 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecency Ranking by Diversification of Result Set
Feb 07, 2024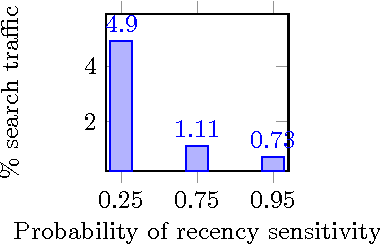
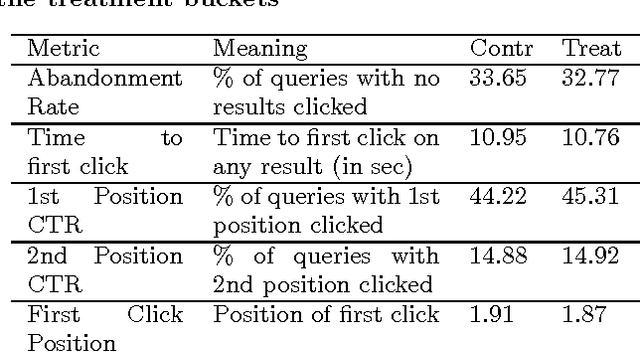
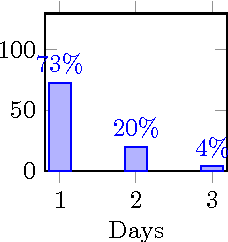
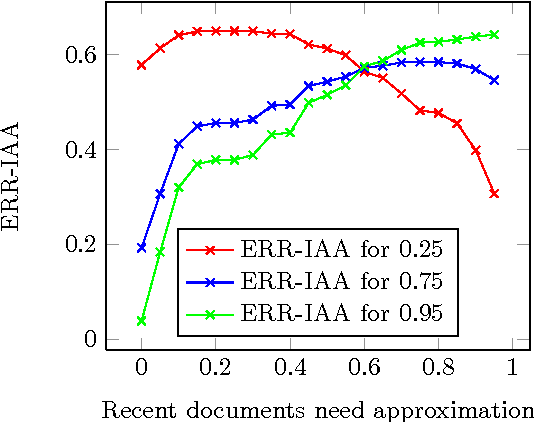
In this paper, we propose a web search retrieval approach which automatically detects recency sensitive queries and increases the freshness of the ordinary document ranking by a degree proportional to the probability of the need in recent content. We propose to solve the recency ranking problem by using result diversification principles and deal with the query's non-topical ambiguity appearing when the need in recent content can be detected only with uncertainty. Our offline and online experiments with millions of queries from real search engine users demonstrate the significant increase in satisfaction of users presented with a search result generated by our approach.
Sequence Modeling with Unconstrained Generation Order
Nov 01, 2019

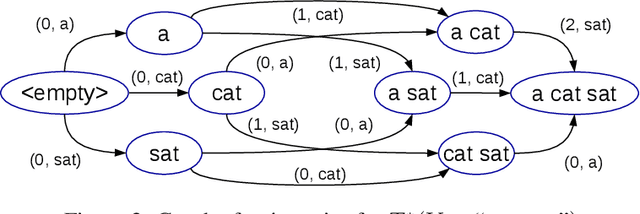

The dominant approach to sequence generation is to produce a sequence in some predefined order, e.g. left to right. In contrast, we propose a more general model that can generate the output sequence by inserting tokens in any arbitrary order. Our model learns decoding order as a result of its training procedure. Our experiments show that this model is superior to fixed order models on a number of sequence generation tasks, such as Machine Translation, Image-to-LaTeX and Image Captioning.
Latent Distribution Assumption for Unbiased and Consistent Consensus Modelling
Jun 20, 2019
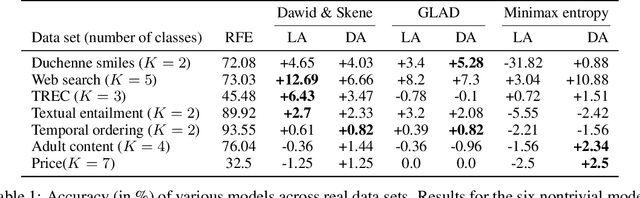
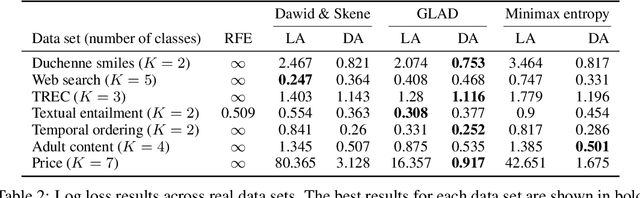
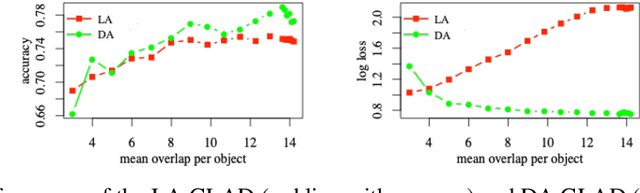
We study the problem of aggregation noisy labels. Usually, it is solved by proposing a stochastic model for the process of generating noisy labels and then estimating the model parameters using the observed noisy labels. A traditional assumption underlying previously introduced generative models is that each object has one latent true label. In contrast, we introduce a novel latent distribution assumption, implying that a unique true label for an object might not exist, but rather each object might have a specific distribution generating a latent subjective label each time the object is observed. Our experiments showed that the novel assumption is more suitable for difficult tasks, when there is an ambiguity in choosing a "true" label for certain objects.
Context-Aware Neural Machine Translation Learns Anaphora Resolution
May 25, 2018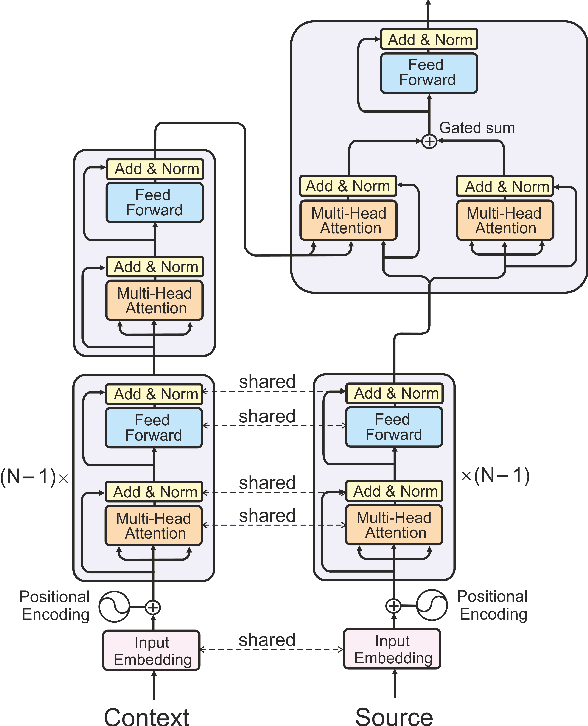

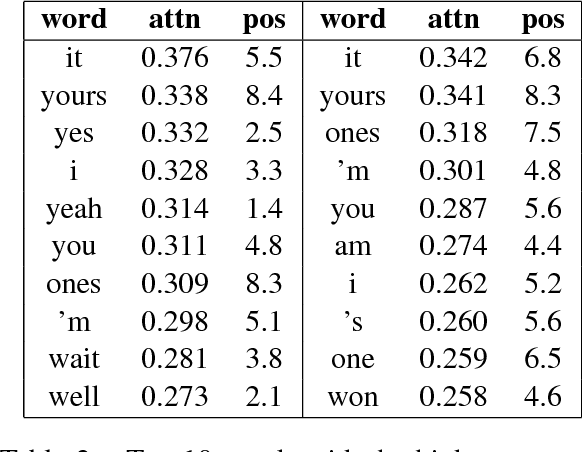
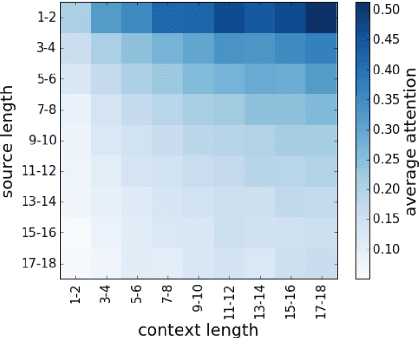
Standard machine translation systems process sentences in isolation and hence ignore extra-sentential information, even though extended context can both prevent mistakes in ambiguous cases and improve translation coherence. We introduce a context-aware neural machine translation model designed in such way that the flow of information from the extended context to the translation model can be controlled and analyzed. We experiment with an English-Russian subtitles dataset, and observe that much of what is captured by our model deals with improving pronoun translation. We measure correspondences between induced attention distributions and coreference relations and observe that the model implicitly captures anaphora. It is consistent with gains for sentences where pronouns need to be gendered in translation. Beside improvements in anaphoric cases, the model also improves in overall BLEU, both over its context-agnostic version (+0.7) and over simple concatenation of the context and source sentences (+0.6).
Finding Influential Training Samples for Gradient Boosted Decision Trees
Mar 12, 2018
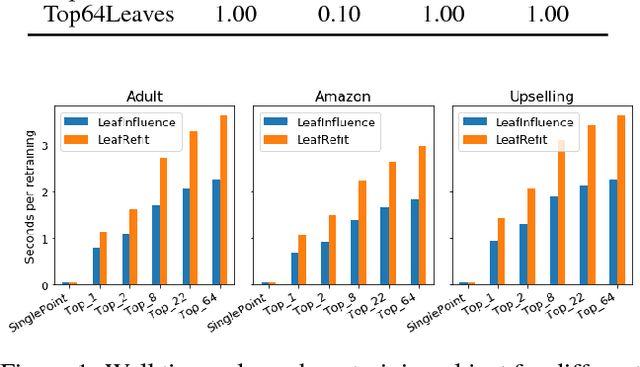
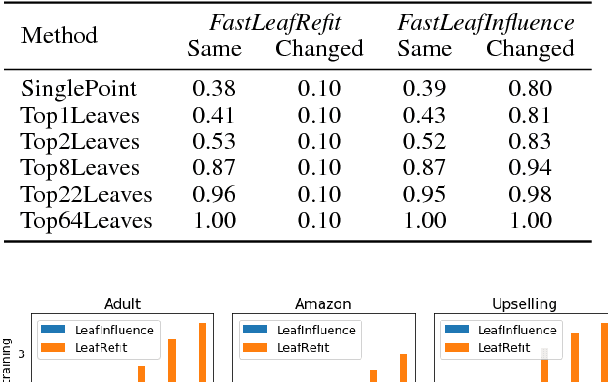
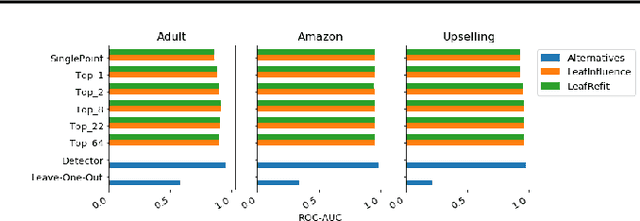
We address the problem of finding influential training samples for a particular case of tree ensemble-based models, e.g., Random Forest (RF) or Gradient Boosted Decision Trees (GBDT). A natural way of formalizing this problem is studying how the model's predictions change upon leave-one-out retraining, leaving out each individual training sample. Recent work has shown that, for parametric models, this analysis can be conducted in a computationally efficient way. We propose several ways of extending this framework to non-parametric GBDT ensembles under the assumption that tree structures remain fixed. Furthermore, we introduce a general scheme of obtaining further approximations to our method that balance the trade-off between performance and computational complexity. We evaluate our approaches on various experimental setups and use-case scenarios and demonstrate both the quality of our approach to finding influential training samples in comparison to the baselines and its computational efficiency.
Riemannian Optimization for Skip-Gram Negative Sampling
Apr 26, 2017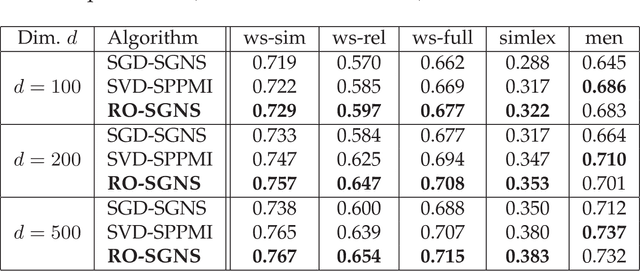
Skip-Gram Negative Sampling (SGNS) word embedding model, well known by its implementation in "word2vec" software, is usually optimized by stochastic gradient descent. However, the optimization of SGNS objective can be viewed as a problem of searching for a good matrix with the low-rank constraint. The most standard way to solve this type of problems is to apply Riemannian optimization framework to optimize the SGNS objective over the manifold of required low-rank matrices. In this paper, we propose an algorithm that optimizes SGNS objective using Riemannian optimization and demonstrates its superiority over popular competitors, such as the original method to train SGNS and SVD over SPPMI matrix.
User Model-Based Intent-Aware Metrics for Multilingual Search Evaluation
Dec 13, 2016
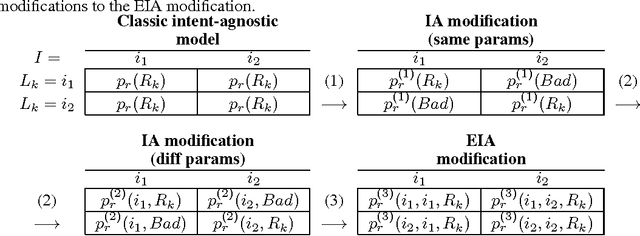
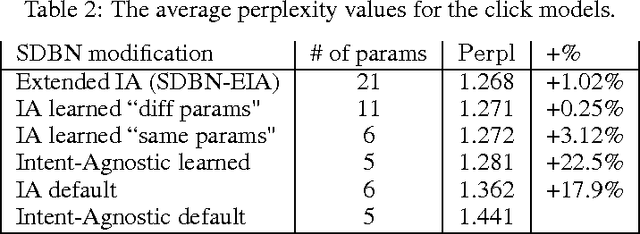
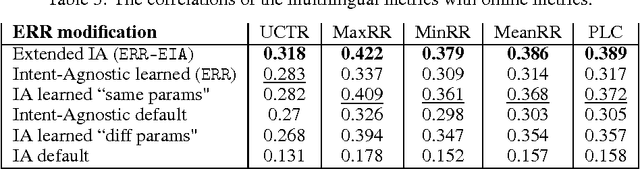
Despite the growing importance of multilingual aspect of web search, no appropriate offline metrics to evaluate its quality are proposed so far. At the same time, personal language preferences can be regarded as intents of a query. This approach translates the multilingual search problem into a particular task of search diversification. Furthermore, the standard intent-aware approach could be adopted to build a diversified metric for multilingual search on the basis of a classical IR metric such as ERR. The intent-aware approach estimates user satisfaction under a user behavior model. We show however that the underlying user behavior models is not realistic in the multilingual case, and the produced intent-aware metric do not appropriately estimate the user satisfaction. We develop a novel approach to build intent-aware user behavior models, which overcome these limitations and convert to quality metrics that better correlate with standard online metrics of user satisfaction.
* 7 pages, 1 figure, 3 tables
Prediction of Video Popularity in the Absence of Reliable Data from Video Hosting Services: Utility of Traces Left by Users on the Web
Nov 28, 2016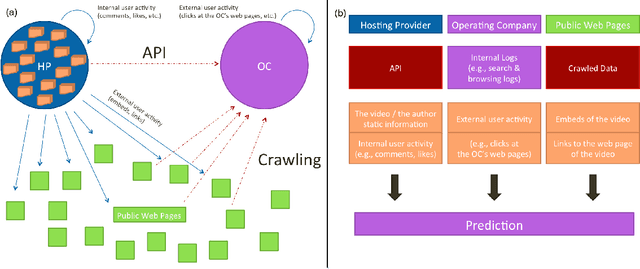
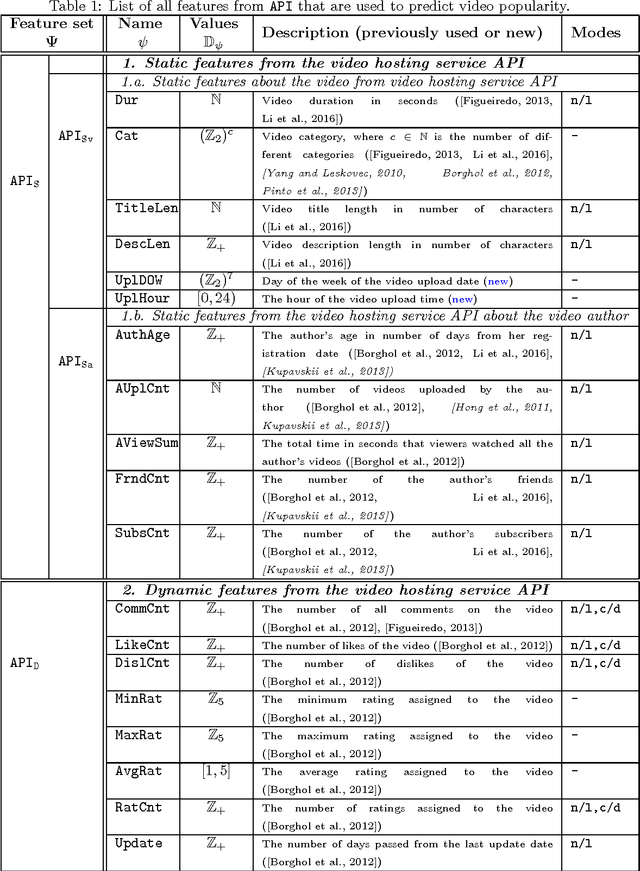
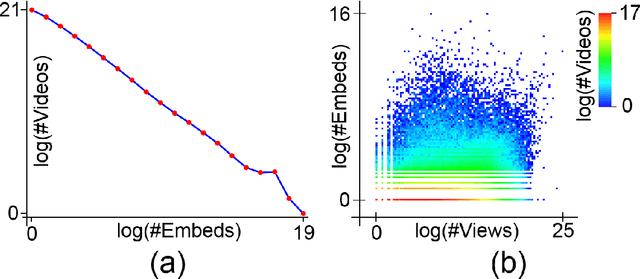
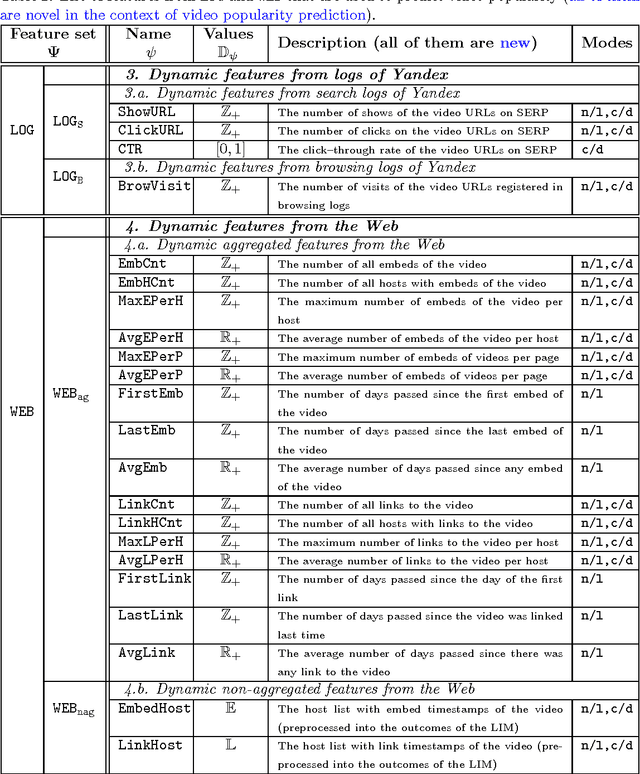
With the growth of user-generated content, we observe the constant rise of the number of companies, such as search engines, content aggregators, etc., that operate with tremendous amounts of web content not being the services hosting it. Thus, aiming to locate the most important content and promote it to the users, they face the need of estimating the current and predicting the future content popularity. In this paper, we approach the problem of video popularity prediction not from the side of a video hosting service, as done in all previous studies, but from the side of an operating company, which provides a popular video search service that aggregates content from different video hosting websites. We investigate video popularity prediction based on features from three primary sources available for a typical operating company: first, the content hosting provider may deliver its data via its API, second, the operating company makes use of its own search and browsing logs, third, the company crawls information about embeds of a video and links to a video page from publicly available resources on the Web. We show that video popularity prediction based on the embed and link data coupled with the internal search and browsing data significantly improves video popularity prediction based only on the data provided by the video hosting and can even adequately replace the API data in the cases when it is partly or completely unavailable.
Efficient Rectangular Maximal-Volume Algorithm for Rating Elicitation in Collaborative Filtering
Oct 16, 2016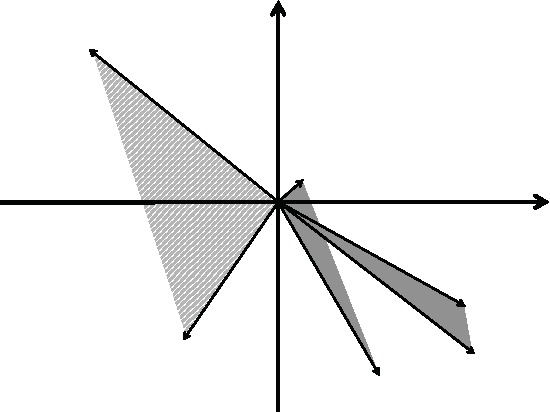
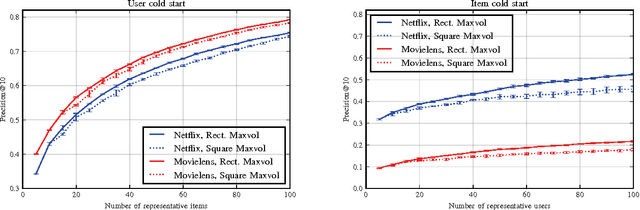


Cold start problem in Collaborative Filtering can be solved by asking new users to rate a small seed set of representative items or by asking representative users to rate a new item. The question is how to build a seed set that can give enough preference information for making good recommendations. One of the most successful approaches, called Representative Based Matrix Factorization, is based on Maxvol algorithm. Unfortunately, this approach has one important limitation --- a seed set of a particular size requires a rating matrix factorization of fixed rank that should coincide with that size. This is not necessarily optimal in the general case. In the current paper, we introduce a fast algorithm for an analytical generalization of this approach that we call Rectangular Maxvol. It allows the rank of factorization to be lower than the required size of the seed set. Moreover, the paper includes the theoretical analysis of the method's error, the complexity analysis of the existing methods and the comparison to the state-of-the-art approaches.