 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite-State Extreme Effect Variable
Dec 24, 2019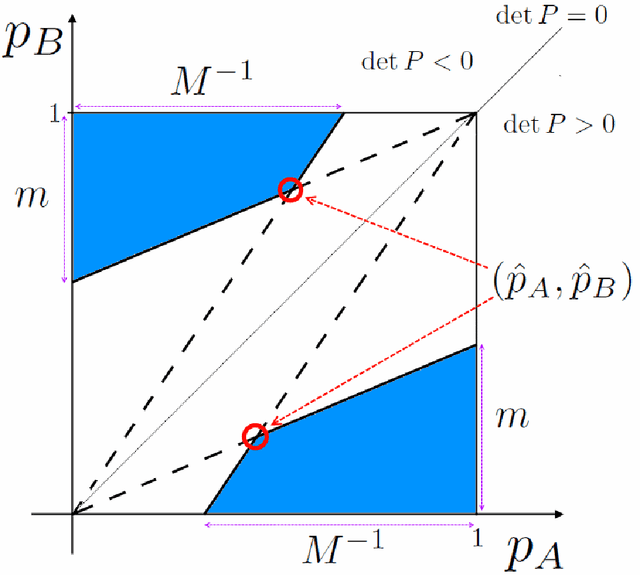

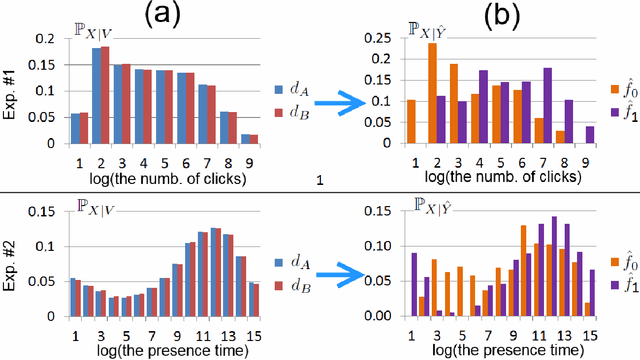
We generalize to the finite-state case the notion of the extreme effect variable $Y$ that accumulates all the effect of a variant variable $V$ observed in changes of another variable $X$. We conduct theoretical analysis and turn the problem of finding of an effect variable into a problem of a simultaneous decomposition of a set of distributions. The states of the extreme effect variable, on the one hand, are minimally affected by the variant variable $V$ and, on the other hand, are extremely different with respect to the observable variable $X$. We apply our technique to online evaluation of a web search engine through A/B testing and show its utility.
Reserve Pricing in Repeated Second-Price Auctions with Strategic Bidders
Jun 21, 2019

We study revenue optimization learning algorithms for repeated second-price auctions with reserve where a seller interacts with multiple strategic bidders each of which holds a fixed private valuation for a good and seeks to maximize his expected future cumulative discounted surplus. We propose a novel algorithm that has strategic regret upper bound of $O(\log\log T)$ for worst-case valuations. This pricing is based on our novel transformation that upgrades an algorithm designed for the setup with a single buyer to the multi-buyer case. We provide theoretical guarantees on the ability of a transformed algorithm to learn the valuation of a strategic buyer, which has uncertainty about the future due to the presence of rivals.
Aggregation of pairwise comparisons with reduction of biases
Jun 09, 2019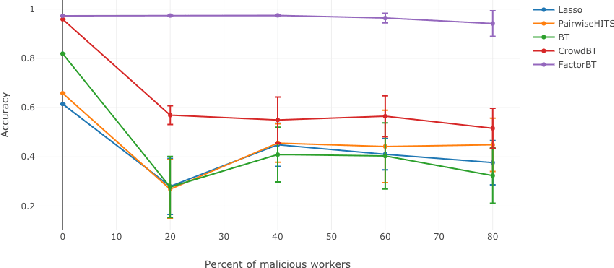

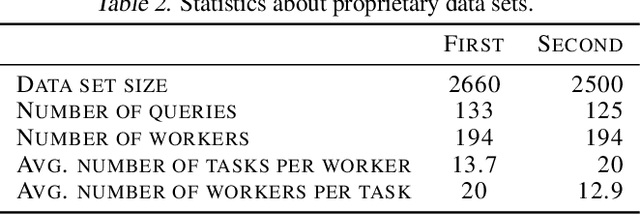
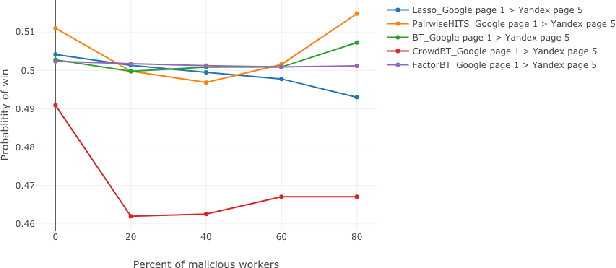
We study the problem of ranking from crowdsourced pairwise comparisons. Answers to pairwise tasks are known to be affected by the position of items on the screen, however, previous models for aggregation of pairwise comparisons do not focus on modeling such kind of biases. We introduce a new aggregation model factorBT for pairwise comparisons, which accounts for certain factors of pairwise tasks that are known to be irrelevant to the result of comparisons but may affect workers' answers due to perceptual reasons. By modeling biases that influence workers, factorBT is able to reduce the effect of biased pairwise comparisons on the resulted ranking. Our empirical studies on real-world data sets showed that factorBT produces more accurate ranking from crowdsourced pairwise comparisons than previously established models.
On consistency of optimal pricing algorithms in repeated posted-price auctions with strategic buyer
Feb 08, 2018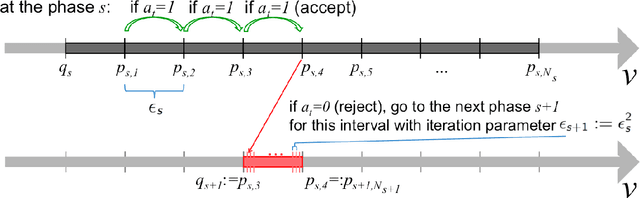
We study revenue optimization learning algorithms for repeated posted-price auctions where a seller interacts with a single strategic buyer that holds a fixed private valuation for a good and seeks to maximize his cumulative discounted surplus. For this setting, first, we propose a novel algorithm that never decreases offered prices and has a tight strategic regret bound in $\Theta(\log\log T)$ under some mild assumptions on the buyer surplus discounting. This result closes the open research question on the existence of a no-regret horizon-independent weakly consistent pricing. The proposed algorithm is inspired by our observation that a double decrease of offered prices in a weakly consistent algorithm is enough to cause a linear regret. This motivates us to construct a novel transformation that maps a right-consistent algorithm to a weakly consistent one that never decreases offered prices. Second, we outperform the previously known strategic regret upper bound of the algorithm PRRFES, where the improvement is achieved by means of a finer constant factor $C$ of the principal term $C\log\log T$ in this upper bound. Finally, we generalize results on strategic regret previously known for geometric discounting of the buyer's surplus to discounting of other types, namely: the optimality of the pricing PRRFES to the case of geometrically concave decreasing discounting; and linear lower bound on the strategic regret of a wide range of horizon-independent weakly consistent algorithms to the case of arbitrary discounts.
User Model-Based Intent-Aware Metrics for Multilingual Search Evaluation
Dec 13, 2016
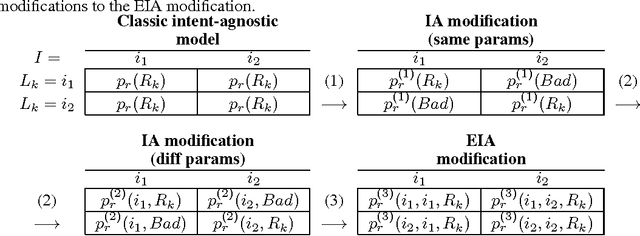
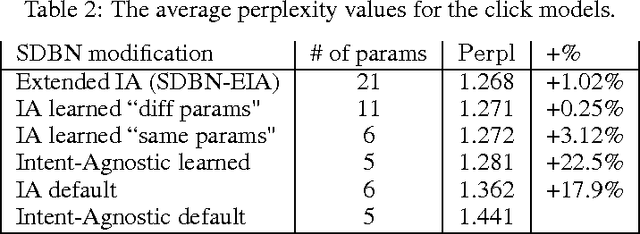
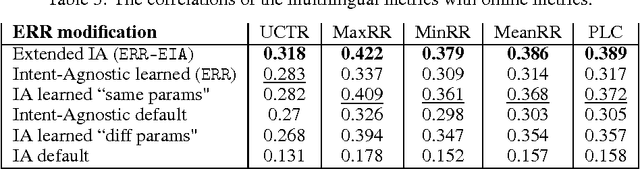
Despite the growing importance of multilingual aspect of web search, no appropriate offline metrics to evaluate its quality are proposed so far. At the same time, personal language preferences can be regarded as intents of a query. This approach translates the multilingual search problem into a particular task of search diversification. Furthermore, the standard intent-aware approach could be adopted to build a diversified metric for multilingual search on the basis of a classical IR metric such as ERR. The intent-aware approach estimates user satisfaction under a user behavior model. We show however that the underlying user behavior models is not realistic in the multilingual case, and the produced intent-aware metric do not appropriately estimate the user satisfaction. We develop a novel approach to build intent-aware user behavior models, which overcome these limitations and convert to quality metrics that better correlate with standard online metrics of user satisfaction.
* 7 pages, 1 figure, 3 tables
Prediction of Video Popularity in the Absence of Reliable Data from Video Hosting Services: Utility of Traces Left by Users on the Web
Nov 28, 2016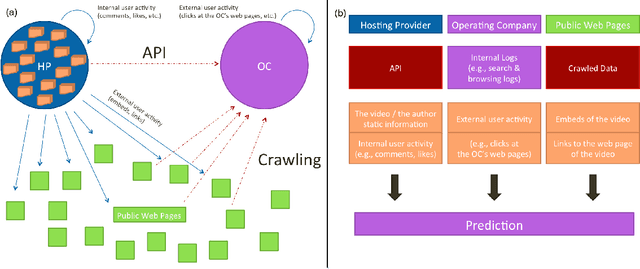
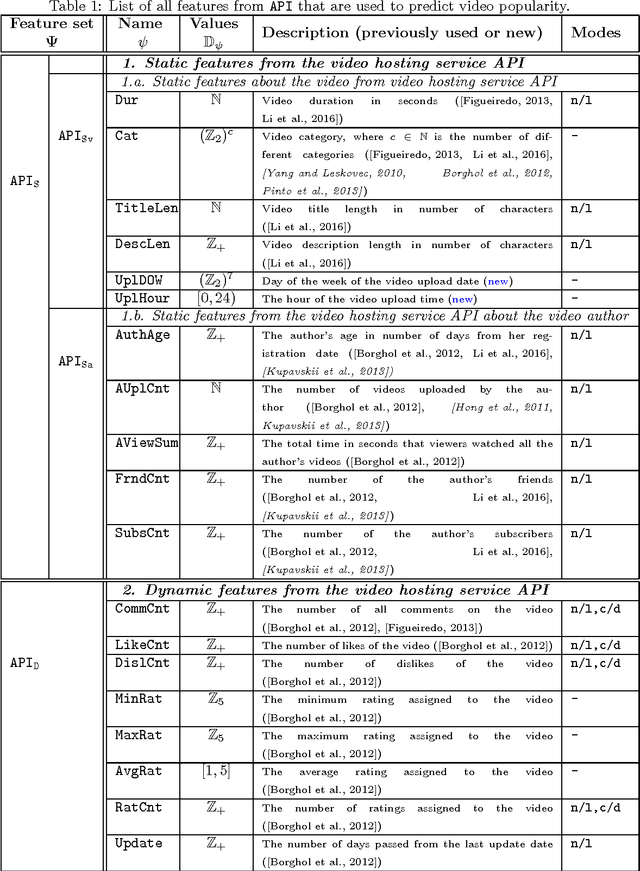
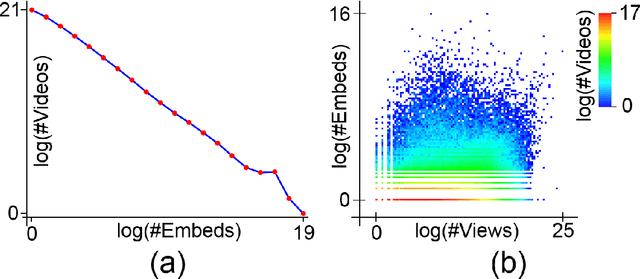
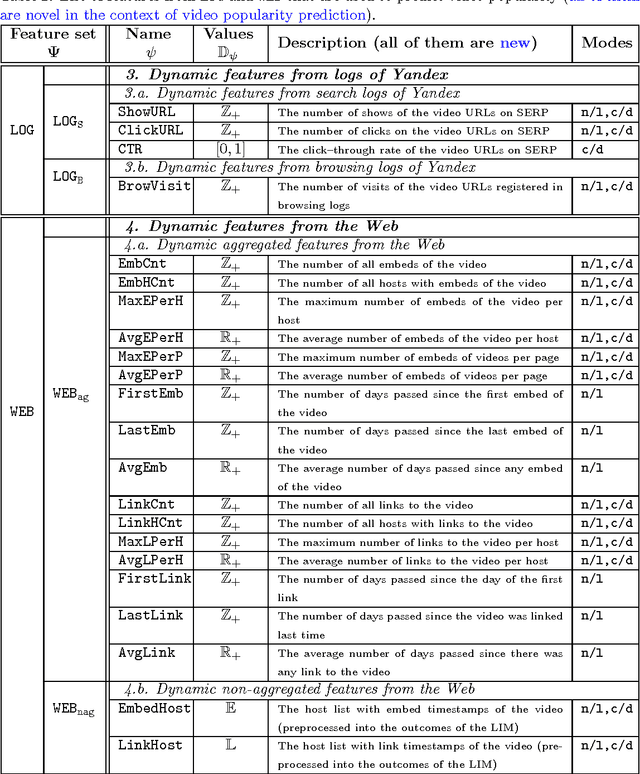
With the growth of user-generated content, we observe the constant rise of the number of companies, such as search engines, content aggregators, etc., that operate with tremendous amounts of web content not being the services hosting it. Thus, aiming to locate the most important content and promote it to the users, they face the need of estimating the current and predicting the future content popularity. In this paper, we approach the problem of video popularity prediction not from the side of a video hosting service, as done in all previous studies, but from the side of an operating company, which provides a popular video search service that aggregates content from different video hosting websites. We investigate video popularity prediction based on features from three primary sources available for a typical operating company: first, the content hosting provider may deliver its data via its API, second, the operating company makes use of its own search and browsing logs, third, the company crawls information about embeds of a video and links to a video page from publicly available resources on the Web. We show that video popularity prediction based on the embed and link data coupled with the internal search and browsing data significantly improves video popularity prediction based only on the data provided by the video hosting and can even adequately replace the API data in the cases when it is partly or completely unavailable.