 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Distribution Assumption for Unbiased and Consistent Consensus Modelling
Jun 20, 2019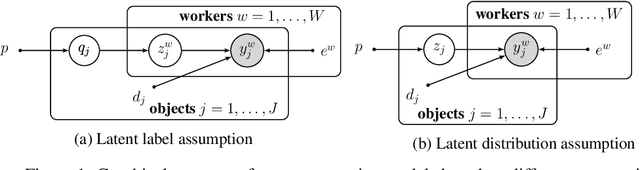
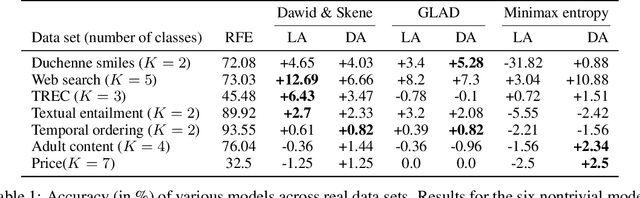
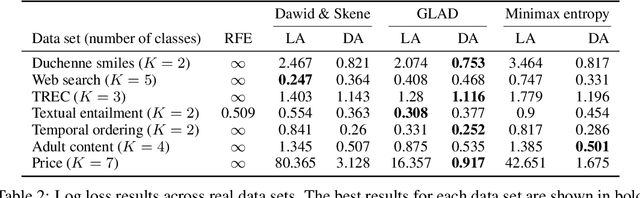
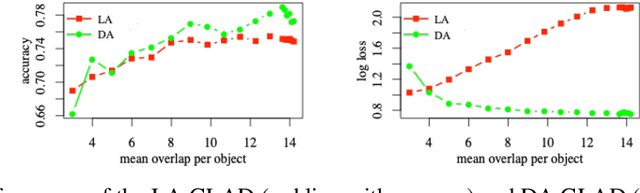
We study the problem of aggregation noisy labels. Usually, it is solved by proposing a stochastic model for the process of generating noisy labels and then estimating the model parameters using the observed noisy labels. A traditional assumption underlying previously introduced generative models is that each object has one latent true label. In contrast, we introduce a novel latent distribution assumption, implying that a unique true label for an object might not exist, but rather each object might have a specific distribution generating a latent subjective label each time the object is observed. Our experiments showed that the novel assumption is more suitable for difficult tasks, when there is an ambiguity in choosing a "true" label for certain objects.
Aggregation of pairwise comparisons with reduction of biases
Jun 09, 2019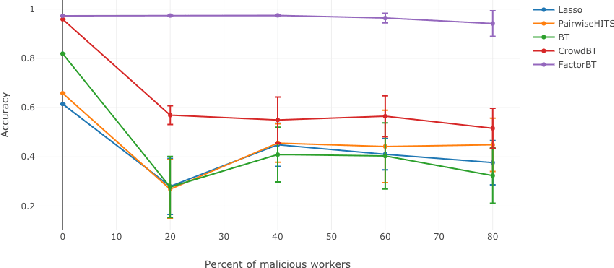

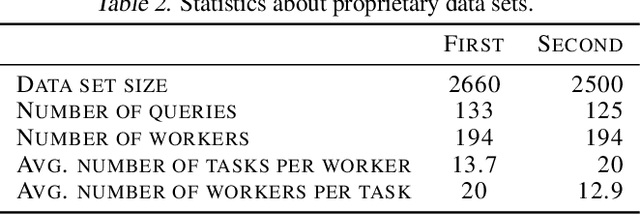
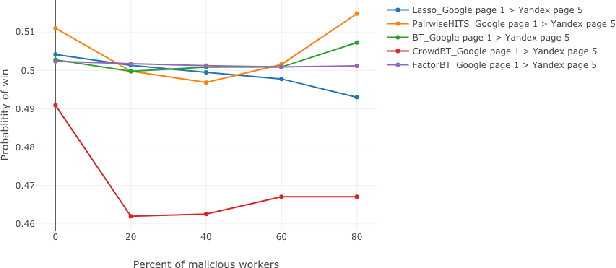
We study the problem of ranking from crowdsourced pairwise comparisons. Answers to pairwise tasks are known to be affected by the position of items on the screen, however, previous models for aggregation of pairwise comparisons do not focus on modeling such kind of biases. We introduce a new aggregation model factorBT for pairwise comparisons, which accounts for certain factors of pairwise tasks that are known to be irrelevant to the result of comparisons but may affect workers' answers due to perceptual reasons. By modeling biases that influence workers, factorBT is able to reduce the effect of biased pairwise comparisons on the resulted ranking. Our empirical studies on real-world data sets showed that factorBT produces more accurate ranking from crowdsourced pairwise comparisons than previously established models.
Criteria of efficiency for conformal prediction
Sep 14, 2016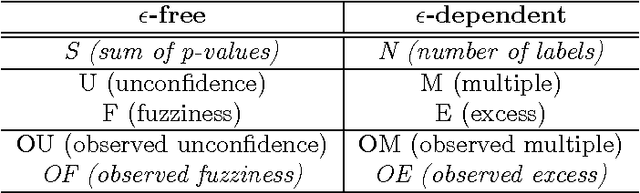
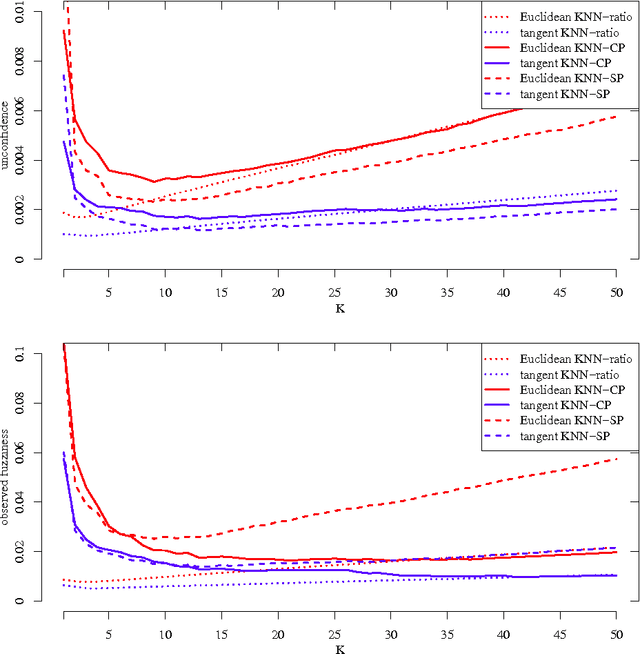
We study optimal conformity measures for various criteria of efficiency of classification in an idealised setting. This leads to an important class of criteria of efficiency that we call probabilistic; it turns out that the most standard criteria of efficiency used in literature on conformal prediction are not probabilistic unless the problem of classification is binary. We consider both unconditional and label-conditional conformal prediction.
Large-scale probabilistic predictors with and without guarantees of validity
Nov 13, 2015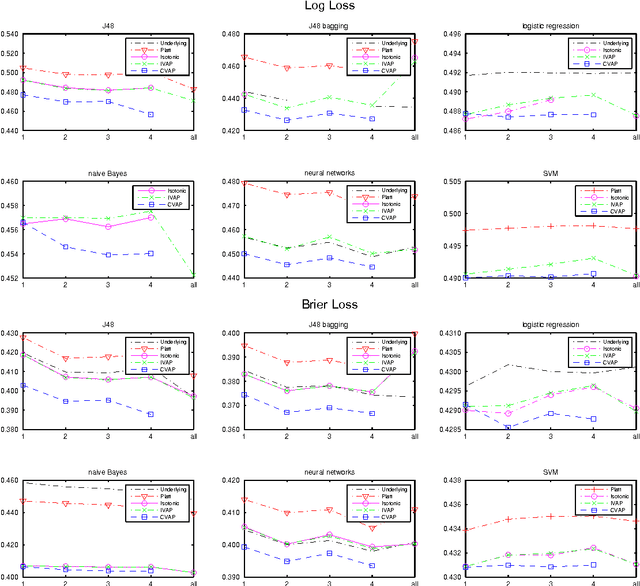
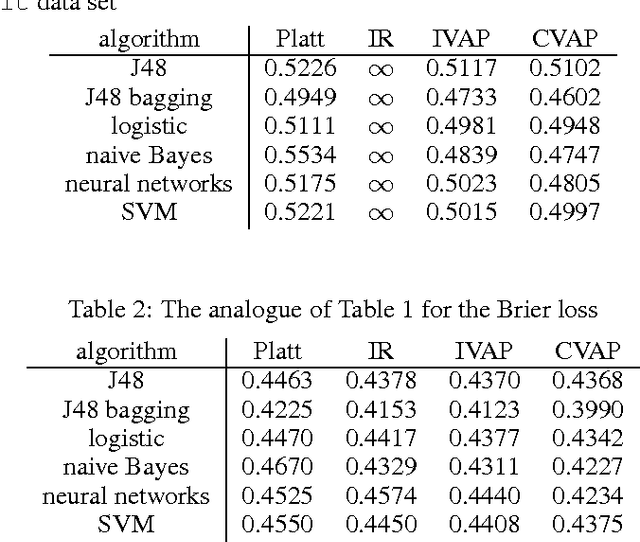
This paper studies theoretically and empirically a method of turning machine-learning algorithms into probabilistic predictors that automatically enjoys a property of validity (perfect calibration) and is computationally efficient. The price to pay for perfect calibration is that these probabilistic predictors produce imprecise (in practice, almost precise for large data sets) probabilities. When these imprecise probabilities are merged into precise probabilities, the resulting predictors, while losing the theoretical property of perfect calibration, are consistently more accurate than the existing methods in empirical studies.
From conformal to probabilistic prediction
Jun 21, 2014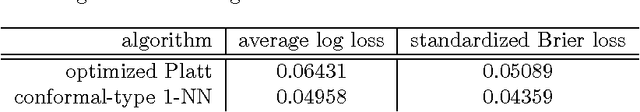

This paper proposes a new method of probabilistic prediction, which is based on conformal prediction. The method is applied to the standard USPS data set and gives encouraging results.
Plug-in martingales for testing exchangeability on-line
Jun 28, 2012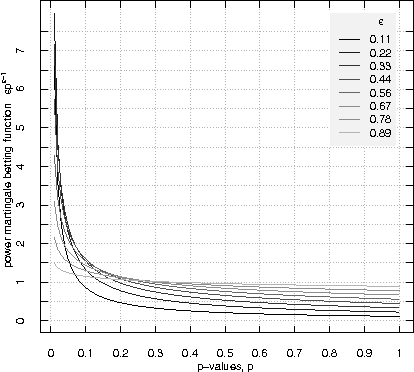
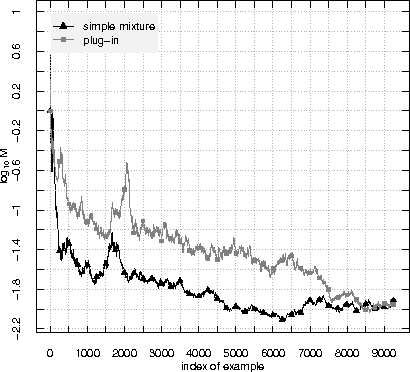
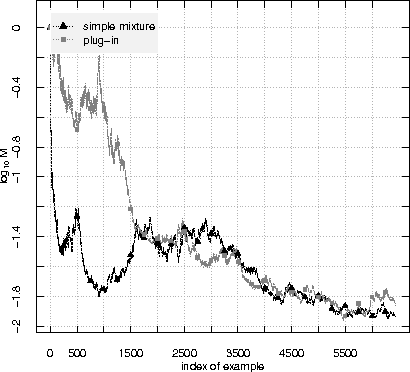
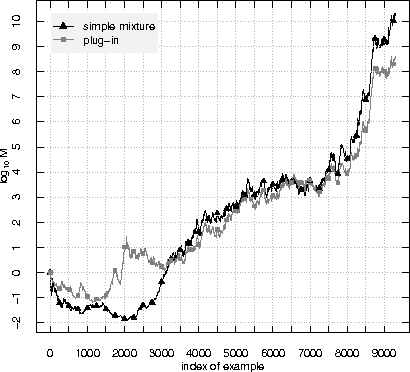
A standard assumption in machine learning is the exchangeability of data, which is equivalent to assuming that the examples are generated from the same probability distribution independently. This paper is devoted to testing the assumption of exchangeability on-line: the examples arrive one by one, and after receiving each example we would like to have a valid measure of the degree to which the assumption of exchangeability has been falsified. Such measures are provided by exchangeability martingales. We extend known techniques for constructing exchangeability martingales and show that our new method is competitive with the martingales introduced before. Finally we investigate the performance of our testing method on two benchmark datasets, USPS and Statlog Satellite data; for the former, the known techniques give satisfactory results, but for the latter our new more flexible method becomes necessary.