Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Video Transformer
Paper and Code
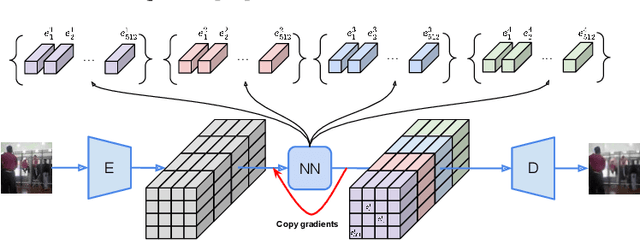
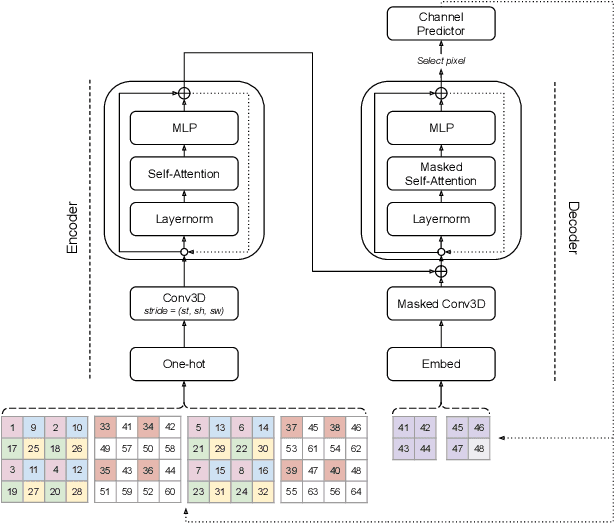


The video generation task can be formulated as a prediction of future video frames given some past frames. Recent generative models for videos face the problem of high computational requirements. Some models require up to 512 Tensor Processing Units for parallel training. In this work, we address this problem via modeling the dynamics in a latent space. After the transformation of frames into the latent space, our model predicts latent representation for the next frames in an autoregressive manner. We demonstrate the performance of our approach on BAIR Robot Pushing and Kinetics-600 datasets. The approach tends to reduce requirements to 8 Graphical Processing Units for training the models while maintaining comparable generation quality.
View paper on