 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemorization Inheritance in Sequence-Level Knowledge Distillation for Neural Machine Translation
Feb 03, 2025



In this work, we explore how instance-level memorization in the teacher Neural Machine Translation (NMT) model gets inherited by the student model in sequence-level knowledge distillation (SeqKD). We find that despite not directly seeing the original training data, students memorize more than baseline models (models of the same size, trained on the original data) -- 3.4% for exact matches and 57% for extractive memorization -- and show increased hallucination rates. Further, under this SeqKD setting, we also characterize how students behave on specific training data subgroups, such as subgroups with low quality and specific counterfactual memorization (CM) scores, and find that students exhibit amplified denoising on low-quality subgroups. Finally, we propose a modification to SeqKD named Adaptive-SeqKD, which intervenes in SeqKD to reduce memorization and hallucinations. Overall, we recommend caution when applying SeqKD: students inherit both their teachers' superior performance and their fault modes, thereby requiring active monitoring.
Generalisation First, Memorisation Second? Memorisation Localisation for Natural Language Classification Tasks
Aug 09, 2024Memorisation is a natural part of learning from real-world data: neural models pick up on atypical input-output combinations and store those training examples in their parameter space. That this happens is well-known, but how and where are questions that remain largely unanswered. Given a multi-layered neural model, where does memorisation occur in the millions of parameters? Related work reports conflicting findings: a dominant hypothesis based on image classification is that lower layers learn generalisable features and that deeper layers specialise and memorise. Work from NLP suggests this does not apply to language models, but has been mainly focused on memorisation of facts. We expand the scope of the localisation question to 12 natural language classification tasks and apply 4 memorisation localisation techniques. Our results indicate that memorisation is a gradual process rather than a localised one, establish that memorisation is task-dependent, and give nuance to the generalisation first, memorisation second hypothesis.
Evaluating Subword Tokenization: Alien Subword Composition and OOV Generalization Challenge
Apr 20, 2024



The popular subword tokenizers of current language models, such as Byte-Pair Encoding (BPE), are known not to respect morpheme boundaries, which affects the downstream performance of the models. While many improved tokenization algorithms have been proposed, their evaluation and cross-comparison is still an open problem. As a solution, we propose a combined intrinsic-extrinsic evaluation framework for subword tokenization. Intrinsic evaluation is based on our new UniMorph Labeller tool that classifies subword tokenization as either morphological or alien. Extrinsic evaluation, in turn, is performed via the Out-of-Vocabulary Generalization Challenge 1.0 benchmark, which consists of three newly specified downstream text classification tasks. Our empirical findings show that the accuracy of UniMorph Labeller is 98%, and that, in all language models studied (including ALBERT, BERT, RoBERTa, and DeBERTa), alien tokenization leads to poorer generalizations compared to morphological tokenization for semantic compositionality of word meanings.
Latent Feature-based Data Splits to Improve Generalisation Evaluation: A Hate Speech Detection Case Study
Nov 16, 2023



With the ever-growing presence of social media platforms comes the increased spread of harmful content and the need for robust hate speech detection systems. Such systems easily overfit to specific targets and keywords, and evaluating them without considering distribution shifts that might occur between train and test data overestimates their benefit. We challenge hate speech models via new train-test splits of existing datasets that rely on the clustering of models' hidden representations. We present two split variants (Subset-Sum-Split and Closest-Split) that, when applied to two datasets using four pretrained models, reveal how models catastrophically fail on blind spots in the latent space. This result generalises when developing a split with one model and evaluating it on another. Our analysis suggests that there is no clear surface-level property of the data split that correlates with the decreased performance, which underscores that task difficulty is not always humanly interpretable. We recommend incorporating latent feature-based splits in model development and release two splits via the GenBench benchmark.
Memorisation Cartography: Mapping out the Memorisation-Generalisation Continuum in Neural Machine Translation
Nov 09, 2023



When training a neural network, it will quickly memorise some source-target mappings from your dataset but never learn some others. Yet, memorisation is not easily expressed as a binary feature that is good or bad: individual datapoints lie on a memorisation-generalisation continuum. What determines a datapoint's position on that spectrum, and how does that spectrum influence neural models' performance? We address these two questions for neural machine translation (NMT) models. We use the counterfactual memorisation metric to (1) build a resource that places 5M NMT datapoints on a memorisation-generalisation map, (2) illustrate how the datapoints' surface-level characteristics and a models' per-datum training signals are predictive of memorisation in NMT, (3) and describe the influence that subsets of that map have on NMT systems' performance.
Non-Compositionality in Sentiment: New Data and Analyses
Oct 31, 2023When natural language phrases are combined, their meaning is often more than the sum of their parts. In the context of NLP tasks such as sentiment analysis, where the meaning of a phrase is its sentiment, that still applies. Many NLP studies on sentiment analysis, however, focus on the fact that sentiment computations are largely compositional. We, instead, set out to obtain non-compositionality ratings for phrases with respect to their sentiment. Our contributions are as follows: a) a methodology for obtaining those non-compositionality ratings, b) a resource of ratings for 259 phrases -- NonCompSST -- along with an analysis of that resource, and c) an evaluation of computational models for sentiment analysis using this new resource.
Recursive Neural Networks with Bottlenecks Diagnose (Non-)Compositionality
Jan 31, 2023A recent line of work in NLP focuses on the (dis)ability of models to generalise compositionally for artificial languages. However, when considering natural language tasks, the data involved is not strictly, or locally, compositional. Quantifying the compositionality of data is a challenging task, which has been investigated primarily for short utterances. We use recursive neural models (Tree-LSTMs) with bottlenecks that limit the transfer of information between nodes. We illustrate that comparing data's representations in models with and without the bottleneck can be used to produce a compositionality metric. The procedure is applied to the evaluation of arithmetic expressions using synthetic data, and sentiment classification using natural language data. We demonstrate that compression through a bottleneck impacts non-compositional examples disproportionately and then use the bottleneck compositionality metric (BCM) to distinguish compositional from non-compositional samples, yielding a compositionality ranking over a dataset.
State-of-the-art generalisation research in NLP: a taxonomy and review
Oct 10, 2022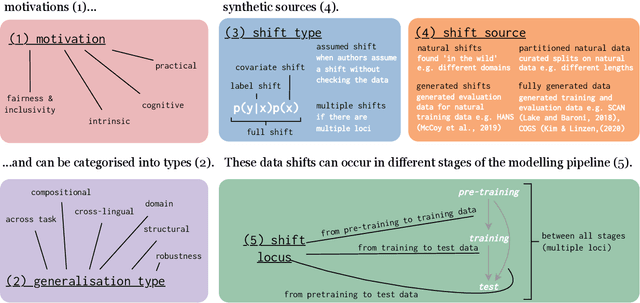
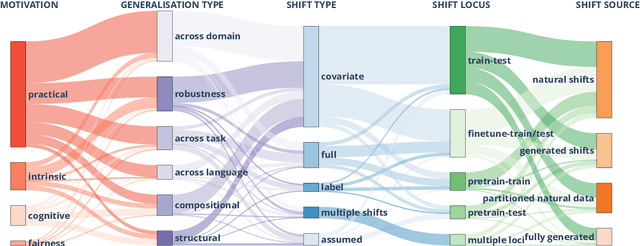
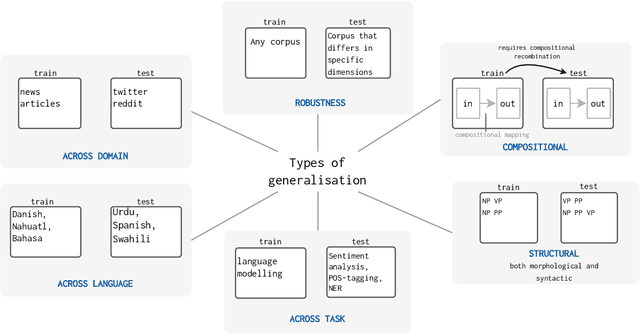

The ability to generalise well is one of the primary desiderata of natural language processing (NLP). Yet, what `good generalisation' entails and how it should be evaluated is not well understood, nor are there any common standards to evaluate it. In this paper, we aim to lay the ground-work to improve both of these issues. We present a taxonomy for characterising and understanding generalisation research in NLP, we use that taxonomy to present a comprehensive map of published generalisation studies, and we make recommendations for which areas might deserve attention in the future. Our taxonomy is based on an extensive literature review of generalisation research, and contains five axes along which studies can differ: their main motivation, the type of generalisation they aim to solve, the type of data shift they consider, the source by which this data shift is obtained, and the locus of the shift within the modelling pipeline. We use our taxonomy to classify over 400 previous papers that test generalisation, for a total of more than 600 individual experiments. Considering the results of this review, we present an in-depth analysis of the current state of generalisation research in NLP, and make recommendations for the future. Along with this paper, we release a webpage where the results of our review can be dynamically explored, and which we intend to up-date as new NLP generalisation studies are published. With this work, we aim to make steps towards making state-of-the-art generalisation testing the new status quo in NLP.
Text Characterization Toolkit
Oct 04, 2022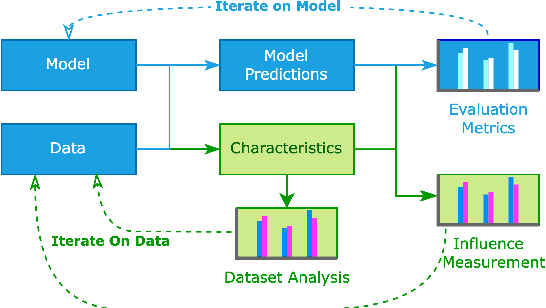
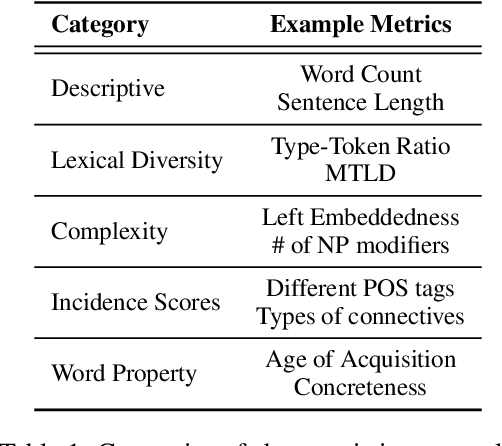
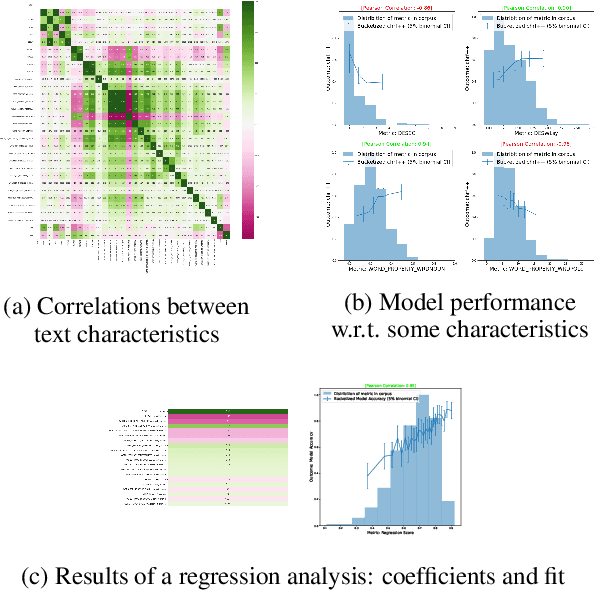
In NLP, models are usually evaluated by reporting single-number performance scores on a number of readily available benchmarks, without much deeper analysis. Here, we argue that - especially given the well-known fact that benchmarks often contain biases, artefacts, and spurious correlations - deeper results analysis should become the de-facto standard when presenting new models or benchmarks. We present a tool that researchers can use to study properties of the dataset and the influence of those properties on their models' behaviour. Our Text Characterization Toolkit includes both an easy-to-use annotation tool, as well as off-the-shelf scripts that can be used for specific analyses. We also present use-cases from three different domains: we use the tool to predict what are difficult examples for given well-known trained models and identify (potentially harmful) biases and heuristics that are present in a dataset.
Can Transformer be Too Compositional? Analysing Idiom Processing in Neural Machine Translation
May 30, 2022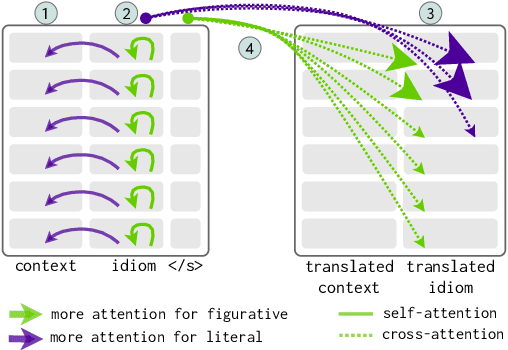
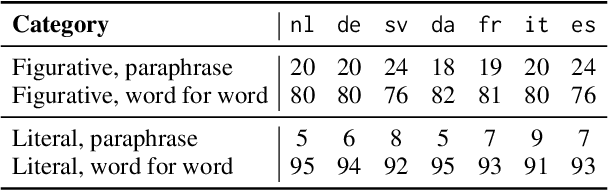
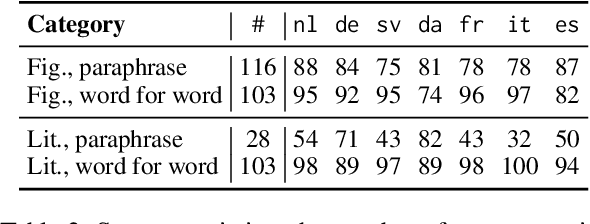
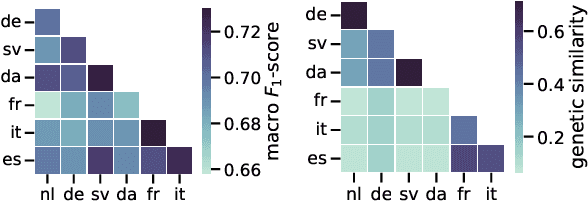
Unlike literal expressions, idioms' meanings do not directly follow from their parts, posing a challenge for neural machine translation (NMT). NMT models are often unable to translate idioms accurately and over-generate compositional, literal translations. In this work, we investigate whether the non-compositionality of idioms is reflected in the mechanics of the dominant NMT model, Transformer, by analysing the hidden states and attention patterns for models with English as source language and one of seven European languages as target language. When Transformer emits a non-literal translation - i.e. identifies the expression as idiomatic - the encoder processes idioms more strongly as single lexical units compared to literal expressions. This manifests in idioms' parts being grouped through attention and in reduced interaction between idioms and their context. In the decoder's cross-attention, figurative inputs result in reduced attention on source-side tokens. These results suggest that Transformer's tendency to process idioms as compositional expressions contributes to literal translations of idioms.