 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValidity and efficiency of the conformal CUSUM procedure
Dec 04, 2024



In this paper we study the validity and efficiency of a conformal version of the CUSUM procedure for change detection both experimentally and theoretically.
Conformal testing: binary case with Markov alternatives
Nov 02, 2021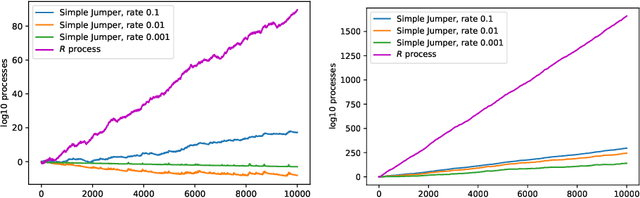
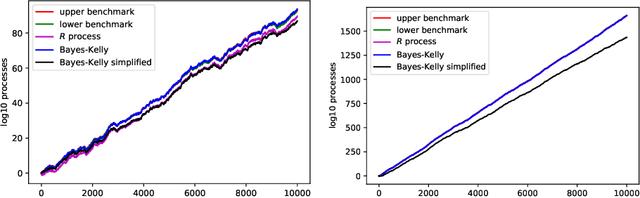
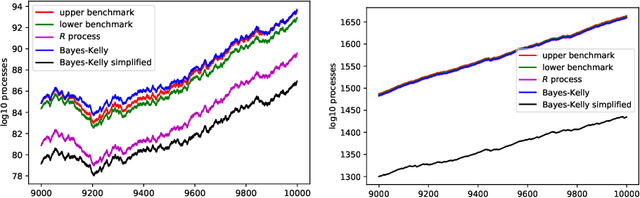

We continue study of conformal testing in binary model situations. In this note we consider Markov alternatives to the null hypothesis of exchangeability. We propose two new classes of conformal test martingales; one class is statistically efficient in our experiments, and the other class partially sacrifices statistical efficiency to gain computational efficiency.
Retrain or not retrain: Conformal test martingales for change-point detection
Feb 20, 2021
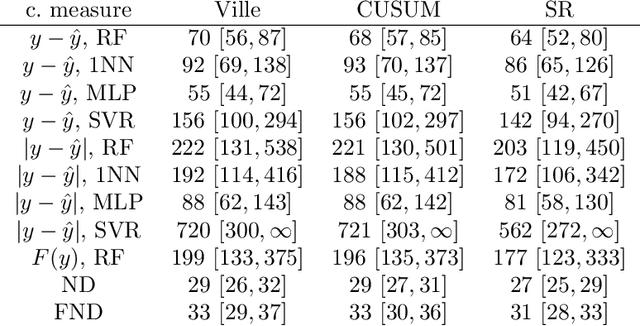
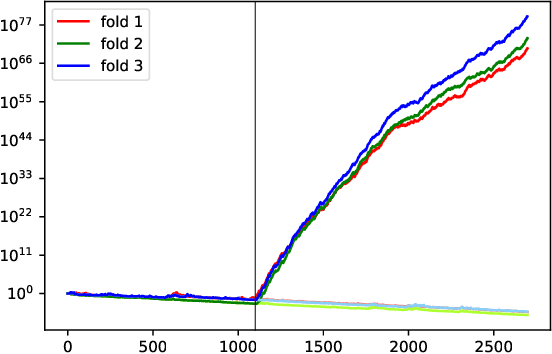
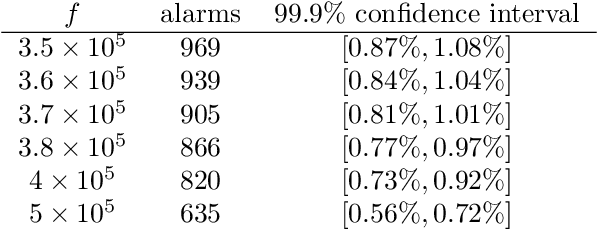
We argue for supplementing the process of training a prediction algorithm by setting up a scheme for detecting the moment when the distribution of the data changes and the algorithm needs to be retrained. Our proposed schemes are based on exchangeability martingales, i.e., processes that are martingales under any exchangeable distribution for the data. Our method, based on conformal prediction, is general and can be applied on top of any modern prediction algorithm. Its validity is guaranteed, and in this paper we make first steps in exploring its efficiency.
Computationally efficient versions of conformal predictive distributions
Nov 03, 2019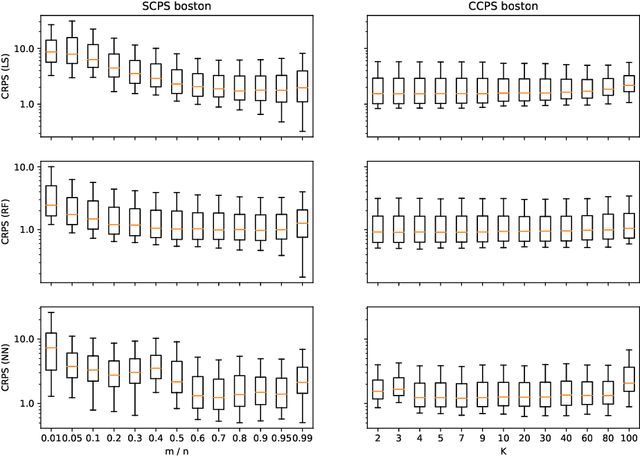


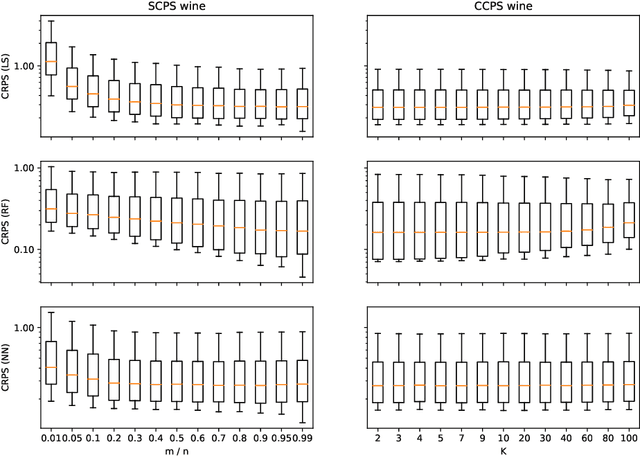
Conformal predictive systems are a recent modification of conformal predictors that output, in regression problems, probability distributions for labels of test observations rather than set predictions. The extra information provided by conformal predictive systems may be useful, e.g., in decision making problems. Conformal predictive systems inherit the relative computational inefficiency of conformal predictors. In this paper we discuss two computationally efficient versions of conformal predictive systems, which we call split conformal predictive systems and cross-conformal predictive systems. The main advantage of split conformal predictive systems is their guaranteed validity, whereas for cross-conformal predictive systems validity only holds empirically and in the absence of excessive randomization. The main advantage of cross-conformal predictive systems is their greater predictive efficiency.
Multi-level conformal clustering: A distribution-free technique for clustering and anomaly detection
Oct 21, 2019
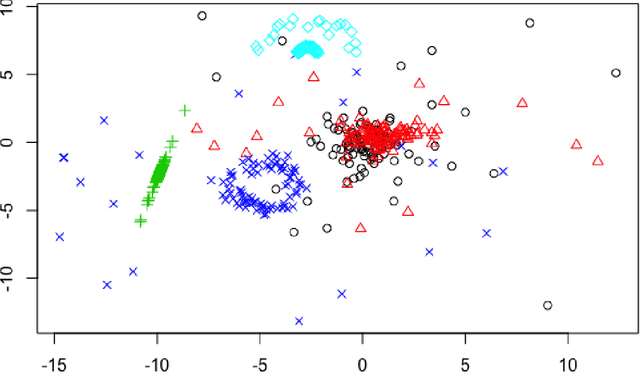
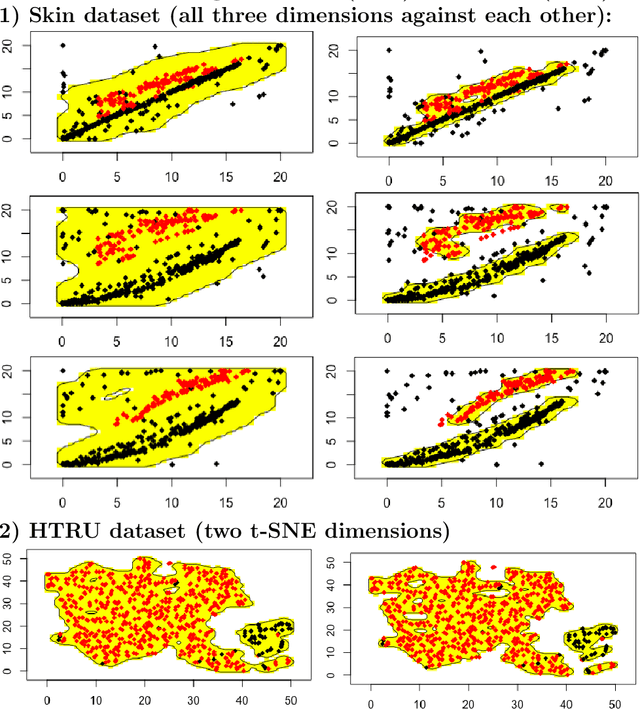
In this work we present a clustering technique called \textit{multi-level conformal clustering (MLCC)}. The technique is hierarchical in nature because it can be performed at multiple significance levels which yields greater insight into the data than performing it at just one level. We describe the theoretical underpinnings of MLCC, compare and contrast it with the hierarchical clustering algorithm, and then apply it to real world datasets to assess its performance. There are several advantages to using MLCC over more classical clustering techniques: Once a significance level has been set, MLCC is able to automatically select the number of clusters. Furthermore, thanks to the conformal prediction framework the resulting clustering model has a clear statistical meaning without any assumptions about the distribution of the data. This statistical robustness also allows us to perform clustering and anomaly detection simultaneously. Moreover, due to the flexibility of the conformal prediction framework, our algorithm can be used on top of many other machine learning algorithms.
Conformal predictive distributions with kernels
Oct 24, 2017

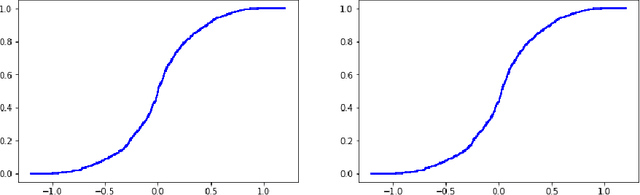
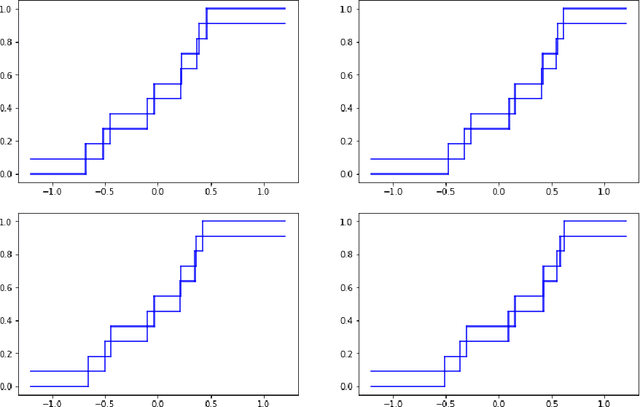
This paper reviews the checkered history of predictive distributions in statistics and discusses two developments, one from recent literature and the other new. The first development is bringing predictive distributions into machine learning, whose early development was so deeply influenced by two remarkable groups at the Institute of Automation and Remote Control. The second development is combining predictive distributions with kernel methods, which were originated by one of those groups, including Emmanuel Braverman.
Inductive Conformal Martingales for Change-Point Detection
Jun 11, 2017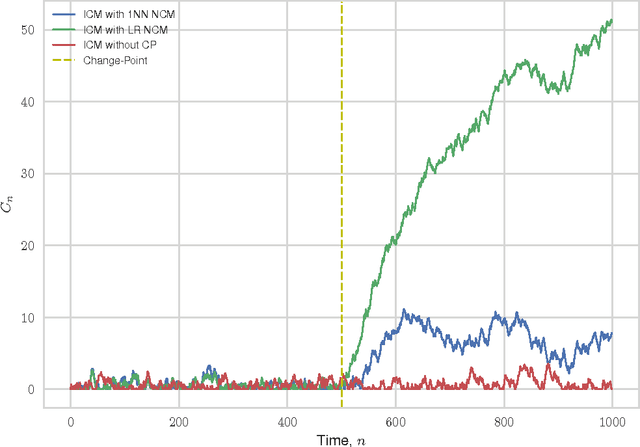

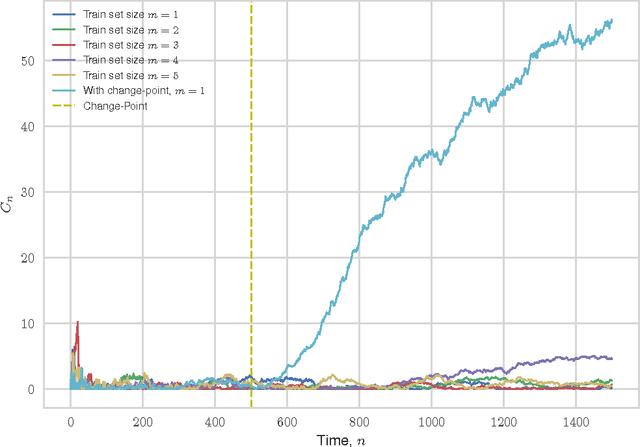

We consider the problem of quickest change-point detection in data streams. Classical change-point detection procedures, such as CUSUM, Shiryaev-Roberts and Posterior Probability statistics, are optimal only if the change-point model is known, which is an unrealistic assumption in typical applied problems. Instead we propose a new method for change-point detection based on Inductive Conformal Martingales, which requires only the independence and identical distribution of observations. We compare the proposed approach to standard methods, as well as to change-point detection oracles, which model a typical practical situation when we have only imprecise (albeit parametric) information about pre- and post-change data distributions. Results of comparison provide evidence that change-point detection based on Inductive Conformal Martingales is an efficient tool, capable to work under quite general conditions unlike traditional approaches.
Criteria of efficiency for conformal prediction
Sep 14, 2016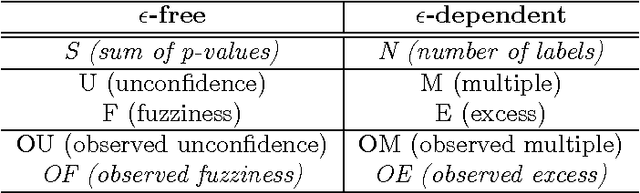
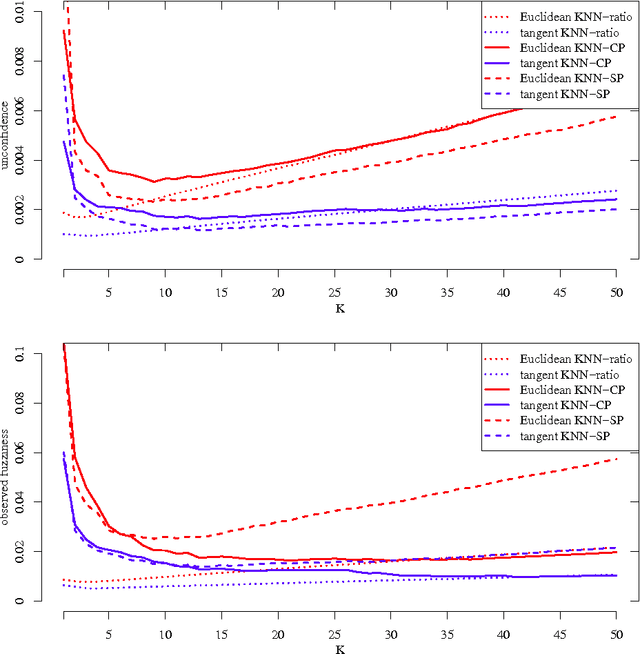
We study optimal conformity measures for various criteria of efficiency of classification in an idealised setting. This leads to an important class of criteria of efficiency that we call probabilistic; it turns out that the most standard criteria of efficiency used in literature on conformal prediction are not probabilistic unless the problem of classification is binary. We consider both unconditional and label-conditional conformal prediction.
Conformal Predictors for Compound Activity Prediction
Mar 14, 2016
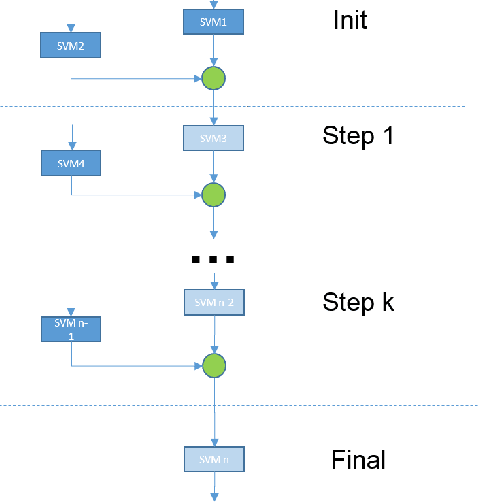

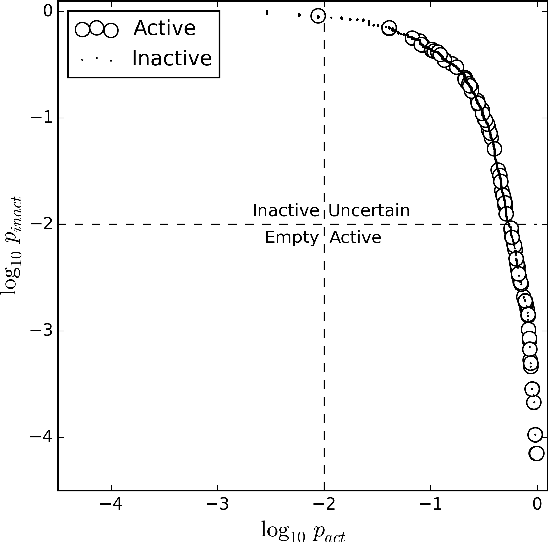
The paper presents an application of Conformal Predictors to a chemoinformatics problem of identifying activities of chemical compounds. The paper addresses some specific challenges of this domain: a large number of compounds (training examples), high-dimensionality of feature space, sparseness and a strong class imbalance. A variant of conformal predictors called Inductive Mondrian Conformal Predictor is applied to deal with these challenges. Results are presented for several non-conformity measures (NCM) extracted from underlying algorithms and different kernels. A number of performance measures are used in order to demonstrate the flexibility of Inductive Mondrian Conformal Predictors in dealing with such a complex set of data. Keywords: Conformal Prediction, Confidence Estimation, Chemoinformatics, Non-Conformity Measure.
Plug-in martingales for testing exchangeability on-line
Jun 28, 2012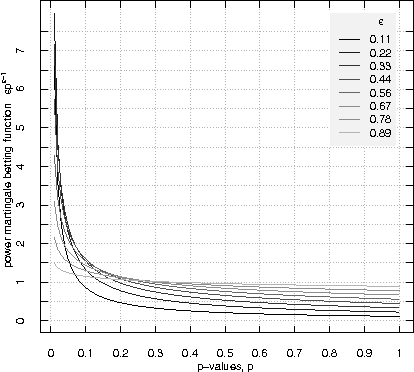
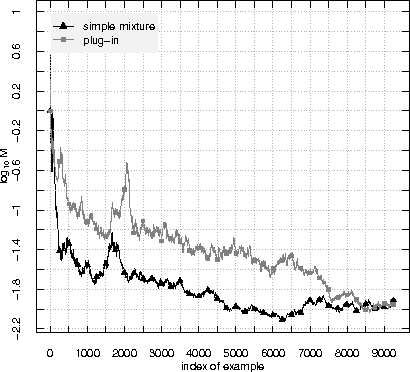
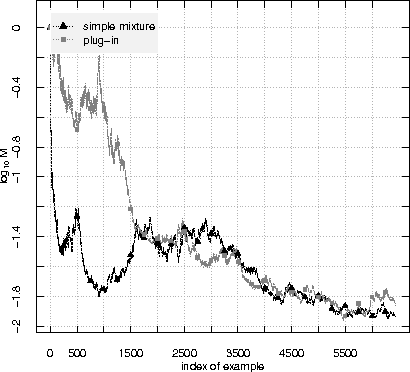
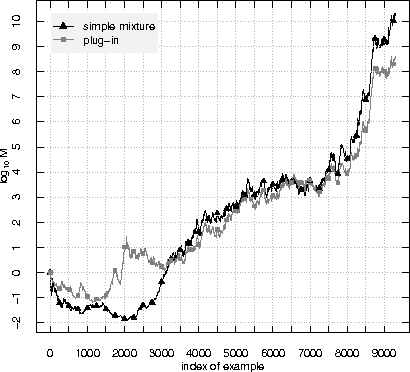
A standard assumption in machine learning is the exchangeability of data, which is equivalent to assuming that the examples are generated from the same probability distribution independently. This paper is devoted to testing the assumption of exchangeability on-line: the examples arrive one by one, and after receiving each example we would like to have a valid measure of the degree to which the assumption of exchangeability has been falsified. Such measures are provided by exchangeability martingales. We extend known techniques for constructing exchangeability martingales and show that our new method is competitive with the martingales introduced before. Finally we investigate the performance of our testing method on two benchmark datasets, USPS and Statlog Satellite data; for the former, the known techniques give satisfactory results, but for the latter our new more flexible method becomes necessary.