 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRePAST: Relative Pose Attention Scene Representation Transformer
Apr 10, 2023The Scene Representation Transformer (SRT) is a recent method to render novel views at interactive rates. Since SRT uses camera poses with respect to an arbitrarily chosen reference camera, it is not invariant to the order of the input views. As a result, SRT is not directly applicable to large-scale scenes where the reference frame would need to be changed regularly. In this work, we propose Relative Pose Attention SRT (RePAST): Instead of fixing a reference frame at the input, we inject pairwise relative camera pose information directly into the attention mechanism of the Transformers. This leads to a model that is by definition invariant to the choice of any global reference frame, while still retaining the full capabilities of the original method. Empirical results show that adding this invariance to the model does not lead to a loss in quality. We believe that this is a step towards applying fully latent transformer-based rendering methods to large-scale scenes.
Multi-NeuS: 3D Head Portraits from Single Image with Neural Implicit Functions
Sep 07, 2022
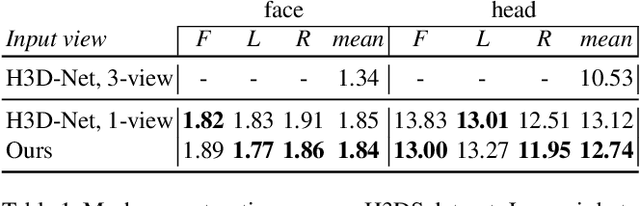
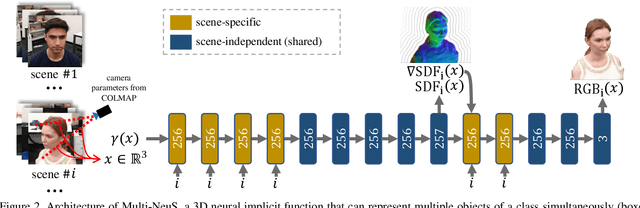

We present an approach for the reconstruction of textured 3D meshes of human heads from one or few views. Since such few-shot reconstruction is underconstrained, it requires prior knowledge which is hard to impose on traditional 3D reconstruction algorithms. In this work, we rely on the recently introduced 3D representation $\unicode{x2013}$ neural implicit functions $\unicode{x2013}$ which, being based on neural networks, allows to naturally learn priors about human heads from data, and is directly convertible to textured mesh. Namely, we extend NeuS, a state-of-the-art neural implicit function formulation, to represent multiple objects of a class (human heads in our case) simultaneously. The underlying neural net architecture is designed to learn the commonalities among these objects and to generalize to unseen ones. Our model is trained on just a hundred smartphone videos and does not require any scanned 3D data. Afterwards, the model can fit novel heads in the few-shot or one-shot modes with good results.
CycleGAN-Based Unpaired Speech Dereverberation
Mar 29, 2022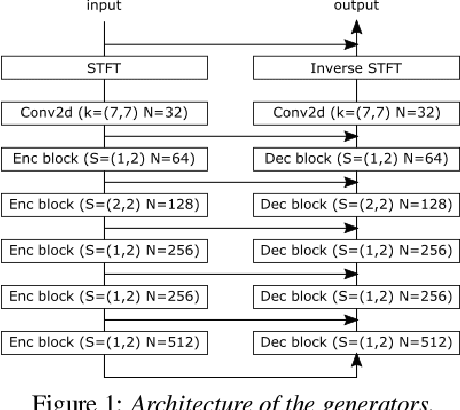

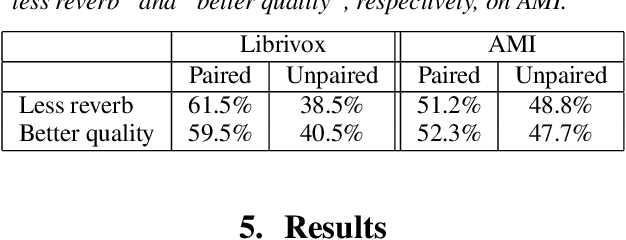
Typically, neural network-based speech dereverberation models are trained on paired data, composed of a dry utterance and its corresponding reverberant utterance. The main limitation of this approach is that such models can only be trained on large amounts of data and a variety of room impulse responses when the data is synthetically reverberated, since acquiring real paired data is costly. In this paper we propose a CycleGAN-based approach that enables dereverberation models to be trained on unpaired data. We quantify the impact of using unpaired data by comparing the proposed unpaired model to a paired model with the same architecture and trained on the paired version of the same dataset. We show that the performance of the unpaired model is comparable to the performance of the paired model on two different datasets, according to objective evaluation metrics. Furthermore, we run two subjective evaluations and show that both models achieve comparable subjective quality on the AMI dataset, which was not seen during training.
Multi-sensor large-scale dataset for multi-view 3D reconstruction
Mar 11, 2022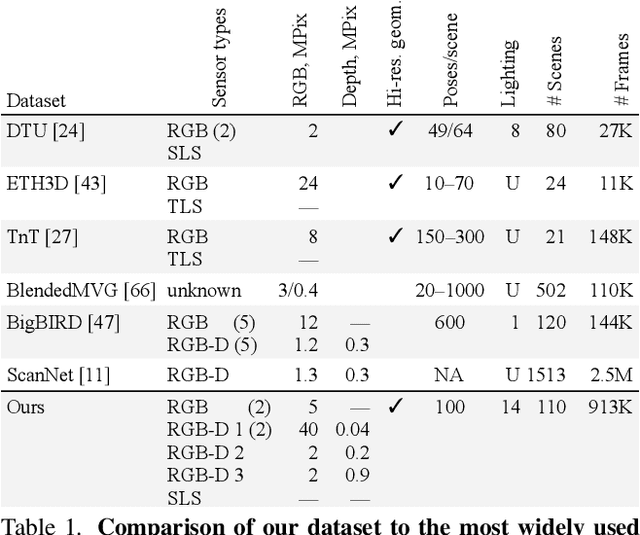
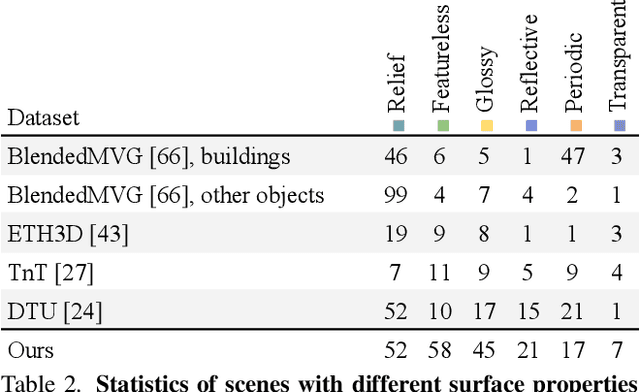

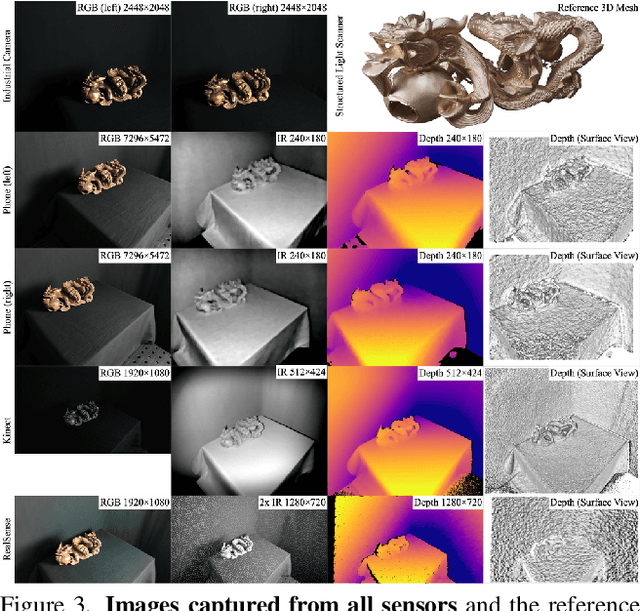
We present a new multi-sensor dataset for 3D surface reconstruction. It includes registered RGB and depth data from sensors of different resolutions and modalities: smartphones, Intel RealSense, Microsoft Kinect, industrial cameras, and structured-light scanner. The data for each scene is obtained under a large number of lighting conditions, and the scenes are selected to emphasize a diverse set of material properties challenging for existing algorithms. In the acquisition process, we aimed to maximize high-resolution depth data quality for challenging cases, to provide reliable ground truth for learning algorithms. Overall, we provide over 1.4 million images of 110 different scenes acquired at 14 lighting conditions from 100 viewing directions. We expect our dataset will be useful for evaluation and training of 3D reconstruction algorithms of different types and for other related tasks. Our dataset and accompanying software will be available online.
Towards Unpaired Depth Enhancement and Super-Resolution in the Wild
May 25, 2021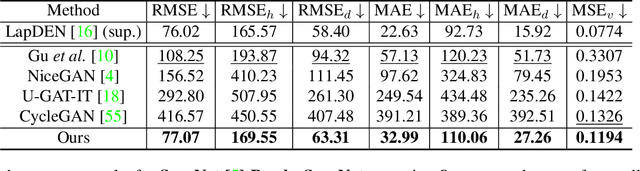
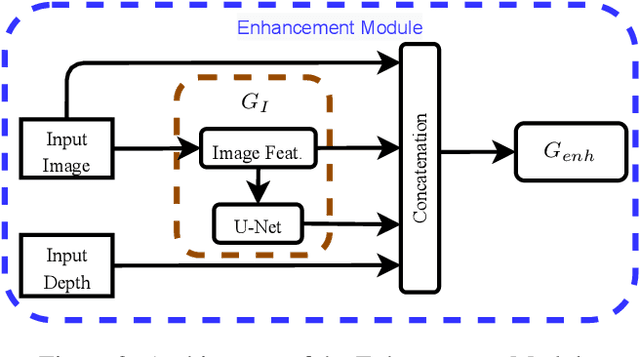
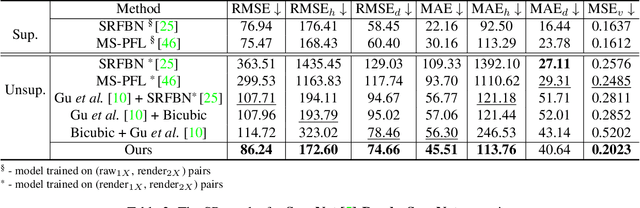
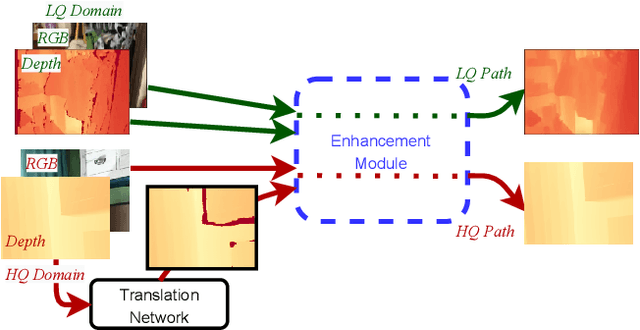
Depth maps captured with commodity sensors are often of low quality and resolution; these maps need to be enhanced to be used in many applications. State-of-the-art data-driven methods of depth map super-resolution rely on registered pairs of low- and high-resolution depth maps of the same scenes. Acquisition of real-world paired data requires specialized setups. Another alternative, generating low-resolution maps from high-resolution maps by subsampling, adding noise and other artificial degradation methods, does not fully capture the characteristics of real-world low-resolution images. As a consequence, supervised learning methods trained on such artificial paired data may not perform well on real-world low-resolution inputs. We consider an approach to depth map enhancement based on learning from unpaired data. While many techniques for unpaired image-to-image translation have been proposed, most are not directly applicable to depth maps. We propose an unpaired learning method for simultaneous depth enhancement and super-resolution, which is based on a learnable degradation model and surface normal estimates as features to produce more accurate depth maps. We demonstrate that our method outperforms existing unpaired methods and performs on par with paired methods on a new benchmark for unpaired learning that we developed.
How Good MVSNets Are at Depth Fusion
Nov 30, 2020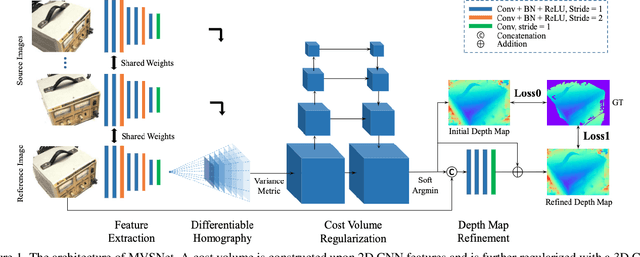
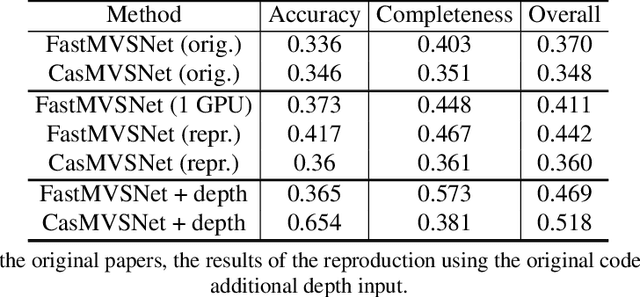
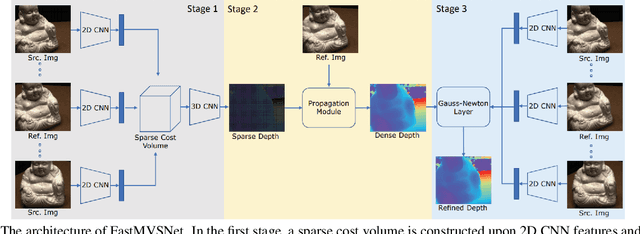
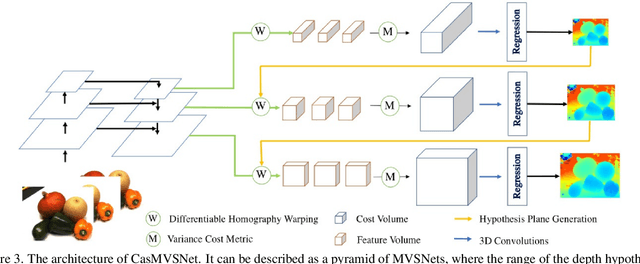
We study the effects of the additional input to deep multi-view stereo methods in the form of low-quality sensor depth. We modify two state-of-the-art deep multi-view stereo methods for using with the input depth. We show that the additional input depth may improve the quality of deep multi-view stereo.
Deep Vectorization of Technical Drawings
Mar 16, 2020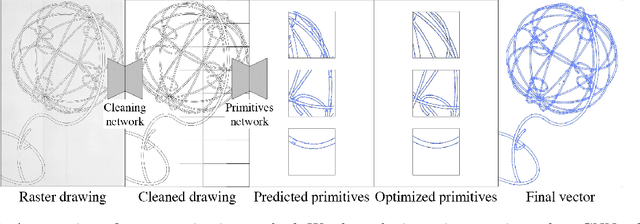
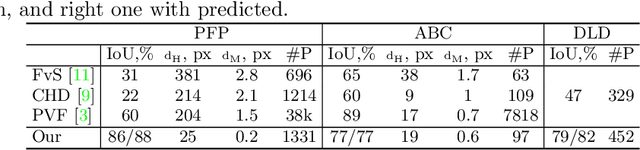
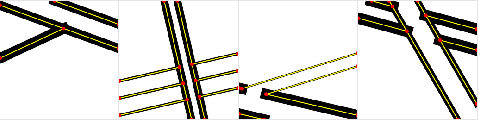
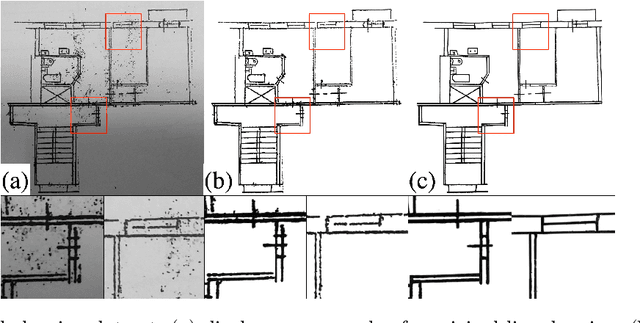
We present a new method for vectorization of technical line drawings, such as floor plans, architectural drawings, and 2D CAD images. Our method includes (1) a deep learning-based cleaning stage to eliminate the background and imperfections in the image and fill in missing parts, (2) a transformer-based network to estimate vector primitives, and (3) optimization procedure to obtain the final primitive configurations. We train the networks on synthetic data, renderings of vector line drawings, and manually vectorized scans of line drawings. Our method quantitatively and qualitatively outperforms a number of existing techniques on a collection of representative technical drawings.