 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycleGAN-Based Unpaired Speech Dereverberation
Paper and Code
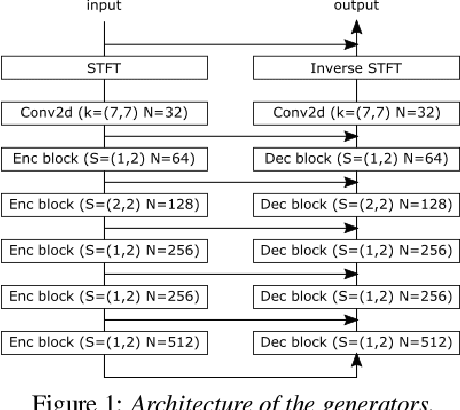

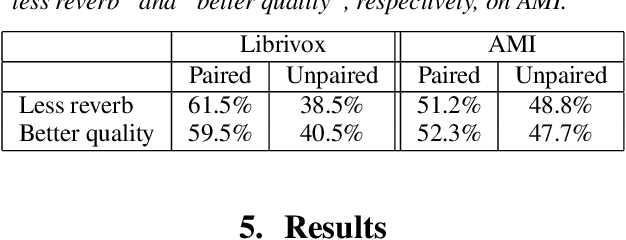
Typically, neural network-based speech dereverberation models are trained on paired data, composed of a dry utterance and its corresponding reverberant utterance. The main limitation of this approach is that such models can only be trained on large amounts of data and a variety of room impulse responses when the data is synthetically reverberated, since acquiring real paired data is costly. In this paper we propose a CycleGAN-based approach that enables dereverberation models to be trained on unpaired data. We quantify the impact of using unpaired data by comparing the proposed unpaired model to a paired model with the same architecture and trained on the paired version of the same dataset. We show that the performance of the unpaired model is comparable to the performance of the paired model on two different datasets, according to objective evaluation metrics. Furthermore, we run two subjective evaluations and show that both models achieve comparable subjective quality on the AMI dataset, which was not seen during training.