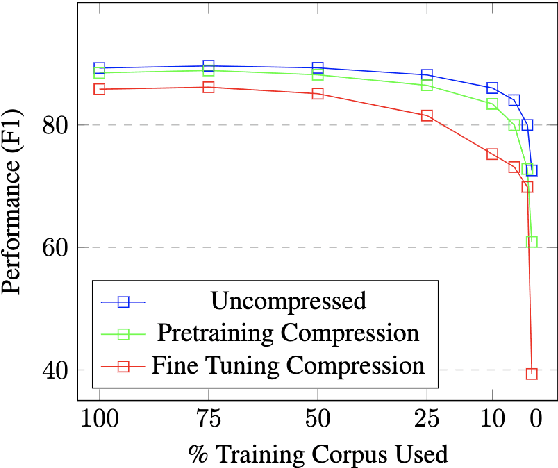
Large Language Models have become the core architecture upon which most modern natural language processing (NLP) systems build. These models can consistently deliver impressive accuracy and robustness across tasks and domains, but their high computational overhead can make inference difficult and expensive. To make the usage of these models less costly recent work has explored leveraging structured and unstructured pruning, quantization, and distillation as ways to improve inference speed and decrease size. This paper studies how models pruned using Gradual Unstructured Magnitude Pruning can transfer between domains and tasks. Our experimentation shows that models that are pruned during pretraining using general domain masked language models can transfer to novel domains and tasks without extensive hyperparameter exploration or specialized approaches. We demonstrate that our general sparse model Sparse*BERT can become SparseBioBERT simply by pretraining the compressed architecture on unstructured biomedical text. Moreover, we show that SparseBioBERT can match the quality of BioBERT with only 10\% of the parameters.