 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-3DGS: Removing Transient Objects for 3D Scene Reconstruction
Nov 29, 2024



We propose a novel framework to remove transient objects from input videos for 3D scene reconstruction using Gaussian Splatting. Our framework consists of the following steps. In the first step, we propose an unsupervised training strategy for a classification network to distinguish between transient objects and static scene parts based on their different training behavior inside the 3D Gaussian Splatting reconstruction. In the second step, we improve the boundary quality and stability of the detected transients by combining our results from the first step with an off-the-shelf segmentation method. We also propose a simple and effective strategy to track objects in the input video forward and backward in time. Our results show an improvement over the current state of the art in existing sparsely captured datasets and significant improvements in a newly proposed densely captured (video) dataset. More results and code are available at https://transient-3dgs.github.io.
GSplatLoc: Grounding Keypoint Descriptors into 3D Gaussian Splatting for Improved Visual Localization
Sep 24, 2024
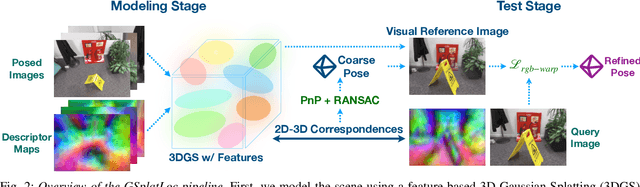

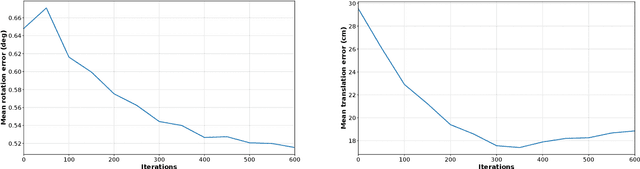
Although various visual localization approaches exist, such as scene coordinate and pose regression, these methods often struggle with high memory consumption or extensive optimization requirements. To address these challenges, we utilize recent advancements in novel view synthesis, particularly 3D Gaussian Splatting (3DGS), to enhance localization. 3DGS allows for the compact encoding of both 3D geometry and scene appearance with its spatial features. Our method leverages the dense description maps produced by XFeat's lightweight keypoint detection and description model. We propose distilling these dense keypoint descriptors into 3DGS to improve the model's spatial understanding, leading to more accurate camera pose predictions through 2D-3D correspondences. After estimating an initial pose, we refine it using a photometric warping loss. Benchmarking on popular indoor and outdoor datasets shows that our approach surpasses state-of-the-art Neural Render Pose (NRP) methods, including NeRFMatch and PNeRFLoc.
Multi-NeuS: 3D Head Portraits from Single Image with Neural Implicit Functions
Sep 07, 2022
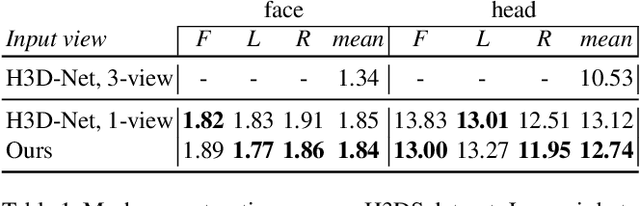
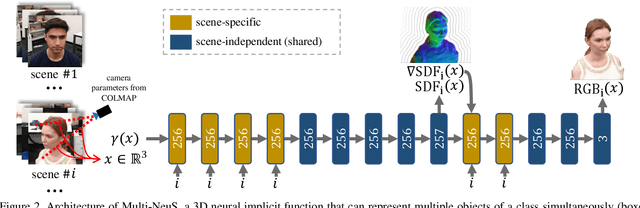

We present an approach for the reconstruction of textured 3D meshes of human heads from one or few views. Since such few-shot reconstruction is underconstrained, it requires prior knowledge which is hard to impose on traditional 3D reconstruction algorithms. In this work, we rely on the recently introduced 3D representation $\unicode{x2013}$ neural implicit functions $\unicode{x2013}$ which, being based on neural networks, allows to naturally learn priors about human heads from data, and is directly convertible to textured mesh. Namely, we extend NeuS, a state-of-the-art neural implicit function formulation, to represent multiple objects of a class (human heads in our case) simultaneously. The underlying neural net architecture is designed to learn the commonalities among these objects and to generalize to unseen ones. Our model is trained on just a hundred smartphone videos and does not require any scanned 3D data. Afterwards, the model can fit novel heads in the few-shot or one-shot modes with good results.
NPBG++: Accelerating Neural Point-Based Graphics
Mar 24, 2022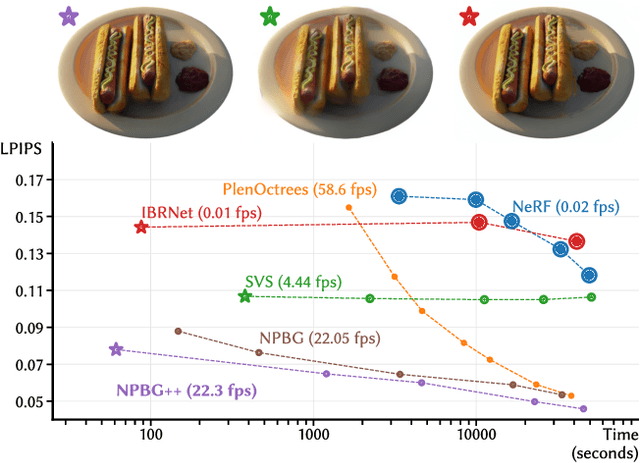
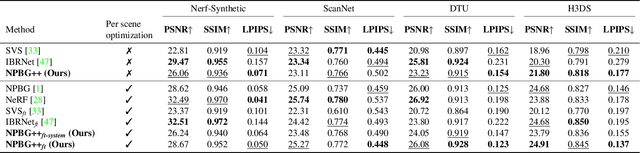
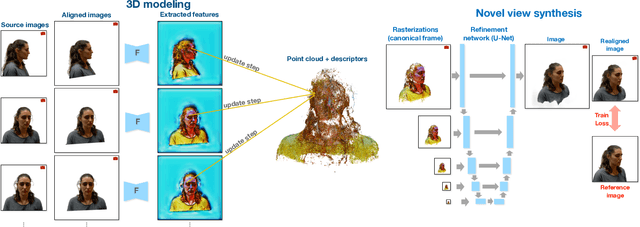
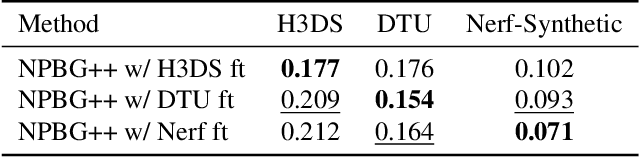
We present a new system (NPBG++) for the novel view synthesis (NVS) task that achieves high rendering realism with low scene fitting time. Our method efficiently leverages the multiview observations and the point cloud of a static scene to predict a neural descriptor for each point, improving upon the pipeline of Neural Point-Based Graphics in several important ways. By predicting the descriptors with a single pass through the source images, we lift the requirement of per-scene optimization while also making the neural descriptors view-dependent and more suitable for scenes with strong non-Lambertian effects. In our comparisons, the proposed system outperforms previous NVS approaches in terms of fitting and rendering runtimes while producing images of similar quality.
Multi-sensor large-scale dataset for multi-view 3D reconstruction
Mar 11, 2022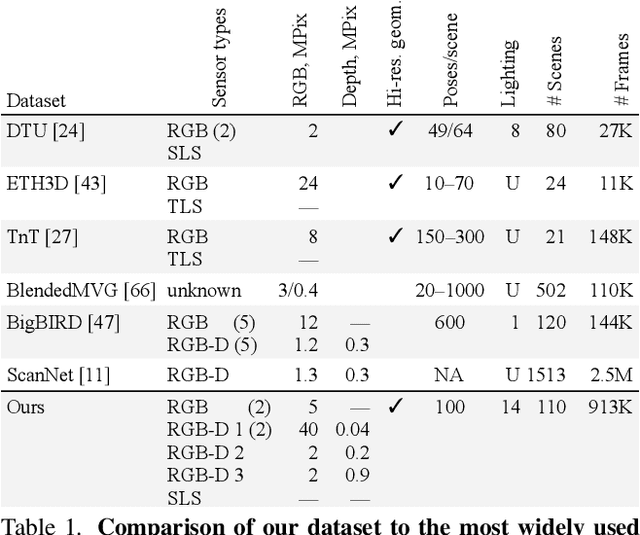
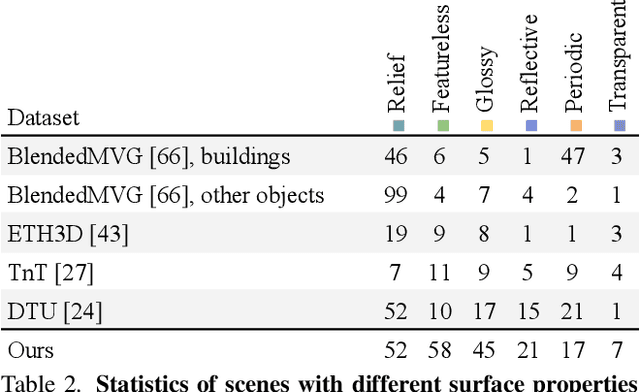

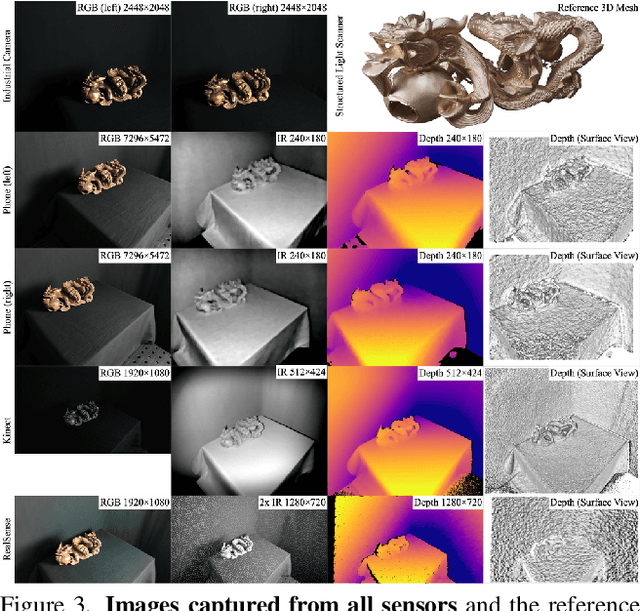
We present a new multi-sensor dataset for 3D surface reconstruction. It includes registered RGB and depth data from sensors of different resolutions and modalities: smartphones, Intel RealSense, Microsoft Kinect, industrial cameras, and structured-light scanner. The data for each scene is obtained under a large number of lighting conditions, and the scenes are selected to emphasize a diverse set of material properties challenging for existing algorithms. In the acquisition process, we aimed to maximize high-resolution depth data quality for challenging cases, to provide reliable ground truth for learning algorithms. Overall, we provide over 1.4 million images of 110 different scenes acquired at 14 lighting conditions from 100 viewing directions. We expect our dataset will be useful for evaluation and training of 3D reconstruction algorithms of different types and for other related tasks. Our dataset and accompanying software will be available online.
DEF: Deep Estimation of Sharp Geometric Features in 3D Shapes
Nov 30, 2020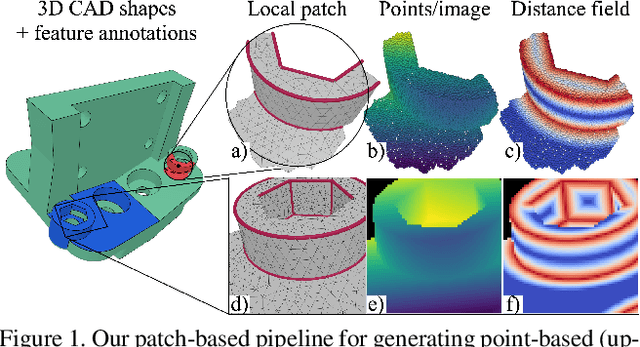
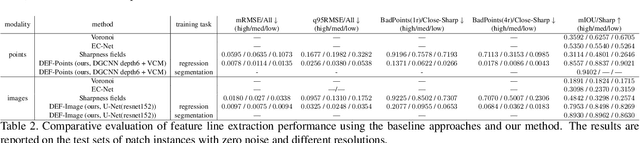
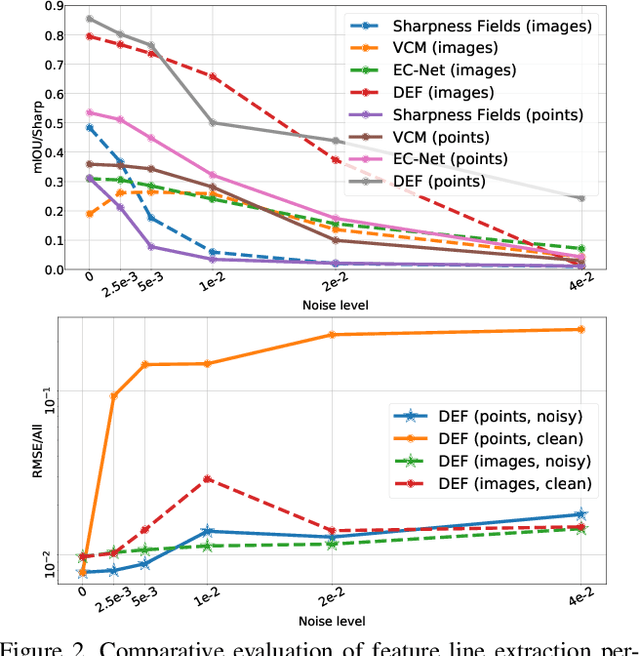
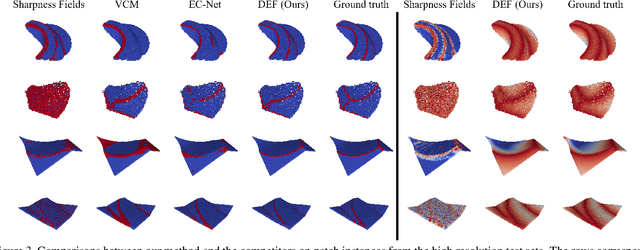
Sharp feature lines carry essential information about human-made objects, enabling compact 3D shape representations, high-quality surface reconstruction, and are a signal source for mesh processing. While extracting high-quality lines from noisy and undersampled data is challenging for traditional methods, deep learning-powered algorithms can leverage global and semantic information from the training data to aid in the process. We propose Deep Estimators of Features (DEFs), a learning-based framework for predicting sharp geometric features in sampled 3D shapes. Differently from existing data-driven methods, which reduce this problem to feature classification, we propose to regress a scalar field representing the distance from point samples to the closest feature line on local patches. By fusing the result of individual patches, we can process large 3D models, which are impossible to process for existing data-driven methods due to their size and complexity. Extensive experimental evaluation of DEFs is implemented on synthetic and real-world 3D shape datasets and suggests advantages of our image- and point-based estimators over competitor methods, as well as improved noise robustness and scalability of our approach.
Making DensePose fast and light
Jul 09, 2020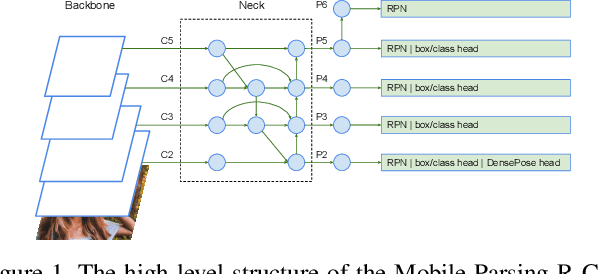
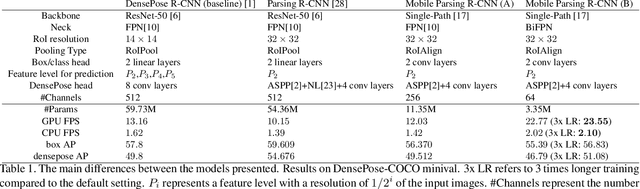
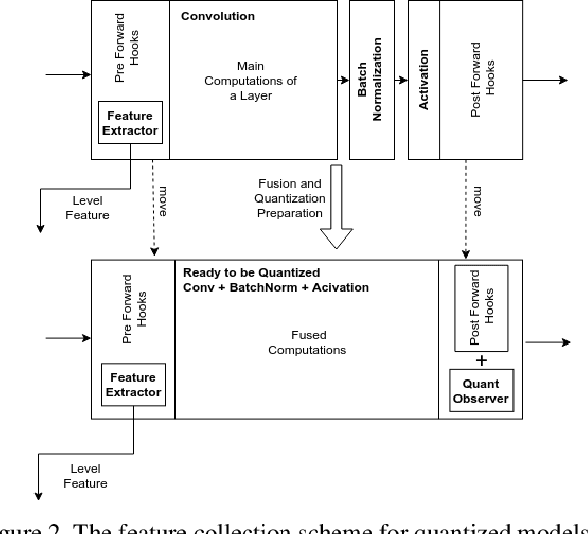
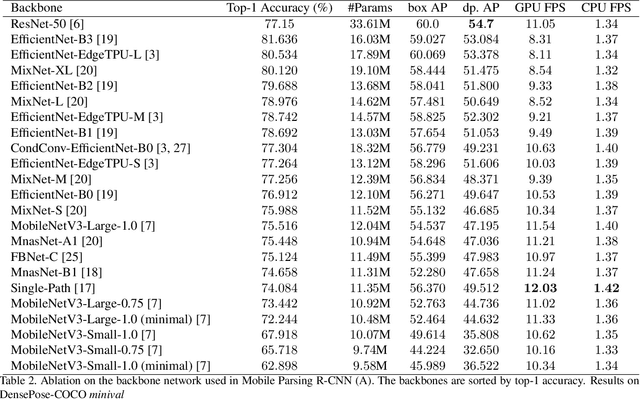
DensePose estimation task is a significant step forward for enhancing user experience computer vision applications ranging from augmented reality to cloth fitting. Existing neural network models capable of solving this task are heavily parameterized and a long way from being transferred to an embedded or mobile device. To enable Dense Pose inference on the end device with current models, one needs to support an expensive server-side infrastructure and have a stable internet connection. To make things worse, mobile and embedded devices do not always have a powerful GPU inside. In this work, we target the problem of redesigning the DensePose R-CNN model's architecture so that the final network retains most of its accuracy but becomes more light-weight and fast. To achieve that, we tested and incorporated many deep learning innovations from recent years, specifically performing an ablation study on 23 efficient backbone architectures, multiple two-stage detection pipeline modifications, and custom model quantization methods. As a result, we achieved $17\times$ model size reduction and $2\times$ latency improvement compared to the baseline model.
Latent Video Transformer
Jun 18, 2020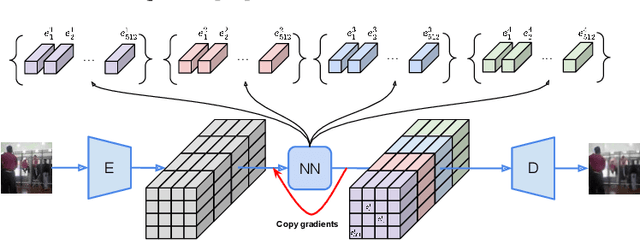
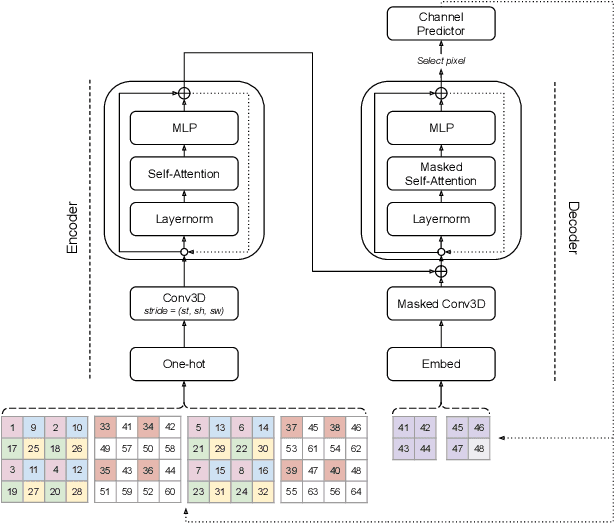


The video generation task can be formulated as a prediction of future video frames given some past frames. Recent generative models for videos face the problem of high computational requirements. Some models require up to 512 Tensor Processing Units for parallel training. In this work, we address this problem via modeling the dynamics in a latent space. After the transformation of frames into the latent space, our model predicts latent representation for the next frames in an autoregressive manner. We demonstrate the performance of our approach on BAIR Robot Pushing and Kinetics-600 datasets. The approach tends to reduce requirements to 8 Graphical Processing Units for training the models while maintaining comparable generation quality.