 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Video Transformer
Jun 18, 2020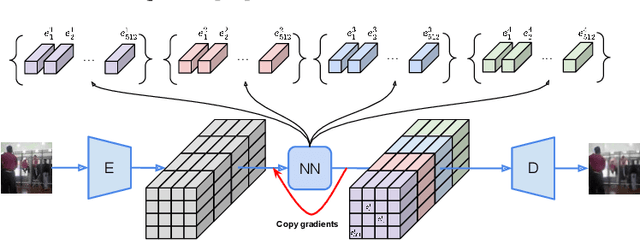
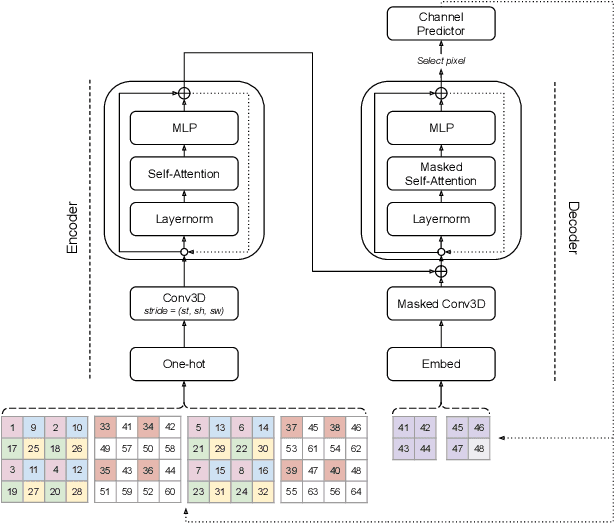


The video generation task can be formulated as a prediction of future video frames given some past frames. Recent generative models for videos face the problem of high computational requirements. Some models require up to 512 Tensor Processing Units for parallel training. In this work, we address this problem via modeling the dynamics in a latent space. After the transformation of frames into the latent space, our model predicts latent representation for the next frames in an autoregressive manner. We demonstrate the performance of our approach on BAIR Robot Pushing and Kinetics-600 datasets. The approach tends to reduce requirements to 8 Graphical Processing Units for training the models while maintaining comparable generation quality.
Deep Vectorization of Technical Drawings
Mar 16, 2020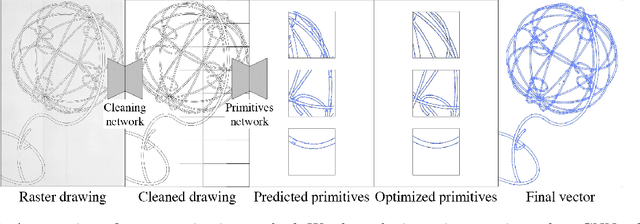
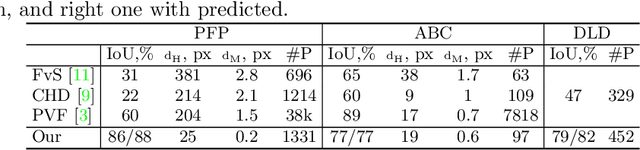
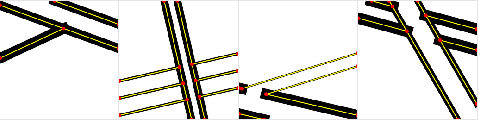
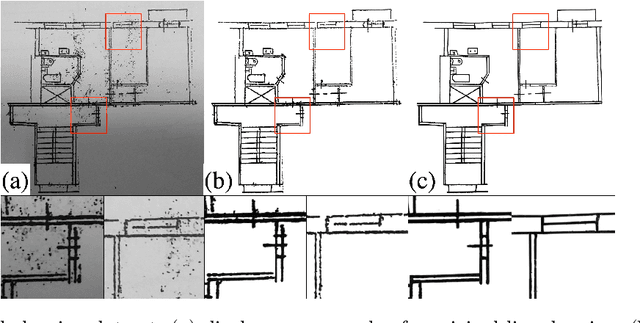
We present a new method for vectorization of technical line drawings, such as floor plans, architectural drawings, and 2D CAD images. Our method includes (1) a deep learning-based cleaning stage to eliminate the background and imperfections in the image and fill in missing parts, (2) a transformer-based network to estimate vector primitives, and (3) optimization procedure to obtain the final primitive configurations. We train the networks on synthetic data, renderings of vector line drawings, and manually vectorized scans of line drawings. Our method quantitatively and qualitatively outperforms a number of existing techniques on a collection of representative technical drawings.
User-Controllable Multi-Texture Synthesis with Generative Adversarial Networks
Apr 24, 2019We propose a novel multi-texture synthesis model based on generative adversarial networks (GANs) with a user-controllable mechanism. The user control ability allows to explicitly specify the texture which should be generated by the model. This property follows from using an encoder part which learns a latent representation for each texture from the dataset. To ensure a dataset coverage, we use an adversarial loss function that penalizes for incorrect reproductions of a given texture. In experiments, we show that our model can learn descriptive texture manifolds for large datasets and from raw data such as a collection of high-resolution photos. Moreover, we apply our method to produce 3D textures and show that it outperforms existing baselines.
Reconstruction of 3D Porous Media From 2D Slices
Jan 29, 2019
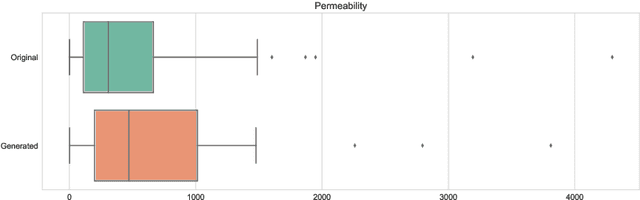

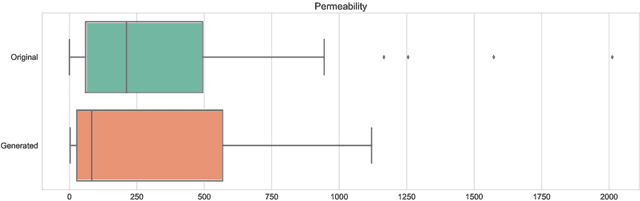
We propose a novel deep learning architecture for three-dimensional porous media structure reconstruction from two-dimensional slices. A high-level idea is that we fit a distribution on all possible three-dimensional structures of a specific type based on the given dataset of samples. Then, given partial information (central slices) we recover the three-dimensional structure that is built around such slices. Technically, it is implemented as a deep neural network with encoder, generator and discriminator modules. Numerical experiments show that this method gives a good reconstruction in terms of Minkowski functionals.
Inductive Conformal Martingales for Change-Point Detection
Jun 11, 2017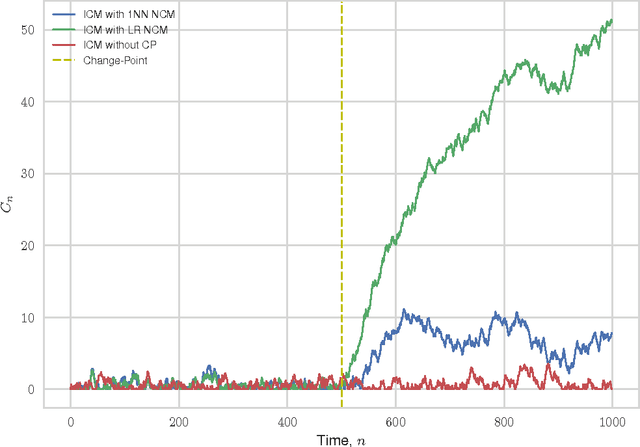

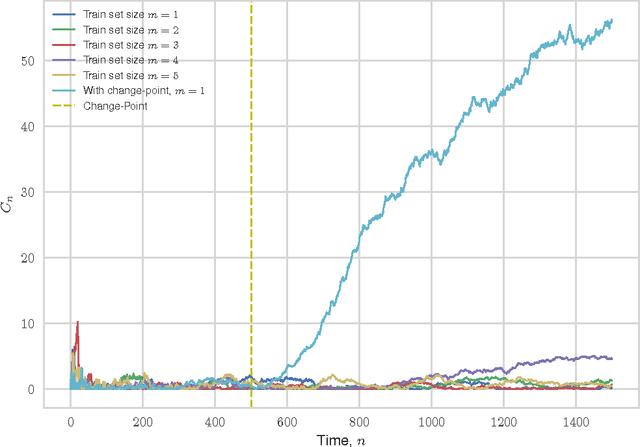

We consider the problem of quickest change-point detection in data streams. Classical change-point detection procedures, such as CUSUM, Shiryaev-Roberts and Posterior Probability statistics, are optimal only if the change-point model is known, which is an unrealistic assumption in typical applied problems. Instead we propose a new method for change-point detection based on Inductive Conformal Martingales, which requires only the independence and identical distribution of observations. We compare the proposed approach to standard methods, as well as to change-point detection oracles, which model a typical practical situation when we have only imprecise (albeit parametric) information about pre- and post-change data distributions. Results of comparison provide evidence that change-point detection based on Inductive Conformal Martingales is an efficient tool, capable to work under quite general conditions unlike traditional approaches.
Steganographic Generative Adversarial Networks
Mar 16, 2017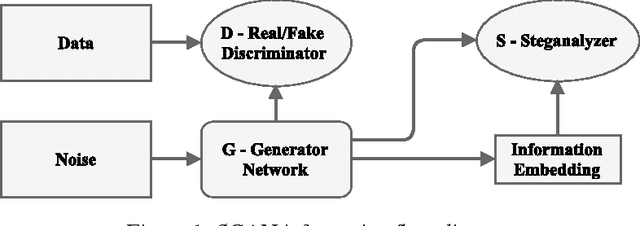
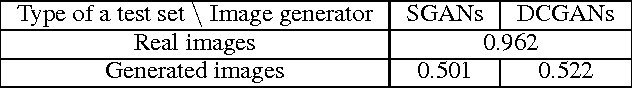


Steganography is collection of methods to hide secret information ("payload") within non-secret information ("container"). Its counterpart, Steganalysis, is the practice of determining if a message contains a hidden payload, and recovering it if possible. Presence of hidden payloads is typically detected by a binary classifier. In the present study, we propose a new model for generating image-like containers based on Deep Convolutional Generative Adversarial Networks (DCGAN). This approach allows to generate more setganalysis-secure message embedding using standard steganography algorithms. Experiment results demonstrate that the new model successfully deceives the steganography analyzer, and for this reason, can be used in steganographic applications.