 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Counterfactual Simulations with Language Models for Explaining Multi-Agent Behaviour
May 23, 2025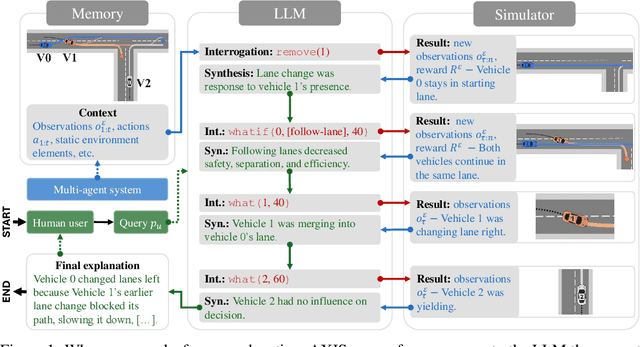

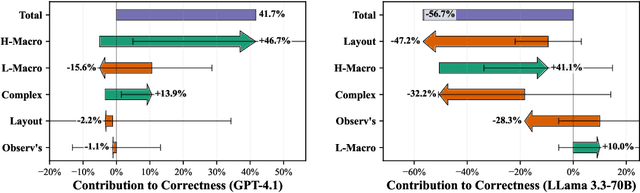
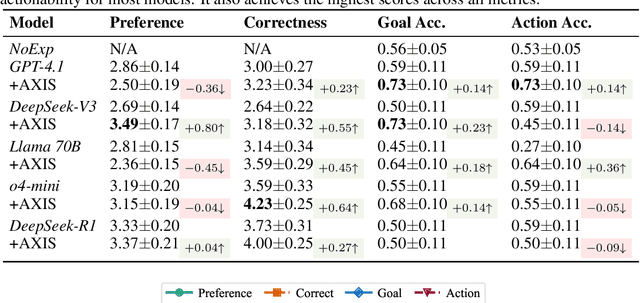
Autonomous multi-agent systems (MAS) are useful for automating complex tasks but raise trust concerns due to risks like miscoordination and goal misalignment. Explainability is vital for trust calibration, but explainable reinforcement learning for MAS faces challenges in state/action space complexity, stakeholder needs, and evaluation. Using the counterfactual theory of causation and LLMs' summarisation capabilities, we propose Agentic eXplanations via Interrogative Simulation (AXIS). AXIS generates intelligible causal explanations for pre-trained multi-agent policies by having an LLM interrogate an environment simulator using queries like 'whatif' and 'remove' to observe and synthesise counterfactual information over multiple rounds. We evaluate AXIS on autonomous driving across 10 scenarios for 5 LLMs with a novel evaluation methodology combining subjective preference, correctness, and goal/action prediction metrics, and an external LLM as evaluator. Compared to baselines, AXIS improves perceived explanation correctness by at least 7.7% across all models and goal prediction accuracy by 23% for 4 models, with improved or comparable action prediction accuracy, achieving the highest scores overall.
Partner Modelling Emerges in Recurrent Agents (But Only When It Matters)
May 22, 2025Humans are remarkably adept at collaboration, able to infer the strengths and weaknesses of new partners in order to work successfully towards shared goals. To build AI systems with this capability, we must first understand its building blocks: does such flexibility require explicit, dedicated mechanisms for modelling others -- or can it emerge spontaneously from the pressures of open-ended cooperative interaction? To investigate this question, we train simple model-free RNN agents to collaborate with a population of diverse partners. Using the `Overcooked-AI' environment, we collect data from thousands of collaborative teams, and analyse agents' internal hidden states. Despite a lack of additional architectural features, inductive biases, or auxiliary objectives, the agents nevertheless develop structured internal representations of their partners' task abilities, enabling rapid adaptation and generalisation to novel collaborators. We investigated these internal models through probing techniques, and large-scale behavioural analysis. Notably, we find that structured partner modelling emerges when agents can influence partner behaviour by controlling task allocation. Our results show that partner modelling can arise spontaneously in model-free agents -- but only under environmental conditions that impose the right kind of social pressure.
Predicting Multi-Agent Specialization via Task Parallelizability
Mar 19, 2025Multi-agent systems often rely on specialized agents with distinct roles rather than general-purpose agents that perform the entire task independently. However, the conditions that govern the optimal degree of specialization remain poorly understood. In this work, we propose that specialist teams outperform generalist ones when environmental constraints limit task parallelizability -- the potential to execute task components concurrently. Drawing inspiration from distributed systems, we introduce a heuristic to predict the relative efficiency of generalist versus specialist teams by estimating the speed-up achieved when two agents perform a task in parallel rather than focus on complementary subtasks. We validate this heuristic through three multi-agent reinforcement learning (MARL) experiments in Overcooked-AI, demonstrating that key factors limiting task parallelizability influence specialization. We also observe that as the state space expands, agents tend to converge on specialist strategies, even when generalist ones are theoretically more efficient, highlighting potential biases in MARL training algorithms. Our findings provide a principled framework for interpreting specialization given the task and environment, and introduce a novel benchmark for evaluating whether MARL finds optimal strategies.
Studying the Interplay Between the Actor and Critic Representations in Reinforcement Learning
Mar 08, 2025

Extracting relevant information from a stream of high-dimensional observations is a central challenge for deep reinforcement learning agents. Actor-critic algorithms add further complexity to this challenge, as it is often unclear whether the same information will be relevant to both the actor and the critic. To this end, we here explore the principles that underlie effective representations for the actor and for the critic in on-policy algorithms. We focus our study on understanding whether the actor and critic will benefit from separate, rather than shared, representations. Our primary finding is that when separated, the representations for the actor and critic systematically specialise in extracting different types of information from the environment -- the actor's representation tends to focus on action-relevant information, while the critic's representation specialises in encoding value and dynamics information. We conduct a rigourous empirical study to understand how different representation learning approaches affect the actor and critic's specialisations and their downstream performance, in terms of sample efficiency and generation capabilities. Finally, we discover that a separated critic plays an important role in exploration and data collection during training. Our code, trained models and data are accessible at https://github.com/francelico/deac-rep.
ICED: Zero-Shot Transfer in Reinforcement Learning via In-Context Environment Design
Feb 05, 2024Autonomous agents trained using deep reinforcement learning (RL) often lack the ability to successfully generalise to new environments, even when they share characteristics with the environments they have encountered during training. In this work, we investigate how the sampling of individual environment instances, or levels, affects the zero-shot generalisation (ZSG) ability of RL agents. We discover that, for deep actor-critic architectures sharing their base layers, prioritising levels according to their value loss minimises the mutual information between the agent's internal representation and the set of training levels in the generated training data. This provides a novel theoretical justification for the implicit regularisation achieved by certain adaptive sampling strategies. We then turn our attention to unsupervised environment design (UED) methods, which have more control over the data generation mechanism. We find that existing UED methods can significantly shift the training distribution, which translates to low ZSG performance. To prevent both overfitting and distributional shift, we introduce in-context environment design (ICED). ICED generates levels using a variational autoencoder trained over an initial set of level parameters, reducing distributional shift, and achieves significant improvements in ZSG over adaptive level sampling strategies and UED methods.
Data-driven Prior Learning for Bayesian Optimisation
Nov 24, 2023Transfer learning for Bayesian optimisation has generally assumed a strong similarity between optimisation tasks, with at least a subset having similar optimal inputs. This assumption can reduce computational costs, but it is violated in a wide range of optimisation problems where transfer learning may nonetheless be useful. We replace this assumption with a weaker one only requiring the shape of the optimisation landscape to be similar, and analyse the recent method Prior Learning for Bayesian Optimisation - PLeBO - in this setting. By learning priors for the hyperparameters of the Gaussian process surrogate model we can better approximate the underlying function, especially for few function evaluations. We validate the learned priors and compare to a breadth of transfer learning approaches, using synthetic data and a recent air pollution optimisation problem as benchmarks. We show that PLeBO and prior transfer find good inputs in fewer evaluations.
Non-Compositionality in Sentiment: New Data and Analyses
Oct 31, 2023When natural language phrases are combined, their meaning is often more than the sum of their parts. In the context of NLP tasks such as sentiment analysis, where the meaning of a phrase is its sentiment, that still applies. Many NLP studies on sentiment analysis, however, focus on the fact that sentiment computations are largely compositional. We, instead, set out to obtain non-compositionality ratings for phrases with respect to their sentiment. Our contributions are as follows: a) a methodology for obtaining those non-compositionality ratings, b) a resource of ratings for 259 phrases -- NonCompSST -- along with an analysis of that resource, and c) an evaluation of computational models for sentiment analysis using this new resource.
Balancing utility and cognitive cost in social representation
Oct 07, 2023


To successfully navigate its environment, an agent must construct and maintain representations of the other agents that it encounters. Such representations are useful for many tasks, but they are not without cost. As a result, agents must make decisions regarding how much information they choose to represent about the agents in their environment. Using selective imitation as an example task, we motivate the problem of finding agent representations that optimally trade off between downstream utility and information cost, and illustrate two example approaches to resource-constrained social representation.
How the level sampling process impacts zero-shot generalisation in deep reinforcement learning
Oct 05, 2023



A key limitation preventing the wider adoption of autonomous agents trained via deep reinforcement learning (RL) is their limited ability to generalise to new environments, even when these share similar characteristics with environments encountered during training. In this work, we investigate how a non-uniform sampling strategy of individual environment instances, or levels, affects the zero-shot generalisation (ZSG) ability of RL agents, considering two failure modes: overfitting and over-generalisation. As a first step, we measure the mutual information (MI) between the agent's internal representation and the set of training levels, which we find to be well-correlated to instance overfitting. In contrast to uniform sampling, adaptive sampling strategies prioritising levels based on their value loss are more effective at maintaining lower MI, which provides a novel theoretical justification for this class of techniques. We then turn our attention to unsupervised environment design (UED) methods, which adaptively generate new training levels and minimise MI more effectively than methods sampling from a fixed set. However, we find UED methods significantly shift the training distribution, resulting in over-generalisation and worse ZSG performance over the distribution of interest. To prevent both instance overfitting and over-generalisation, we introduce self-supervised environment design (SSED). SSED generates levels using a variational autoencoder, effectively reducing MI while minimising the shift with the distribution of interest, and leads to statistically significant improvements in ZSG over fixed-set level sampling strategies and UED methods.
DreamDecompiler: Improved Bayesian Program Learning by Decompiling Amortised Knowledge
Jun 13, 2023Solving program induction problems requires searching through an enormous space of possibilities. DreamCoder is an inductive program synthesis system that, whilst solving problems, learns to simplify search in an iterative wake-sleep procedure. The cost of search is amortised by training a neural search policy, reducing search breadth and effectively "compiling" useful information to compose program solutions across tasks. Additionally, a library of program components is learnt to express discovered solutions in fewer components, reducing search depth. In DreamCoder, the neural search policy has only an indirect effect on the library learnt through the program solutions it helps discover. We present an approach for library learning that directly leverages the neural search policy, effectively "decompiling" its amortised knowledge to extract relevant program components. This provides stronger amortised inference: the amortised knowledge learnt to reduce search breadth is now also used to reduce search depth. We integrate our approach with DreamCoder and demonstrate faster domain proficiency with improved generalisation on a range of domains, particularly when fewer example solutions are available.