 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifier Calibration at Scale: An Empirical Study of Model-Agnostic Post-Hoc Methods
Jan 19, 2026We study model-agnostic post-hoc calibration methods intended to improve probabilistic predictions in supervised binary classification on real i.i.d. tabular data, with particular emphasis on conformal and Venn-based approaches that provide distribution-free validity guarantees under exchangeability. We benchmark 21 widely used classifiers, including linear models, SVMs, tree ensembles (CatBoost, XGBoost, LightGBM), and modern tabular neural and foundation models, on binary tasks from the TabArena-v0.1 suite using randomized, stratified five-fold cross-validation with a held-out test fold. Five calibrators; Isotonic regression, Platt scaling, Beta calibration, Venn-Abers predictors, and Pearsonify are trained on a separate calibration split and applied to test predictions. Calibration is evaluated using proper scoring rules (log-loss and Brier score) and diagnostic measures (Spiegelhalter's Z, ECE, and ECI), alongside discrimination (AUC-ROC) and standard classification metrics. Across tasks and architectures, Venn-Abers predictors achieve the largest average reductions in log-loss, followed closely by Beta calibration, while Platt scaling exhibits weaker and less consistent effects. Beta calibration improves log-loss most frequently across tasks, whereas Venn-Abers displays fewer instances of extreme degradation and slightly more instances of extreme improvement. Importantly, we find that commonly used calibration procedures, most notably Platt scaling and isotonic regression, can systematically degrade proper scoring performance for strong modern tabular models. Overall classification performance is often preserved, but calibration effects vary substantially across datasets and architectures, and no method dominates uniformly. In expectation, all methods except Pearsonify slightly increase accuracy, but the effect is marginal, with the largest expected gain about 0.008%.
Computationally efficient versions of conformal predictive distributions
Nov 03, 2019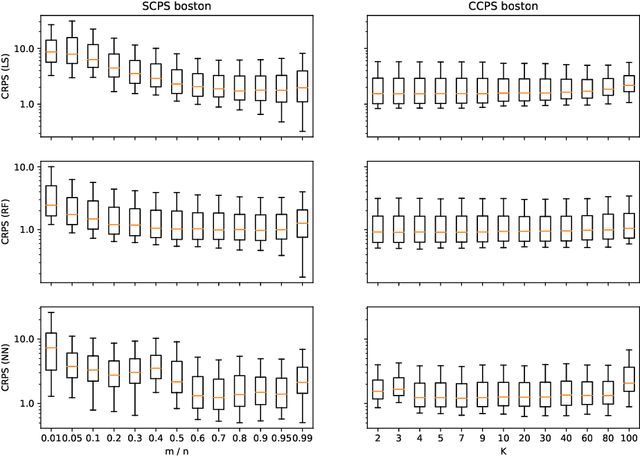


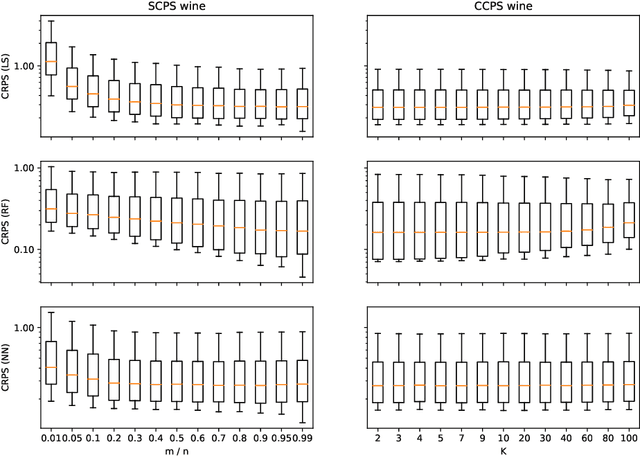
Conformal predictive systems are a recent modification of conformal predictors that output, in regression problems, probability distributions for labels of test observations rather than set predictions. The extra information provided by conformal predictive systems may be useful, e.g., in decision making problems. Conformal predictive systems inherit the relative computational inefficiency of conformal predictors. In this paper we discuss two computationally efficient versions of conformal predictive systems, which we call split conformal predictive systems and cross-conformal predictive systems. The main advantage of split conformal predictive systems is their guaranteed validity, whereas for cross-conformal predictive systems validity only holds empirically and in the absence of excessive randomization. The main advantage of cross-conformal predictive systems is their greater predictive efficiency.
Conformal predictive distributions with kernels
Oct 24, 2017

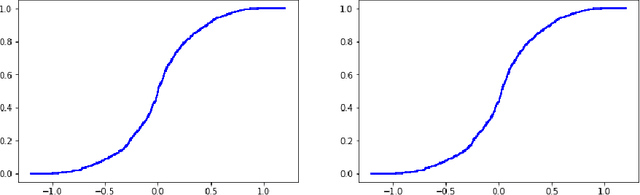
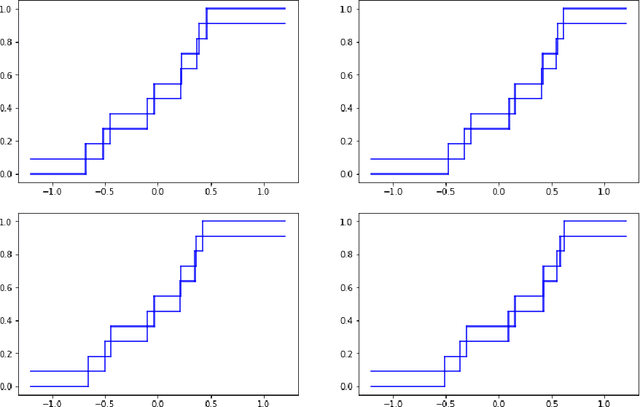
This paper reviews the checkered history of predictive distributions in statistics and discusses two developments, one from recent literature and the other new. The first development is bringing predictive distributions into machine learning, whose early development was so deeply influenced by two remarkable groups at the Institute of Automation and Remote Control. The second development is combining predictive distributions with kernel methods, which were originated by one of those groups, including Emmanuel Braverman.