 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrediction of Video Popularity in the Absence of Reliable Data from Video Hosting Services: Utility of Traces Left by Users on the Web
Paper and Code
Nov 28, 2016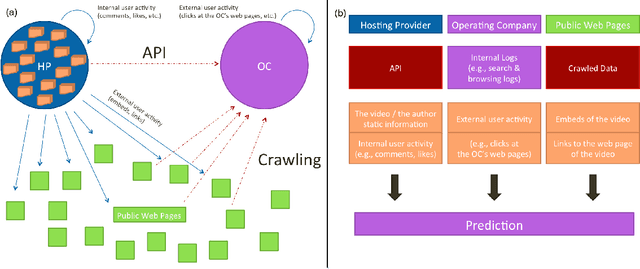
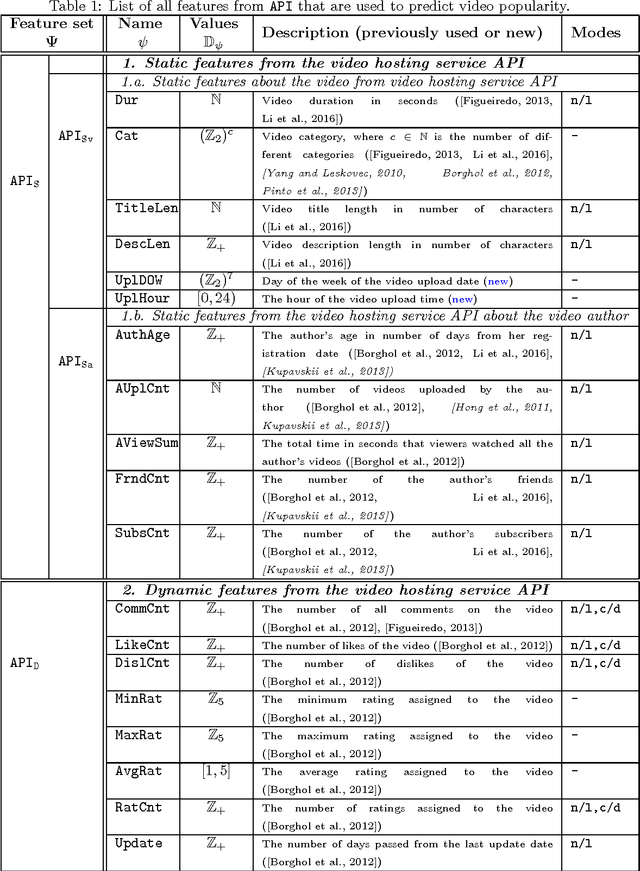
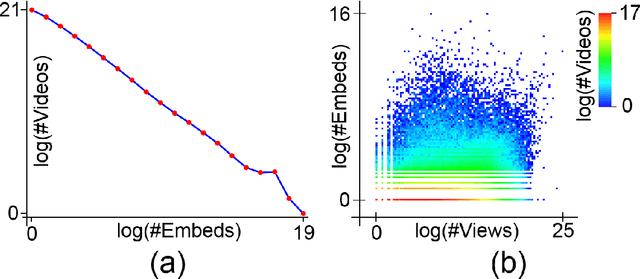
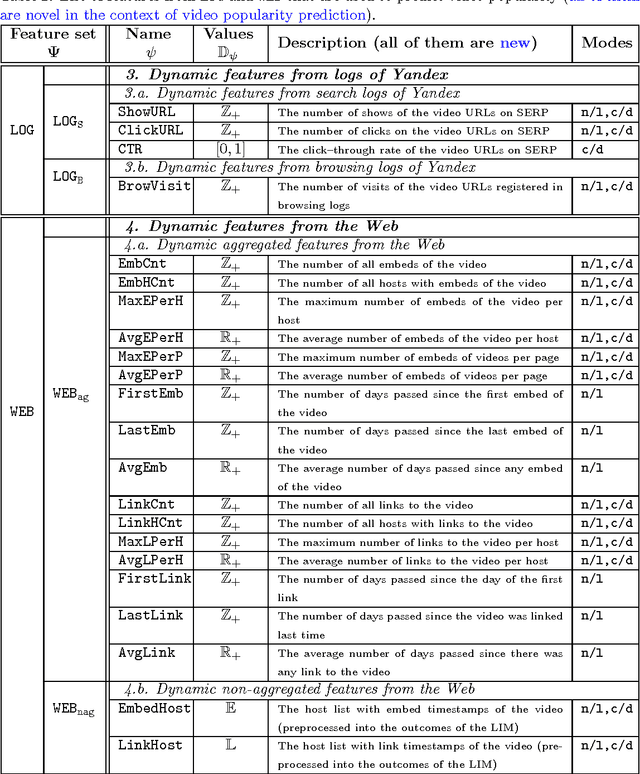
With the growth of user-generated content, we observe the constant rise of the number of companies, such as search engines, content aggregators, etc., that operate with tremendous amounts of web content not being the services hosting it. Thus, aiming to locate the most important content and promote it to the users, they face the need of estimating the current and predicting the future content popularity. In this paper, we approach the problem of video popularity prediction not from the side of a video hosting service, as done in all previous studies, but from the side of an operating company, which provides a popular video search service that aggregates content from different video hosting websites. We investigate video popularity prediction based on features from three primary sources available for a typical operating company: first, the content hosting provider may deliver its data via its API, second, the operating company makes use of its own search and browsing logs, third, the company crawls information about embeds of a video and links to a video page from publicly available resources on the Web. We show that video popularity prediction based on the embed and link data coupled with the internal search and browsing data significantly improves video popularity prediction based only on the data provided by the video hosting and can even adequately replace the API data in the cases when it is partly or completely unavailable.