 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified View of Attention and Residual Sinks: Outlier-Driven Rescaling is Essential for Transformer Training
Jan 30, 2026We investigate the functional role of emergent outliers in large language models, specifically attention sinks (a few tokens that consistently receive large attention logits) and residual sinks (a few fixed dimensions with persistently large activations across most tokens). We hypothesize that these outliers, in conjunction with the corresponding normalizations (\textit{e.g.}, softmax attention and RMSNorm), effectively rescale other non-outlier components. We term this phenomenon \textit{outlier-driven rescaling} and validate this hypothesis across different model architectures and training token counts. This view unifies the origin and mitigation of both sink types. Our main conclusions and observations include: (1) Outliers function jointly with normalization: removing normalization eliminates the corresponding outliers but degrades training stability and performance; directly clipping outliers while retaining normalization leads to degradation, indicating that outlier-driven rescaling contributes to training stability. (2) Outliers serve more as rescale factors rather than contributors, as the final contributions of attention and residual sinks are significantly smaller than those of non-outliers. (3) Outliers can be absorbed into learnable parameters or mitigated via explicit gated rescaling, leading to improved training performance (average gain of 2 points) and enhanced quantization robustness (1.2 points degradation under W4A4 quantization).
Enhancing Long Document Long Form Summarisation with Self-Planning
Dec 19, 2025We introduce a novel approach for long context summarisation, highlight-guided generation, that leverages sentence-level information as a content plan to improve the traceability and faithfulness of generated summaries. Our framework applies self-planning methods to identify important content and then generates a summary conditioned on the plan. We explore both an end-to-end and two-stage variants of the approach, finding that the two-stage pipeline performs better on long and information-dense documents. Experiments on long-form summarisation datasets demonstrate that our method consistently improves factual consistency while preserving relevance and overall quality. On GovReport, our best approach has improved ROUGE-L by 4.1 points and achieves about 35% gains in SummaC scores. Qualitative analysis shows that highlight-guided summarisation helps preserve important details, leading to more accurate and insightful summaries across domains.
Clarification as Supervision: Reinforcement Learning for Vision-Language Interfaces
Sep 30, 2025
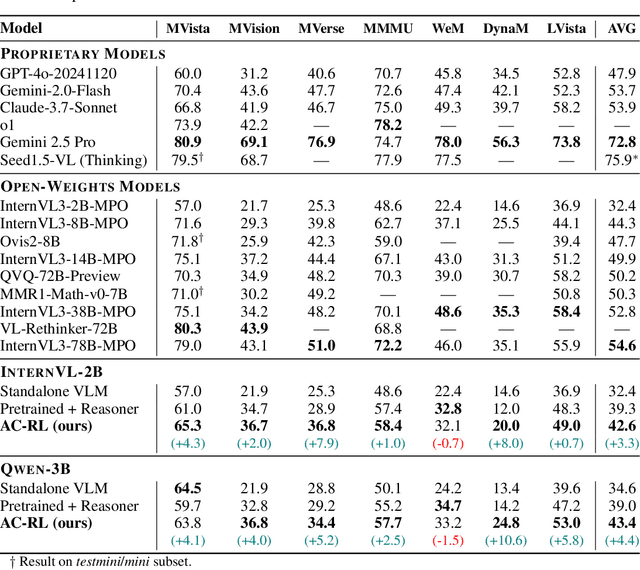

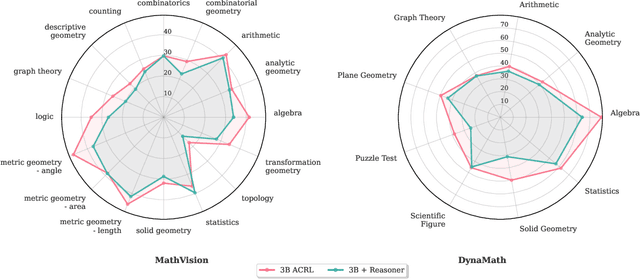
Recent text-only models demonstrate remarkable mathematical reasoning capabilities. Extending these to visual domains requires vision-language models to translate images into text descriptions. However, current models, trained to produce captions for human readers, often omit the precise details that reasoning systems require. This creates an interface mismatch: reasoners often fail not due to reasoning limitations but because they lack access to critical visual information. We propose Adaptive-Clarification Reinforcement Learning (AC-RL), which teaches vision models what information reasoners need through interaction. Our key insight is that clarification requests during training reveal information gaps; by penalizing success that requires clarification, we create pressure for comprehensive initial captions that enable the reasoner to solve the problem in a single pass. AC-RL improves average accuracy by 4.4 points over pretrained baselines across seven visual mathematical reasoning benchmarks, and analysis shows it would cut clarification requests by up to 39% if those were allowed. By treating clarification as a form of implicit supervision, AC-RL demonstrates that vision-language interfaces can be effectively learned through interaction alone, without requiring explicit annotations.
Blending Supervised and Reinforcement Fine-Tuning with Prefix Sampling
Jul 02, 2025Existing post-training techniques for large language models are broadly categorized into Supervised Fine-Tuning (SFT) and Reinforcement Fine-Tuning (RFT). Each paradigm presents a distinct trade-off: SFT excels at mimicking demonstration data but can lead to problematic generalization as a form of behavior cloning. Conversely, RFT can significantly enhance a model's performance but is prone to learn unexpected behaviors, and its performance is highly sensitive to the initial policy. In this paper, we propose a unified view of these methods and introduce Prefix-RFT, a hybrid approach that synergizes learning from both demonstration and exploration. Using mathematical reasoning problems as a testbed, we empirically demonstrate that Prefix-RFT is both simple and effective. It not only surpasses the performance of standalone SFT and RFT but also outperforms parallel mixed-policy RFT methods. A key advantage is its seamless integration into existing open-source frameworks, requiring only minimal modifications to the standard RFT pipeline. Our analysis highlights the complementary nature of SFT and RFT, and validates that Prefix-RFT effectively harmonizes these two learning paradigms. Furthermore, ablation studies confirm the method's robustness to variations in the quality and quantity of demonstration data. We hope this work offers a new perspective on LLM post-training, suggesting that a unified paradigm that judiciously integrates demonstration and exploration could be a promising direction for future research.
M-Wanda: Improving One-Shot Pruning for Multilingual LLMs
May 27, 2025



Multilingual LLM performance is often critically dependent on model size. With an eye on efficiency, this has led to a surge in interest in one-shot pruning methods that retain the benefits of large-scale pretraining while shrinking the model size. However, as pruning tends to come with performance loss, it is important to understand the trade-offs between multilinguality and sparsification. In this work, we study multilingual performance under different sparsity constraints and show that moderate ratios already substantially harm performance. To help bridge this gap, we propose M-Wanda, a pruning method that models cross-lingual variation by incorporating language-aware activation statistics into its pruning criterion and dynamically adjusts layerwise sparsity based on cross-lingual importance. We show that M-Wanda consistently improves performance at minimal additional costs. We are the first to explicitly optimize pruning to retain multilingual performance, and hope to inspire future advances in multilingual pruning.
Truthful or Fabricated? Using Causal Attribution to Mitigate Reward Hacking in Explanations
Apr 07, 2025



Chain-of-thought explanations are widely used to inspect the decision process of large language models (LLMs) and to evaluate the trustworthiness of model outputs, making them important for effective collaboration between LLMs and humans. We demonstrate that preference optimization - a key step in the alignment phase - can inadvertently reduce the faithfulness of these explanations. This occurs because the reward model (RM), which guides alignment, is tasked with optimizing both the expected quality of the response and the appropriateness of the explanations (e.g., minimizing bias or adhering to safety standards), creating potential conflicts. The RM lacks a mechanism to assess the consistency between the model's internal decision process and the generated explanation. Consequently, the LLM may engage in "reward hacking" by producing a final response that scores highly while giving an explanation tailored to maximize reward rather than accurately reflecting its reasoning. To address this issue, we propose enriching the RM's input with a causal attribution of the prediction, allowing the RM to detect discrepancies between the generated self-explanation and the model's decision process. In controlled settings, we show that this approach reduces the tendency of the LLM to generate misleading explanations.
Joint Localization and Activation Editing for Low-Resource Fine-Tuning
Feb 03, 2025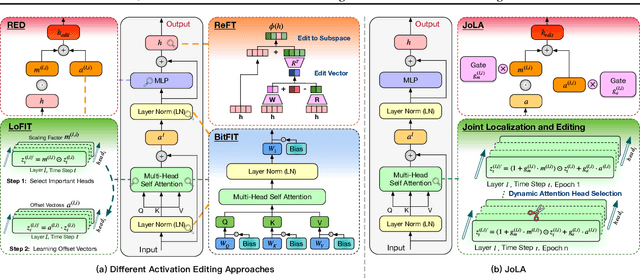
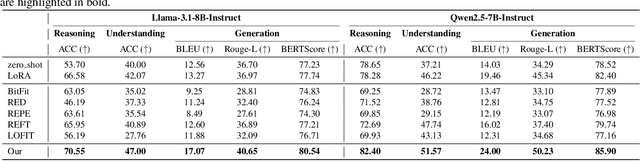
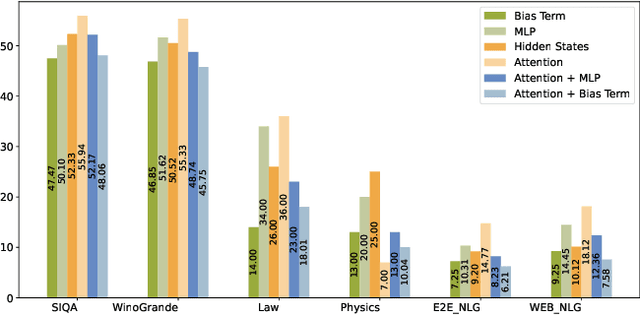
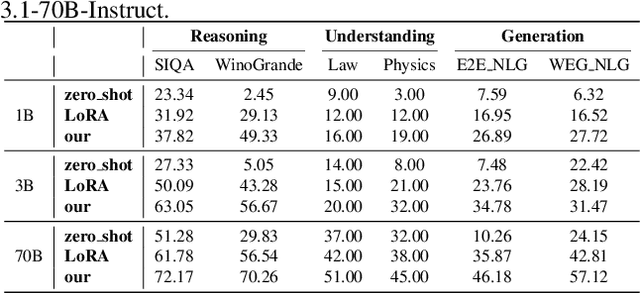
Parameter-efficient fine-tuning (PEFT) methods, such as LoRA, are commonly used to adapt LLMs. However, the effectiveness of standard PEFT methods is limited in low-resource scenarios with only a few hundred examples. Recent advances in interpretability research have inspired the emergence of activation editing techniques, which modify the activations of specific model components. These methods, due to their extremely small parameter counts, show promise for small datasets. However, their performance is highly dependent on identifying the correct modules to edit and often lacks stability across different datasets. In this paper, we propose Joint Localization and Activation Editing (JoLA), a method that jointly learns (1) which heads in the Transformer to edit (2) whether the intervention should be additive, multiplicative, or both and (3) the intervention parameters themselves - the vectors applied as additive offsets or multiplicative scalings to the head output. Through evaluations on three benchmarks spanning commonsense reasoning, natural language understanding, and natural language generation, we demonstrate that JoLA consistently outperforms existing methods.
Demons in the Detail: On Implementing Load Balancing Loss for Training Specialized Mixture-of-Expert Models
Jan 21, 2025
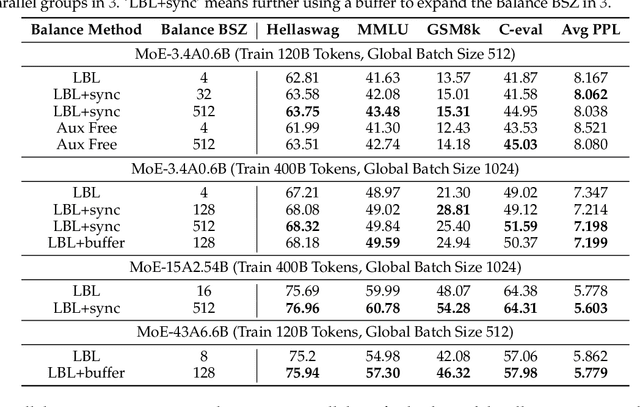
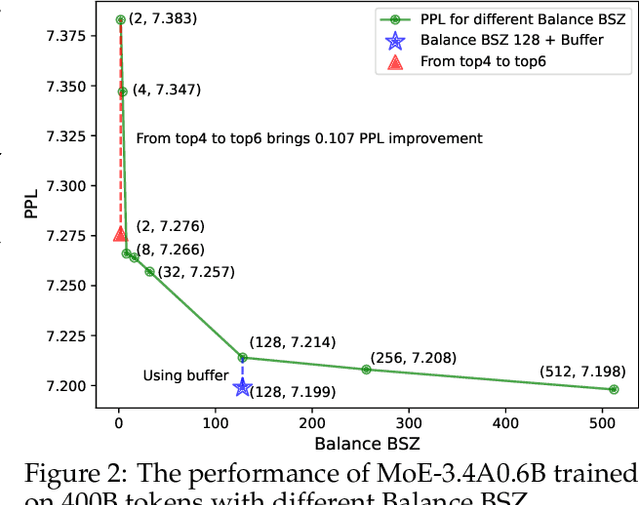
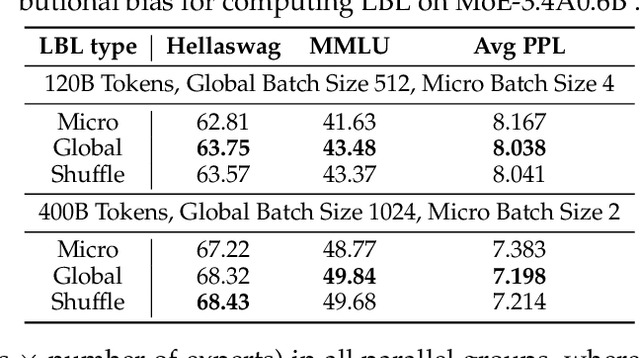
This paper revisits the implementation of $\textbf{L}$oad-$\textbf{b}$alancing $\textbf{L}$oss (LBL) when training Mixture-of-Experts (MoEs) models. Specifically, LBL for MoEs is defined as $N_E \sum_{i=1}^{N_E} f_i p_i$, where $N_E$ is the total number of experts, $f_i$ represents the frequency of expert $i$ being selected, and $p_i$ denotes the average gating score of the expert $i$. Existing MoE training frameworks usually employ the parallel training strategy so that $f_i$ and the LBL are calculated within a $\textbf{micro-batch}$ and then averaged across parallel groups. In essence, a micro-batch for training billion-scale LLMs normally contains very few sequences. So, the micro-batch LBL is almost at the sequence level, and the router is pushed to distribute the token evenly within each sequence. Under this strict constraint, even tokens from a domain-specific sequence ($\textit{e.g.}$, code) are uniformly routed to all experts, thereby inhibiting expert specialization. In this work, we propose calculating LBL using a $\textbf{global-batch}$ to loose this constraint. Because a global-batch contains much more diverse sequences than a micro-batch, which will encourage load balance at the corpus level. Specifically, we introduce an extra communication step to synchronize $f_i$ across micro-batches and then use it to calculate the LBL. Through experiments on training MoEs-based LLMs (up to $\textbf{42.8B}$ total parameters and $\textbf{400B}$ tokens), we surprisingly find that the global-batch LBL strategy yields excellent performance gains in both pre-training perplexity and downstream tasks. Our analysis reveals that the global-batch LBL also greatly improves the domain specialization of MoE experts.
Language Agents Meet Causality -- Bridging LLMs and Causal World Models
Oct 25, 2024Large Language Models (LLMs) have recently shown great promise in planning and reasoning applications. These tasks demand robust systems, which arguably require a causal understanding of the environment. While LLMs can acquire and reflect common sense causal knowledge from their pretraining data, this information is often incomplete, incorrect, or inapplicable to a specific environment. In contrast, causal representation learning (CRL) focuses on identifying the underlying causal structure within a given environment. We propose a framework that integrates CRLs with LLMs to enable causally-aware reasoning and planning. This framework learns a causal world model, with causal variables linked to natural language expressions. This mapping provides LLMs with a flexible interface to process and generate descriptions of actions and states in text form. Effectively, the causal world model acts as a simulator that the LLM can query and interact with. We evaluate the framework on causal inference and planning tasks across temporal scales and environmental complexities. Our experiments demonstrate the effectiveness of the approach, with the causally-aware method outperforming LLM-based reasoners, especially for longer planning horizons.
What's New in My Data? Novelty Exploration via Contrastive Generation
Oct 18, 2024Fine-tuning is widely used to adapt language models for specific goals, often leveraging real-world data such as patient records, customer-service interactions, or web content in languages not covered in pre-training. These datasets are typically massive, noisy, and often confidential, making their direct inspection challenging. However, understanding them is essential for guiding model deployment and informing decisions about data cleaning or suppressing any harmful behaviors learned during fine-tuning. In this study, we introduce the task of novelty discovery through generation, which aims to identify novel properties of a fine-tuning dataset by generating examples that illustrate these properties. Our approach, Contrastive Generative Exploration (CGE), assumes no direct access to the data but instead relies on a pre-trained model and the same model after fine-tuning. By contrasting the predictions of these two models, CGE can generate examples that highlight novel characteristics of the fine-tuning data. However, this simple approach may produce examples that are too similar to one another, failing to capture the full range of novel phenomena present in the dataset. We address this by introducing an iterative version of CGE, where the previously generated examples are used to update the pre-trained model, and this updated model is then contrasted with the fully fine-tuned model to generate the next example, promoting diversity in the generated outputs. Our experiments demonstrate the effectiveness of CGE in detecting novel content, such as toxic language, as well as new natural and programming languages. Furthermore, we show that CGE remains effective even when models are fine-tuned using differential privacy techniques.