 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-NeuS: 3D Head Portraits from Single Image with Neural Implicit Functions
Sep 07, 2022
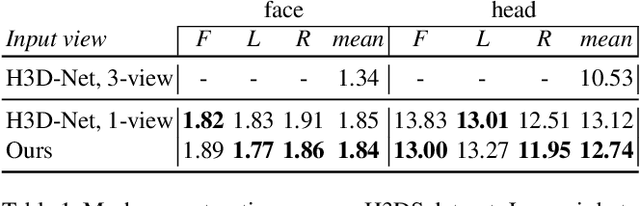
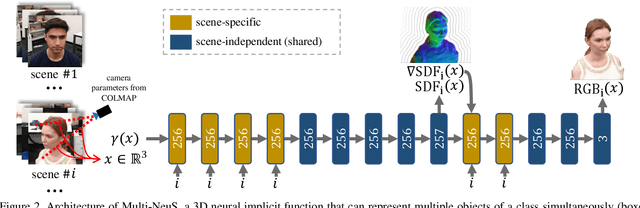

We present an approach for the reconstruction of textured 3D meshes of human heads from one or few views. Since such few-shot reconstruction is underconstrained, it requires prior knowledge which is hard to impose on traditional 3D reconstruction algorithms. In this work, we rely on the recently introduced 3D representation $\unicode{x2013}$ neural implicit functions $\unicode{x2013}$ which, being based on neural networks, allows to naturally learn priors about human heads from data, and is directly convertible to textured mesh. Namely, we extend NeuS, a state-of-the-art neural implicit function formulation, to represent multiple objects of a class (human heads in our case) simultaneously. The underlying neural net architecture is designed to learn the commonalities among these objects and to generalize to unseen ones. Our model is trained on just a hundred smartphone videos and does not require any scanned 3D data. Afterwards, the model can fit novel heads in the few-shot or one-shot modes with good results.
Neural Head Reenactment with Latent Pose Descriptors
Apr 24, 2020
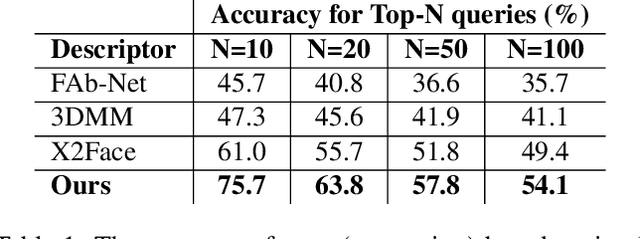
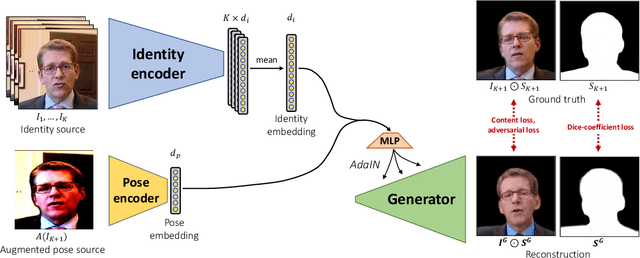

We propose a neural head reenactment system, which is driven by a latent pose representation and is capable of predicting the foreground segmentation alongside the RGB image. The latent pose representation is learned as a part of the entire reenactment system, and the learning process is based solely on image reconstruction losses. We show that despite its simplicity, with a large and diverse enough training dataset, such learning successfully decomposes pose from identity. The resulting system can then reproduce mimics of the driving person and, furthermore, can perform cross-person reenactment. Additionally, we show that the learned descriptors are useful for other pose-related tasks, such as keypoint prediction and pose-based retrieval.
Textured Neural Avatars
May 21, 2019
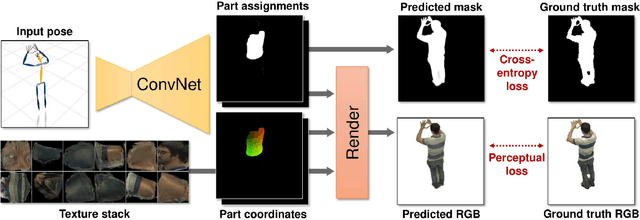


We present a system for learning full-body neural avatars, i.e. deep networks that produce full-body renderings of a person for varying body pose and camera position. Our system takes the middle path between the classical graphics pipeline and the recent deep learning approaches that generate images of humans using image-to-image translation. In particular, our system estimates an explicit two-dimensional texture map of the model surface. At the same time, it abstains from explicit shape modeling in 3D. Instead, at test time, the system uses a fully-convolutional network to directly map the configuration of body feature points w.r.t. the camera to the 2D texture coordinates of individual pixels in the image frame. We show that such a system is capable of learning to generate realistic renderings while being trained on videos annotated with 3D poses and foreground masks. We also demonstrate that maintaining an explicit texture representation helps our system to achieve better generalization compared to systems that use direct image-to-image translation.
Few-Shot Adversarial Learning of Realistic Neural Talking Head Models
May 20, 2019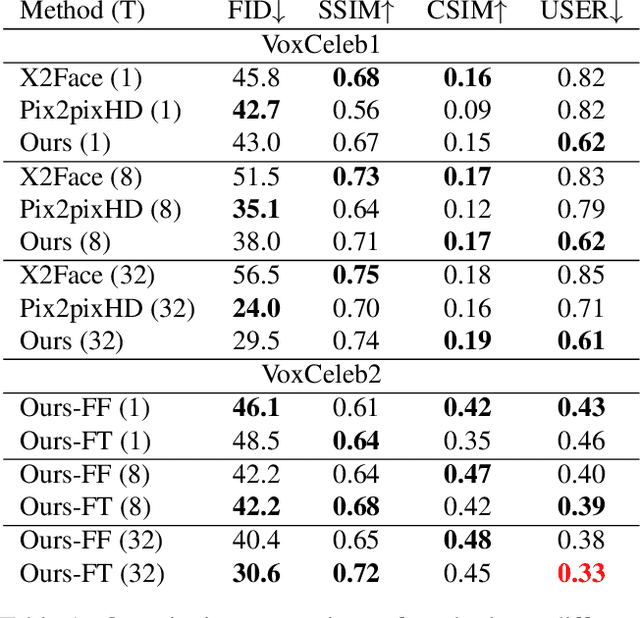
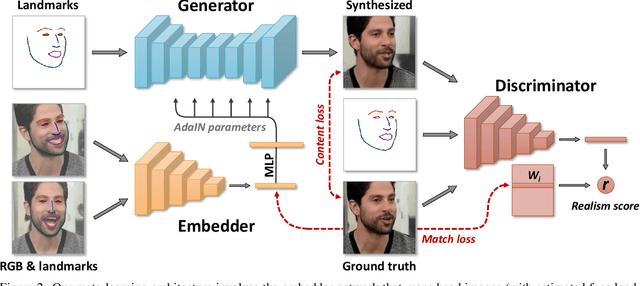
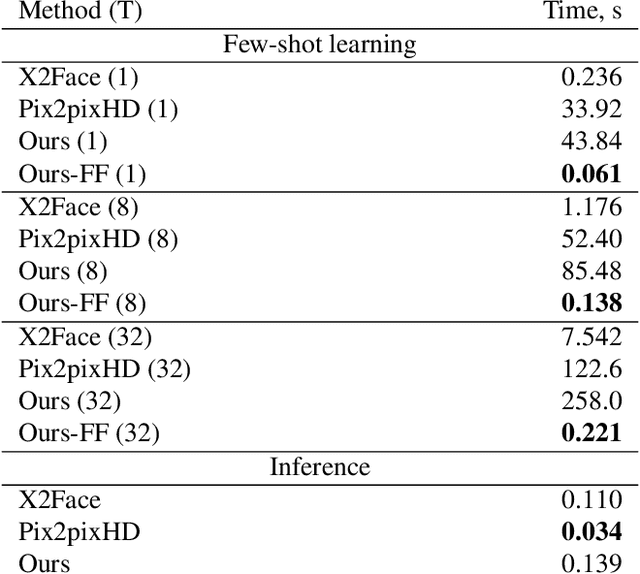

Several recent works have shown how highly realistic human head images can be obtained by training convolutional neural networks to generate them. In order to create a personalized talking head model, these works require training on a large dataset of images of a single person. However, in many practical scenarios, such personalized talking head models need to be learned from a few image views of a person, potentially even a single image. Here, we present a system with such few-shot capability. It performs lengthy meta-learning on a large dataset of videos, and after that is able to frame few- and one-shot learning of neural talking head models of previously unseen people as adversarial training problems with high capacity generators and discriminators. Crucially, the system is able to initialize the parameters of both the generator and the discriminator in a person-specific way, so that training can be based on just a few images and done quickly, despite the need to tune tens of millions of parameters. We show that such an approach is able to learn highly realistic and personalized talking head models of new people and even portrait paintings.
Learnable Triangulation of Human Pose
May 14, 2019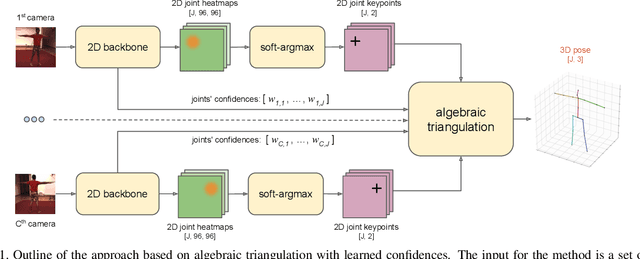
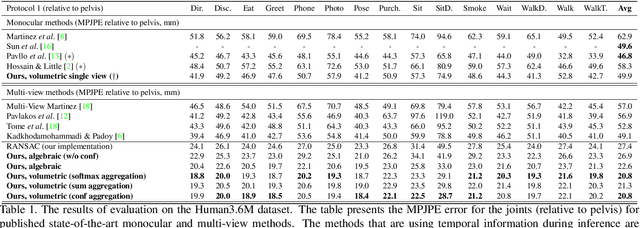
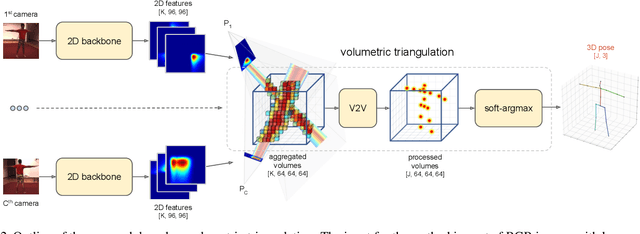

We present two novel solutions for multi-view 3D human pose estimation based on new learnable triangulation methods that combine 3D information from multiple 2D views. The first (baseline) solution is a basic differentiable algebraic triangulation with an addition of confidence weights estimated from the input images. The second solution is based on a novel method of volumetric aggregation from intermediate 2D backbone feature maps. The aggregated volume is then refined via 3D convolutions that produce final 3D joint heatmaps and allow modelling a human pose prior. Crucially, both approaches are end-to-end differentiable, which allows us to directly optimize the target metric. We demonstrate transferability of the solutions across datasets and considerably improve the multi-view state of the art on the Human3.6M dataset. Video demonstration, annotations and additional materials will be posted on our project page (https://saic-violet.github.io/learnable-triangulation).